
AIxiv 是一个在机器核心发布学术和技术内容的专栏。在过去的几年里,AI xiv 栏目收到了 2000 多篇报告,覆盖了全球各大高校和企业的顶级实验室,有效促进了学术交流和传播。如果您有出色的工作要分享,请随时提交或联系我们。提交 email:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
随着人工智能技术的快速发展,大型语言模型 (LLM) 在自然语言处理、计算机视觉和科学任务等领域取得了重大进展。然而,随着模型的扩展,在保持高性能的同时优化资源消耗成为一项关键挑战。为了应对这一挑战,腾讯的 Hybrid 团队率先采用了 Hybrid Expert (MoE) 模型架构,最新发布的 Hunyuan-Large (Hunyuan-MoE-A52B) 模型是业界开源的最大基于 Transformer 的 MoE 模型,总参数为 389B ,激活参数为 52B。
此次腾讯 Hybrid - Large 共有 Hunyuan-A52B-Pretrain、Hunyuan-A52B-Instruct 和 Hunyuan-A52B-FP8 三种开源模型,可以支持企业和开发者在微调、部署等不同场景下的使用需求,并且可以直接从 HuggingFace、Github 等技术社区下载,可以免费和商业使用。通过技术优化,腾讯 Hybrid Large 适应了开源框架的微调和部署,具有很强的实用性。腾讯云的 TI 平台和高性能应用服务 HAI 也已开放接入,提供模型微调、API 调用、私有化部署一站式服务。

浑源-整体模型效应大
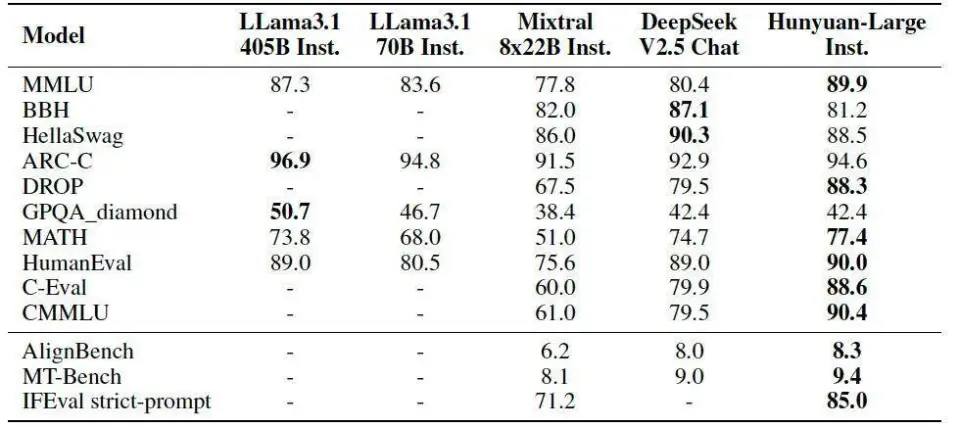
根据公开评测结果,腾讯 Hybrid Large 在 CMMLU、MMLU、CEval、MATH 等多学科综合评价集,以及中英文 NLP 任务、代码、数学九大维度上领先,超越了 Llama 3.1、Mictral 等一流开源模型。
技术创新要点
MoE(Mix of Experts),即混合专家模型,MoE 模型的每一层都包含多个并行的同质专家,一个 Token 的正向计算只会激活一部分 EA。MoE 模型的每一层都使用路由算法来确定哪些专家将处理代币。MoE 是一种稀疏网络结构,其性能优于激活具有相同参数总数的相同大小的密集模型,但推理成本远低于相同参数总数的密集模型。
得益于 Mix of Experts (MoE) 结构的优越性,Mix Large 可以在保证模型推理速度的同时,显著增加模型的参数数量,提高模型的性能。
1. 路线和训练策略
在腾讯混元大的专家层中,设置了一个共享专家来捕获所有代币需要的共识,还设置了 16 个需要路由的专家,模型将每个代币路由到激活分数最高的专家,动态学习特定领域的知识, 并通过随机补偿路由保证训练的稳定性。共享专家负责处理共享的通用能力和知识,特殊专家负责处理与任务相关的特殊能力,动态激活的专家使用稀疏神经网络进行高效推理。
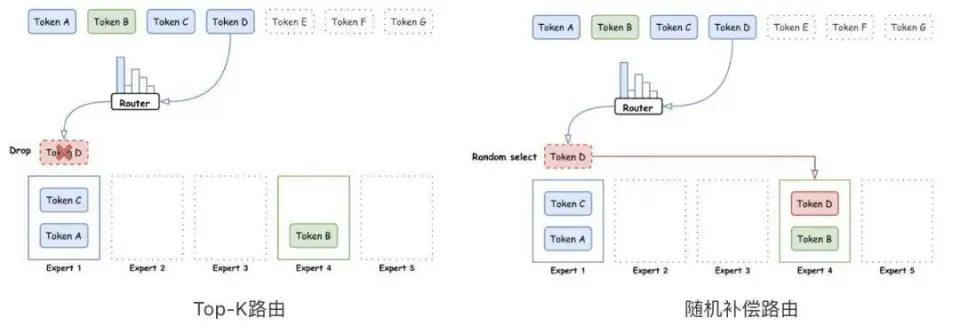
路由策略,即向 MoE 中的各种专家分发代币的策略,是 MoE 模型的关键部分。一个好的路由策略可以有效地激活每个 Expert 的能力,使每个 Expert 都能保持相对均衡的负载,同时提高模型的训练稳定性和收敛速度。业内常用的一种路由策略是 top-K 路由,即每个 Token 都根据其与 expert 的激活分数路由到每个 expert。但是,这种路由方式很难保证 Token 在 Expert 之间均匀分配,那些超过 expert 负载的 token 会被直接丢弃,不会参与 expert 层的计算。这将导致一些处理较少代币的专家的培训不稳定。
为了解决这个问题,腾讯 Mixed Element Large 在传统 Top-K 路由的基础上,进一步提出了一种随机补偿路由方式。
在 Hunyuan-A52B 中,共享 EA 和路由 EA 在每次迭代中处理的 Token 数量差异很大,这会导致每个 EA 的实际 batchsize 不一致(共享 EA 的 batchsize 是其他 EA 的 16 倍),根据学习率和 batch size 的缩放原则, 不同的(共享/特殊)专家适应不同的最优学习率,以提高模型的训练效率。
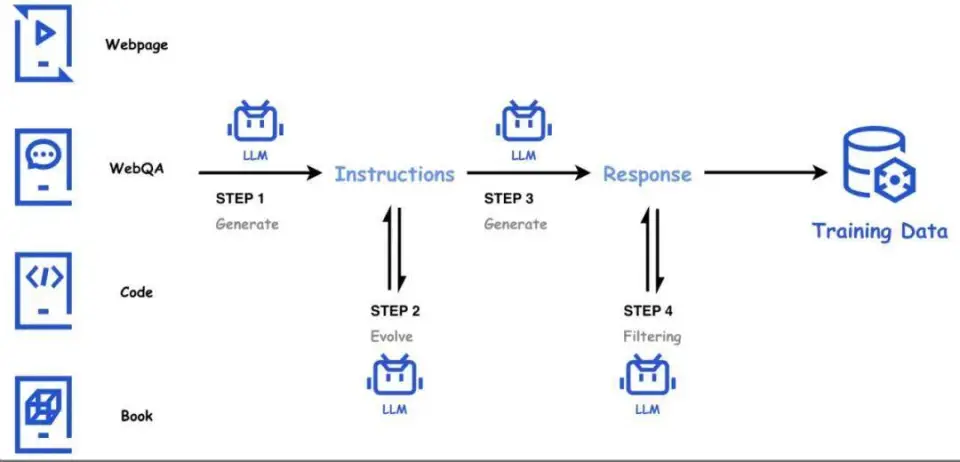
大型语言模型的成功与高质量的训练数据密不可分。公共 Web 数据的质量往往参差不齐,而且往往难以获得高质量;腾讯 MixElement 团队在自然文本语料的基础上,利用内部的一系列大型语言模型,构建了大量高质量、多样、高难度的合成数据,并通过模型驱动的自动化方法进行评估、筛选、持续维护数据质量,形成了完整的数据采集、筛选、优化、质检、 和综合。
在数学领域,很难在 Web 数据中找到大量高质量的思维链 (CoT) 数据。腾讯混元大从网页中挖掘构建了大规模的题库,并以此为种子,合成了数学问答,从而保证了多样性。同时,我们使用一致性模型和评价模型来保持数据的质量,从而获得大量高质量和多样化的数学数据。通过添加数学综合数据,模型的数学能力得到了显著提高。
在代码世界中,许多自然代码的质量很差,并且包含类似于代码解释的代码-文本映射的数据很少。因此,腾讯 Mixelement Large 使用大量来自自然代码库的代码片段作为种子,合成了大量包含富文本代码映射的高质量代码训练数据,大大提高了模型的代码生成能力。
对于通用网页中资源含量低、教育程度高的数据,腾讯 Hybrid Large 采用综合方法对数据进行转换和扩充,构建了大量多样、形式多样、风格各异、质量高的合成数据,提升了模型的通用字段效果。
2. 长文能力的优化
采用高效的超长文本注意力训练和退火策略。通过混合长文本和普通文本的训练,分多个阶段逐步引入自动构建构建的海量长文本合成数据,每个阶段只需要少量的长文本数据,即可获得更好的模型泛化和外推能力。
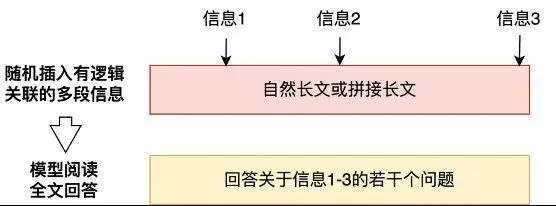
腾讯混元大模型特别改进的长文本能力,已经应用到腾讯的AI助手腾讯元宝上,最大支持256K的上下文,相当于一部《三国演义》或《哈利波特》全集英文原版的长度,一次最多可以处理上传10个文档, 并且可以一次性解析多个微信公众号链接和 URL,使腾讯元宝具有独特的深度分析能力。
3. 推理加速优化
随着 LLM 处理序列的增长,Key-Value Cache 会消耗过多的内存,从而对推理成本和速度构成挑战。
为了提高推理效率,腾讯 Hybrid 团队使用了 GQA 和跨层注意力 (CLA) 两种策略来压缩 KV 缓存。同时引入定量技术,进一步提高压缩比。
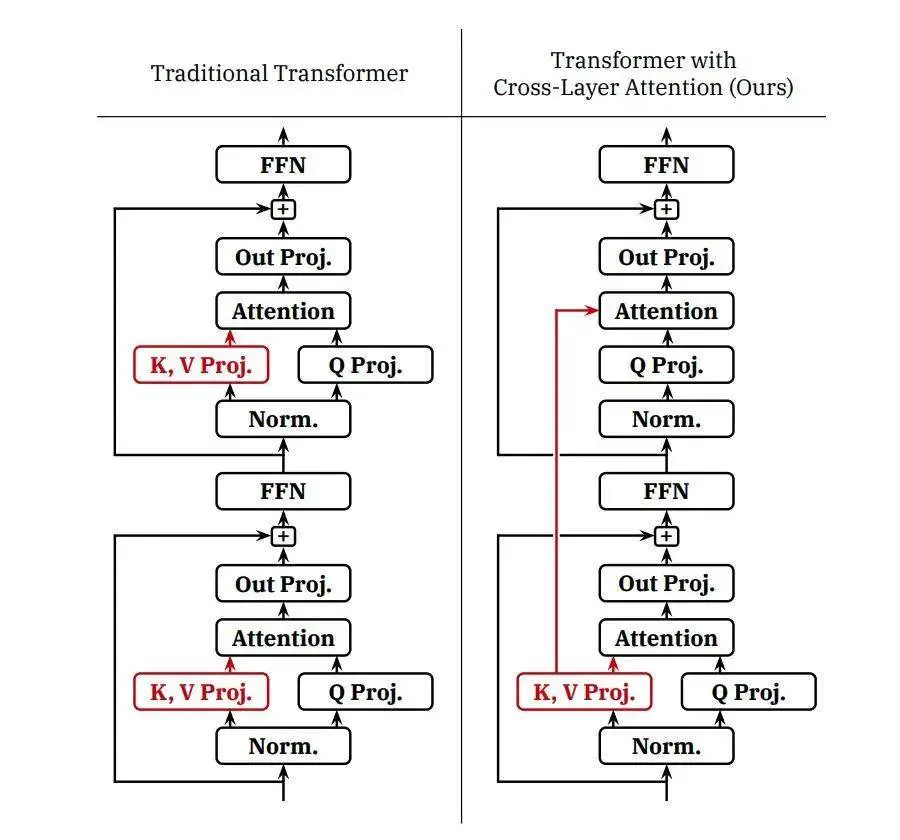
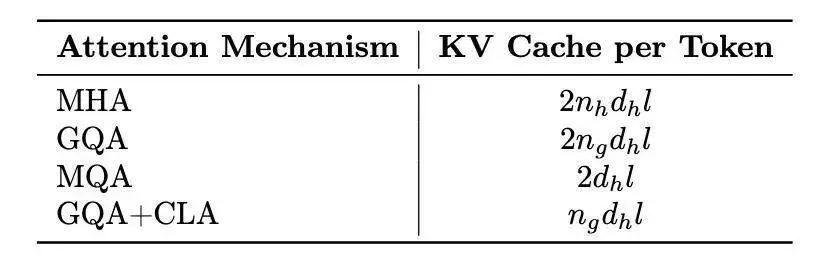
随着 GQA+CLA 的引入,我们将 Hunyuan-A52B 模型的 head 数从 80 个压缩到 8 个,并通过 CLA 每两层共享 KV 激活值,最终将模型的 KV 缓存压缩到 MHA 的 5%,大大提高了推理性能。以下是不同策略的 KV Cache 的比较。
4. Postrain 优化
基于预训练模型,腾讯 Hybrid 团队使用了超过 100 万级的 SFT 数据进行微调训练,包括数学、代码、逻辑、文本创建、文本理解、知识测验、角色扮演、工具使用等类别。为了保证进入 SFT 训练的数据质量,我们基于规则和模型判别构建了一整套数据质量检查管道,用于查找常见的 markdown 格式错误、数据截断、数据重复和数据中的乱码数据。此外,为了从大规模教学数据中自动过滤出高质量的SFT数据,我们基于Hunyuan-70B模型训练了一个Critique模型,该模型可以对4个等级的指令数据进行评分,一方面可以自动过滤低质量数据,在自我进化迭代过程中有效提高所选响应的质量。
我们使用 32k 长度进行 SFT 训练,为了防止训练过程中的过度拟合,我们开启了 0.1 注意力缺失和 0.2 隐藏缺失;我们发现,与 Dense 模型相比,具有 MoE 架构的模型可以通过实现合理的 dropout 来有效提高下游任务评估的性能。此外,为了更高效地利用大规模教学数据,我们对教学数据的质量进行了分级,并通过由粗到细的阶段性训练,有效提高了模型效果。
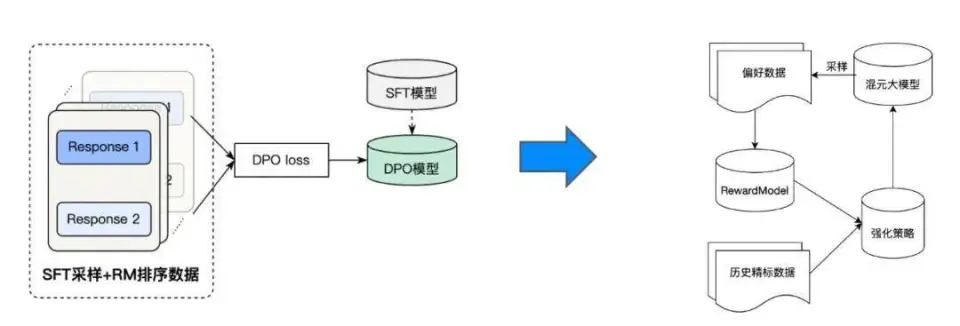
为了使模型生成接近人类偏好的响应,我们进一步使用直接偏好优化 (DPO) 对齐算法来密集训练 SFT 模型。与离线 DPO 算法不同,我们在强化学习的第二阶段使用了在线强化管道,在训练过程中,它使用固定对数据的离线 DPO 策略和使用更新策略模型的迭代采样的在线强化策略进行了集成。具体来说,每轮模型只使用少量数据进行采样训练,经过一轮训练后,模型会从新的一批数据中抽取多个响应,然后使用奖励模型 (RM) 进行评分,并整理出最好和最差的响应,以构建偏好对。
为了进一步增强强化学习阶段的训练稳定性,我们随机选择了一定比例的 SFT 数据来计算 sft loss,因为这部分数据在 SFT 阶段已经学习过,DPO 阶段加上 sft loss 是为了保持模型的语言能力, 并且系数很小。此外,为了增加在 DPO 对数据中生成好答案的概率,并通过同时降低好答案和坏答案的概率来防止 DPO 走捷径,我们还在考虑添加所选的好答案损失。通过上述策略的有效结合,我们的模型在 RLHF 训练后的有效性得到了显著提高。
5. 训练和微调
腾讯 Hybrid Large 模型由腾讯 Fulllink 开发,其训练和推理基于腾讯的 Angel 机器学习平台。
为解决 MoE 模型的 All2all 通信效率问题,Angel Training Acceleration Framework (AngelPTM) 实现了专家计算和通信级重叠优化、MOE 算子融合优化和低精度训练优化等,性能是 DeepSpeed 开源框架的 2.6 倍。
开源的 Angel 推理加速框架 (AngelHCF-vLLM) 由腾讯 Angel 机器学习平台和腾讯云智能联合开发。基于 vLLM 开源框架,适配混合大模型,不断叠加 NF4 和 FP8 的量化和并行解码优化,节省显存 50% 以上,吞吐量相比 BF16 提高 1 倍以上。此外,Angel 推理加速框架还支持 TensorRT-LLM 后端,在目前的基础上进一步提升了 30% 的推理性能,目前在腾讯内部广泛使用,近期也将推出相应的开源版本。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/270836.html
