
AIxiv专栏是机器之心发布学术和技术内容的专栏。几年来,机器之心AIxiv专栏已收到2000余篇报道,覆盖全球各大高校和企业的顶级实验室,有效促进了学术交流和传播。如果您有优秀的作品想要分享,请随时投稿或联系我们进行举报。投稿邮箱:liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
这项工作来自北京大学智能学院王立伟、何迪课题组和华为诺亚方舟实验室李振国、孙家成研究员。作者包括智能学院博士生冯谷浩、顾云天、罗胜杰;信息科学与技术学院本科生杨凯、艾新月。
大模型量化通过将模型参数从较高精度(如bfoat16)压缩到较低精度(如int8或int4)来降低模型推理成本并提高模型推理速度。在大语言模型的实际部署中,量化技术可以显着提高大语言模型推理的效率。然而最近,来自哈佛大学、麻省理工学院、卡内基梅隆大学、斯坦福大学和Databricks的研究团队通过大量实验总结出了关于大型语言模型准确性的Scaling Law。实验发现,模型的量化压缩会极大地影响大型语言模型的性能。
无独有偶,北京大学和华为的研究团队最近从理论角度研究了量化对大型模型通用性的影响。具体来说,研究人员关注量化对大型模型数学推理能力的影响。其研究理论表明,足够的模型精度是大型模型解决基本数学任务的重要前提,而量化会大大降低大型模型在基本数学任务上的性能,甚至增加参数数量也无法弥补。

论文链接:
量化降低了模型的基本数学能力
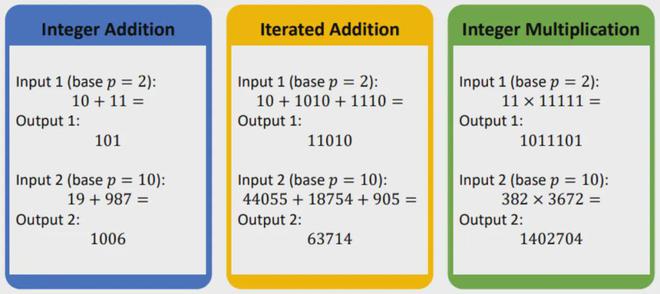
数学推理能力是大语言模型的重要能力,也是大语言模型走向通用人工智能的关键能力之一。然而,与经典的自然语言处理任务相比,数学推理往往需要严格的逻辑和准确的中间结果。在各种数学推理任务中,算术能力是大型语言模型解决各种复杂数学问题的基础。更需要注意的是,大模型在处理数值时,会将一个数字“切割”成一段段数字。例如,数字1234.5678可以被编码为“12”“34”“。” “56”“78”,这样编码的信息能否被正确理解来完成算术任务也是值得怀疑的。
这项工作的研究人员以基本算术能力为出发点,研究了不同精度的 Transformers 解决基本数学任务的能力差异。下图显示了一些相应的示例。为了体现大模型对长数字的实际解码方法,在这些任务中,操作数中的每个数字都作为独立的 token 作为大模型的输入,大模型的输出也是输出数字按位数从高到低。
在这项工作中,研究人员使用对数精度 Transformer 和恒定精度 Transformer 的理论模型来表征标准精度大语言模型和量化低精度大语言模型。其中,对数精度是指Transformer内部的单个神经元最多可以存储一个由O(logn)位表示的实数,其中n指的是模型可以处理的最大序列长度。恒定精度意味着 Transformer 内部的单个神经元最多只能存储由 c 位表示的实数,其中 c 是一个与序列长度无关的小常数。这里,实数可以用定点或浮点格式表示。
目前主流的大语言模型,包括GPT系列、Claude系列或者开源的LLAMA系列,可以处理的最大序列长度一般在4k到128k之间。在这样的序列尺度下,对数精度和恒定精度更好地表征了量化前后的精度差异。
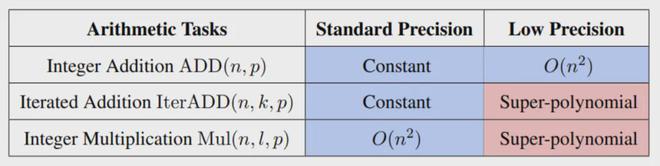
之前的研究结果表明,标准精度的Transformer有能力解决这些基本的算术任务。这说明适当的精度可以保证大型模型有能力解决相应的基本数学任务。然而,这项工作的理论证明,当大型语言模型被量化并且其准确性降低时,模型的能力会受到显着影响。当使用低精度模型时,模型需要超多项式数量的模型参数来执行多整数加法和整数乘法等任务。这表明,当精度不足时,即使充分增大模型尺寸(缩放参数),也很难获得完成这些基本算术任务的能力。
下表总结了相应的理论结果,显示了不同精度下每个基本算术任务所需的模型宽度。其中,蓝色表示模型可以在较小的尺寸内解决相应的任务,红色表示模型无法在可接受的尺寸内解决相应的问题。可以发现,具有标准精度的大型语言模型可以轻松解决算术任务。然而,量化后精度较低的大型模型在解决基本算术任务的能力上存在明显不足。
实验验证
除了理论推导之外,研究人员还进行了大量的实验来验证理论结果。研究人员在算术运算数据集上训练了一系列小模型。小模型的训练结果表明,提高多整数加法和整数乘法任务的准确性可以使相同尺寸的模型解决更大规模的问题。问题。
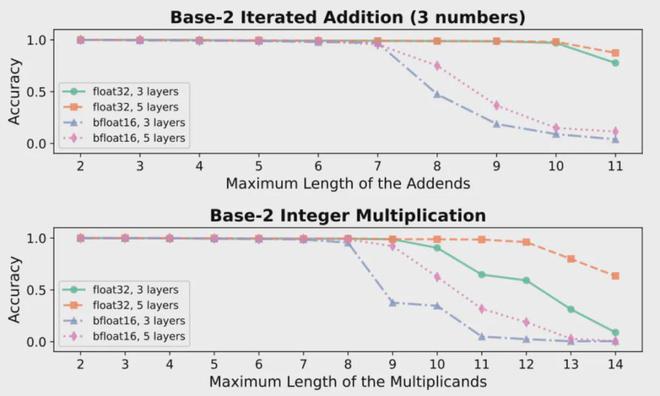
此外,研究人员进一步在LLaMA3.1-8B模型上进行了一系列实验。实验结果也证实,使用int4进行量化后,大语言模型在各项基本算术任务上的性能都相应下降。对于最困难的整数相乘任务,性能下降最为明显。

总而言之,模型的量化压缩会显着损害大型语言模型在数学推理问题上的性能。为了解决复杂的数学推理问题,足够的精度至关重要。这也说明,在大语言模型的实际部署中,我们不能盲目追求量化带来的效率。我们还必须考虑应用场景,在考虑大语言模型的实际性能和运行效率的同时,采取适当的部署策略。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/271666.html
