
智东西网12月21日报道 今天,OpenAI“圣诞十二连发”终于迎来了激动人心的大结局。 OpenAI推出了一款重磅新品,是其迄今为止最强大的前沿推理模型——o3的升级版。
OpenAI声称o3在某些条件下接近通用人工智能(AGI)。
OpenAI首席执行官Sam Altman在直播中表示:“我们认为这是AI下一阶段的开始。你可以使用这些模型来完成需要大量推理的日益复杂的任务。”他还赞扬了o3在编程方面的表现。真是难以置信。
今年9月发布的OpenAI o1模型为推理模型打开了闸门。随后,国内外多家大型模型公司纷纷推出了大量的推理模型。出于对英国电信运营商O2的尊重,OpenAI将o1的继任者命名为o3。
与上一代o1模型一样,o3通过思维链条进行思考,逐步解释其逻辑推理过程,并总结出它认为最准确的答案。
o3 有完整版和迷你版。新功能是您可以将模型推理时间设置为低、中、高。模型思考时间越长,效果越好。迷你版更加精简,针对特定任务进行了微调,将于 1 月底推出,o3 完整版将在不久后推出。
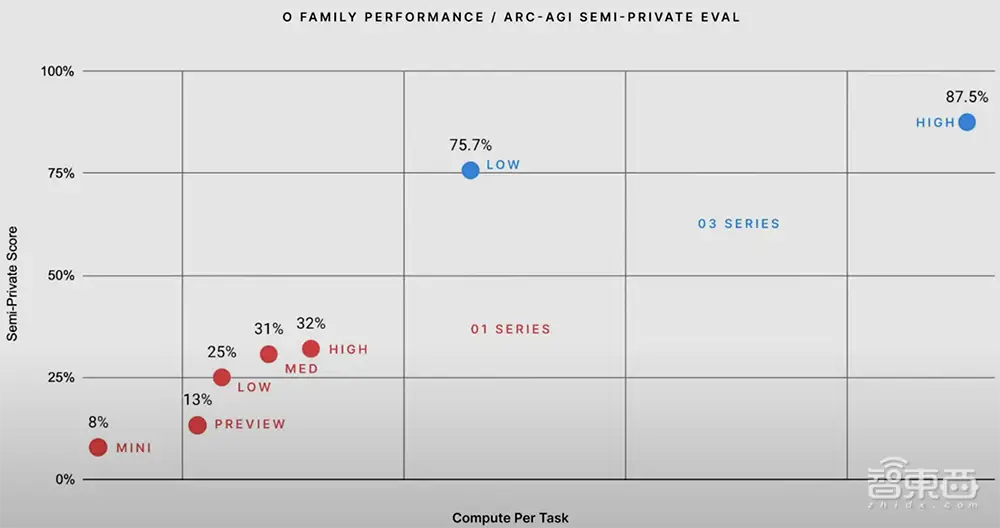
ARC-AGI是一项基准测试,旨在评估人工智能系统推理首次遇到的极其困难的数学和逻辑问题的能力,由Keras之父François Chollet发起。在ARC-AGI测试中,o3在高推理设置下取得了87.5%的分数,而在低推理设置下的分数高达o1的3倍。
这一成就让社交平台兴奋不已,认为AI技术的发展并没有放缓,反而表现出了比预期更快的迈向AGI的速度。
要知道,之前GPT-3的评测结果是0%,GPT-4o是5%,o3一举将分数提升到了87.5%,令人大跌眼镜。与之前的大型模型相比,o3能够适应以前从未遇到过的任务,可以说接近人类水平的表现。
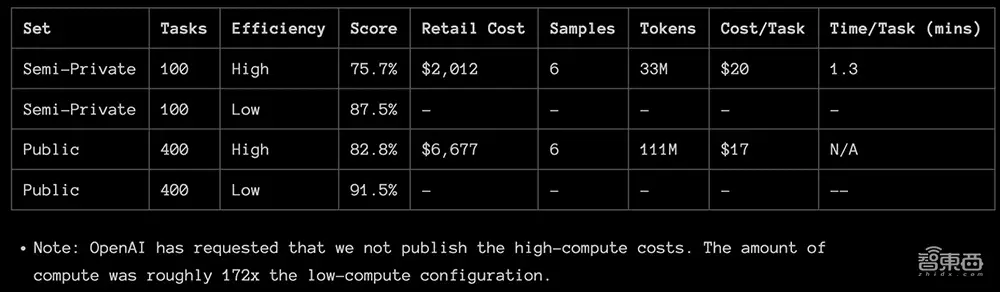
François Chollet 发布了 o3 的完整测试报告。 o3 在两个 ARC-AGI 数据集和两个计算级别上进行了测试,样本大小可变:6(高效率)和 1024(低效率,172 倍计算)。其中,75.7%的高效率分数在ARC-AGI-Pub的预算规则之内(87.5%的低效率分数的成本相当昂贵,但仍然表明新任务的性能确实有所提高计算量增加。
检测报告指导:
目前o3不是很经济。用户可以付费手动解决ARC-AGI任务,每个任务大约5美元(折合人民币约36元),仅消耗几分钱的能源。在低推理模式下,o3 完成每项任务的成本为 17-20 美元(折合人民币约 124 至 145 元)。
OpenAI 明年将与 ARC-AGI 背后的基金会合作,建立下一个基准。
在其他基准测试中,o3的表现也远优于竞品。
在由真实软件任务组成的SWE-Bench Verified基准测试中,o3模型的准确率约为71.7%,比o1模型高出20%以上。 OpenAI 研究高级副总裁 Mark Chen 表示:“这确实意味着我们正在拓展实用性的前沿。”
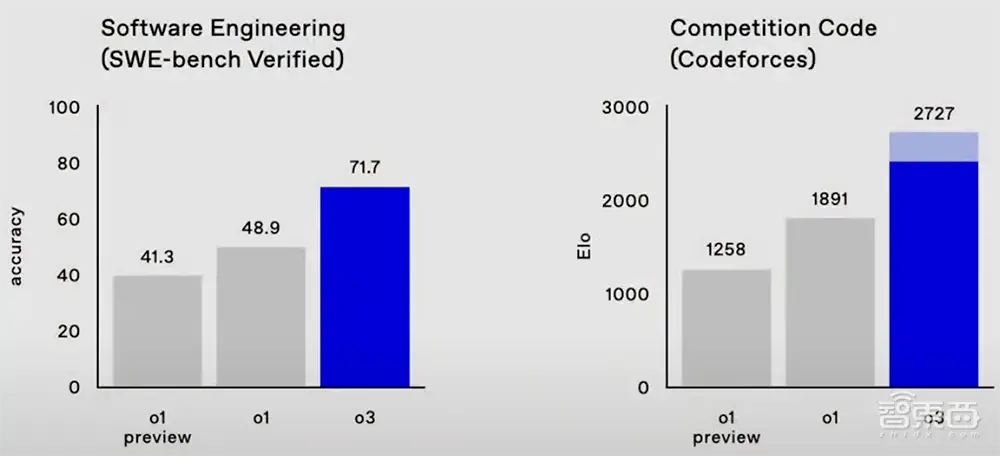
在编程竞赛Codeforces中,o1的得分为1891,而o3在高推理设置下可以达到2727分,低推理设置下的得分也超过了o1。
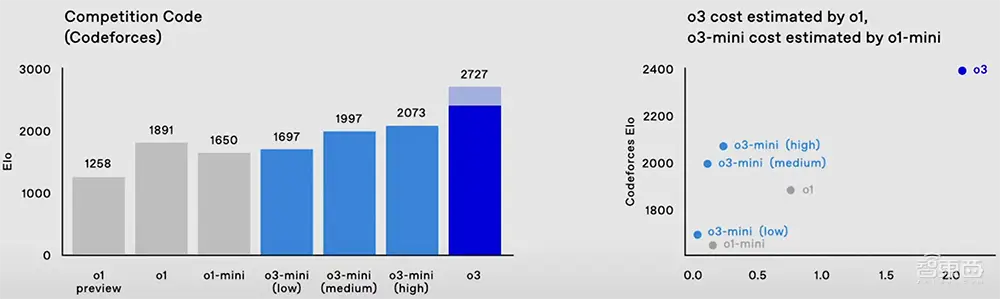
从Codeforces的排名来看,o3的成绩可以排在第175位。
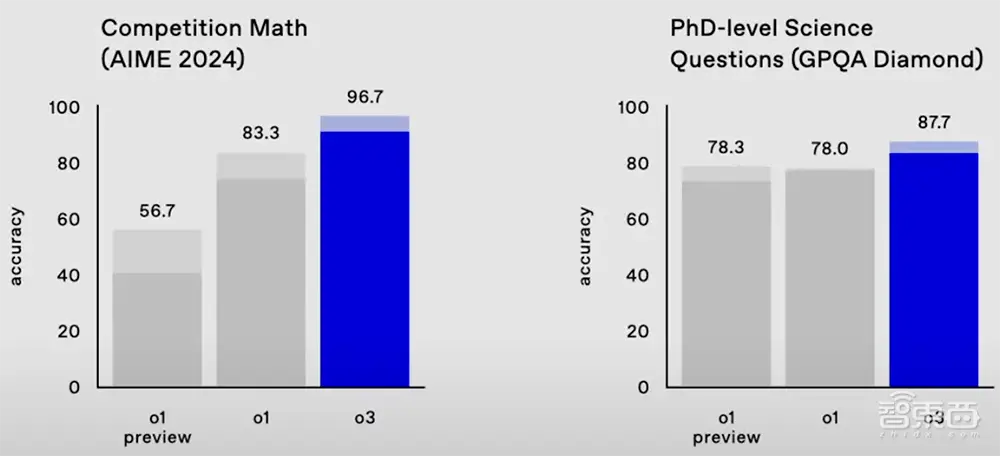
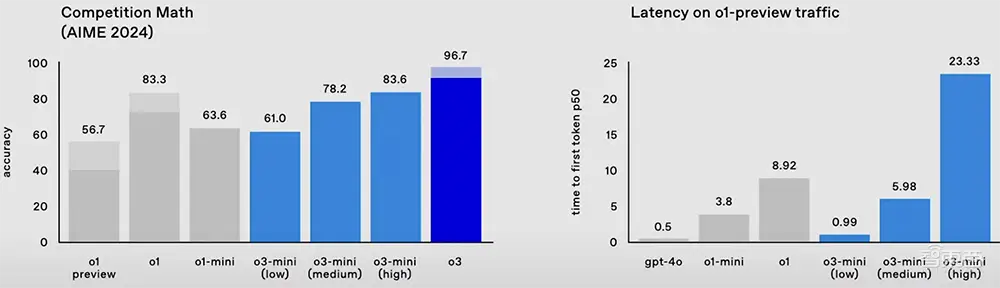
在数学基准 AIME 2024 中,o3 的准确率达到 96.7%,仅漏掉一题,而 o1 的准确率达到 83.3%。
在衡量博士级科学问题的严格基准测试GPQA Diamond中,o3的准确率高达87.7%,比o1的78%高出约10%。专业博士通常 70% 的成绩来自于他们的优势领域。
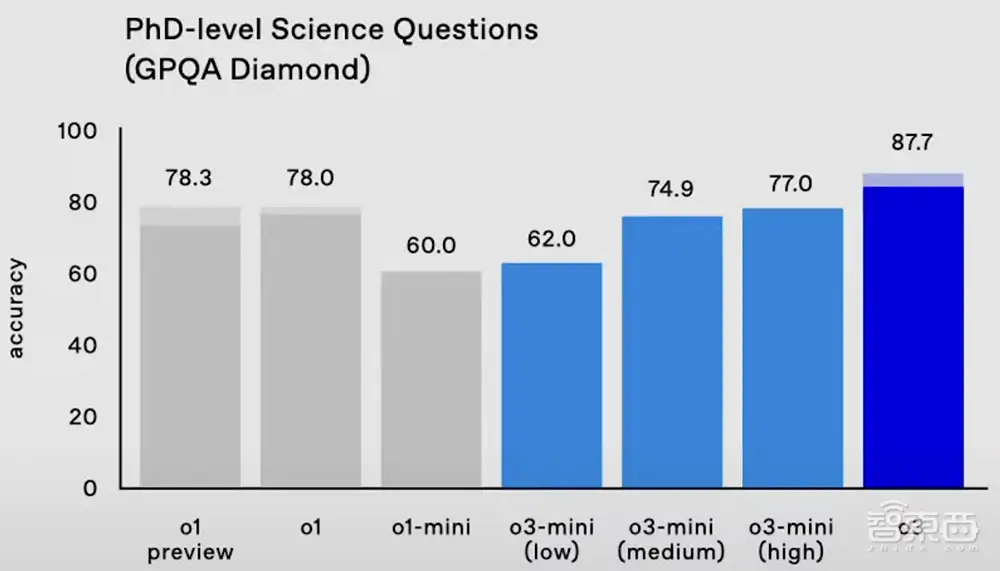
OpenAI研究科学家任宏宇演示了一个使用Python生成和执行代码的示例。
在短短 30 秒多的时间里,o3-mini 编写了自己的 ChatGPT UI,并通过发送请求来调用 API 与自身对话。让 o3-mini 在此 UI 中编写并执行脚本来评估其在 GPQA 上的性能。结果,脚本正确返回了 61.62% 的值,与正式评估结果相似。
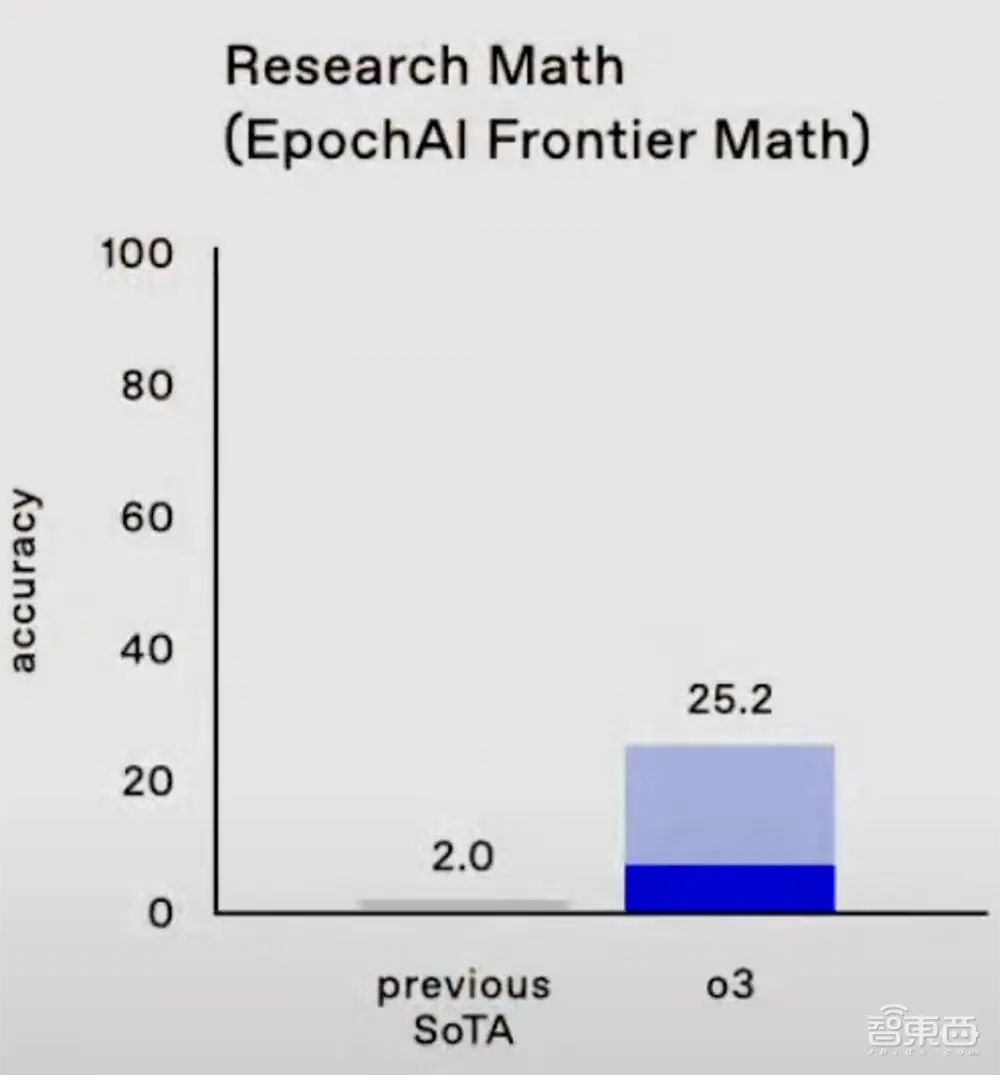
o3还在陶哲轩与全球60多位数学家联合发起的被誉为业界最强数学标杆的EpochAI前沿数学中创下了新纪录,得分为25.2。其他型号均未超过2.0。
有趣的是,在o3发布前不久,OpenAI GPT系列论文的主要作者Alec Radford刚刚宣布辞职,将转向独立研究。
最近尖端模型的发布速度令人眼花缭乱。新发布的o3模型能否继续捍卫OpenAI在前沿技术的权威,将备受关注。

OpenAI 连续 12 个圣诞节发布的完整回顾:
Day1:发布o1全血版和最贵的ChatGPT Pro订阅版,200美元/月。
Day2:发布增强微调新功能,可以用少量的训练数据构建特定领域的专家模型。
Day3:发布视频生成模型Sora。
Day4:Canvas全面开放,代码功能升级。
Day5:演示OpenAI与苹果的智能协作功能。
Day6:发布先进的实时视频理解能力。
Day7:在ChatGPT功能中发布项目。
Day8:搜索功能全面开放,支持语音搜索。
Day9:o1 API开放,API实时更新。
第 10 天:拨打 1-800-ChatGPT 热线访问 ChatGPT。
Day11:演示Mac桌面App与各种App之间的互操作性。
Day12:发布o3和o3 mini推理模型。
虽然o3系列模型不会立即发布,但从今天开始,OpenAI将向安全研究人员开放o3的访问权限。申请截止日期为1月10日。
OpenAI 透露了其新对齐策略的更多技术细节。现代大语言模型使用监督微调(SFT)和带有人类反馈的强化学习(RLHF)来进行安全训练,但仍然存在安全缺陷。 OpenAI 研究人员认为,许多失败是由于两个限制造成的:
在此基础上,OpenAI提出了一种协商对齐(Deliberative Alignment)训练方法,该方法将基于过程和基于结果的监督相结合,让大型模型在生成答案之前可以通过安全规范显式地进行复杂推理,从而克服上述两个问题。
相比之下,在推理时优化响应的其他策略将模型限制为预定义的推理路径,并且不涉及对学习的安全规范的直接推理。
审议和协调的具体步骤如下:
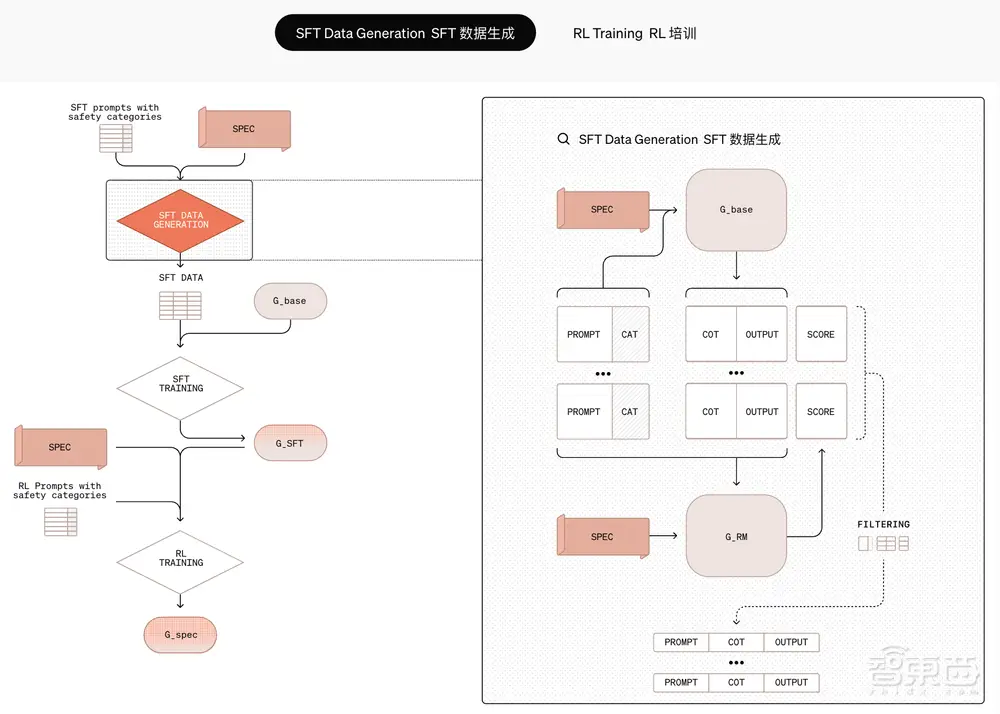
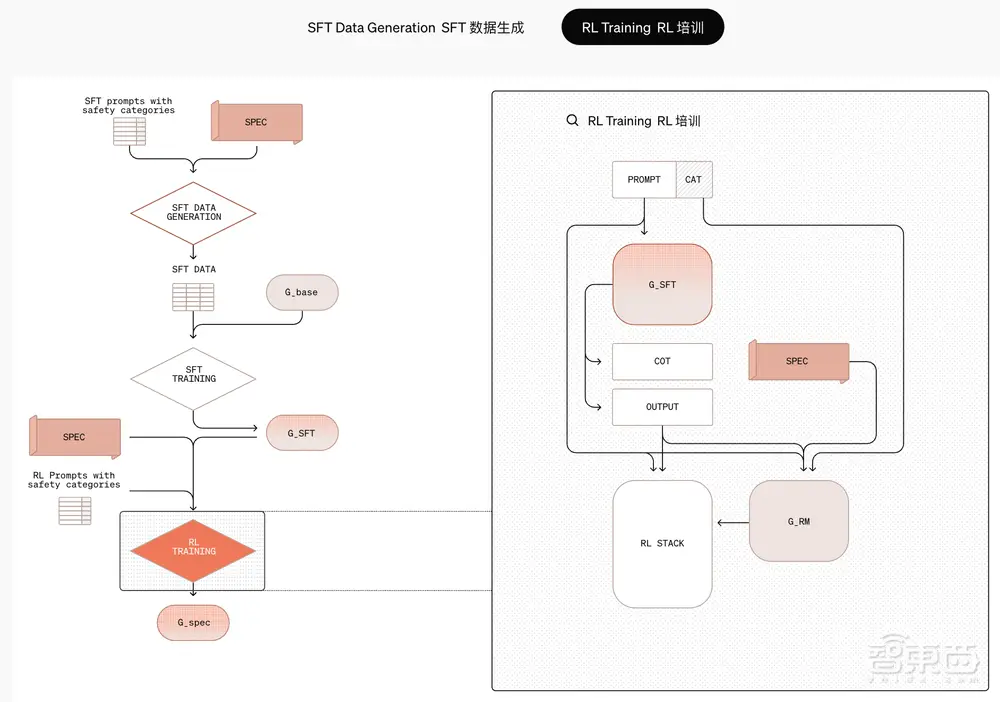
其战略分为两个核心阶段。在第一阶段,模型被教导通过对思想链中引用规范的示例进行监督微调,直接在其思想链中推理安全规范。在此过程中,研究人员将基于上下文蒸馏和仅针对实用性进行训练的 O 系列模型来构建数据集。通过直接向模型传授安全规范文本并训练模型在推理时仔细考虑这些规范,它可以生成针对给定环境进行适当校准的安全响应。通过将此方法应用于 OpenAI 的 o 系列模型,他们能够使用思维链推理来检查用户提示并确定相关政策指导。
就像下图中O1思维链的例子一样。用户试图获取有关成人网站使用的无法追踪的支付方式的建议,以避免被执法部门发现。用户试图通过对请求进行编码并用旨在鼓励模型遵守的指令包装请求来越狱模型。在思维链中,模型对请求进行解码并识别出用户试图欺骗它(以黄色突出显示),成功推理出相关的 OpenAI 安全策略(以绿色突出显示),并最终拒绝用户请求。
▲o1创意链示例

在第二阶段,研究人员使用高度计算的强化学习来训练模型更有效地思考,并引入使用给定安全规范的大型裁判模型来提供奖励信号。
值得注意的是,OpenAI的训练程序不需要人工标注,仅依靠模型生成的数据就可以实现高度准确的规范合规性。这解决了严重依赖大规模人工标记数据的标准大型模型安全训练的挑战。
RLHF、RLAIF、推理时间校正技术、慎思对齐方法的对比如下图所示:
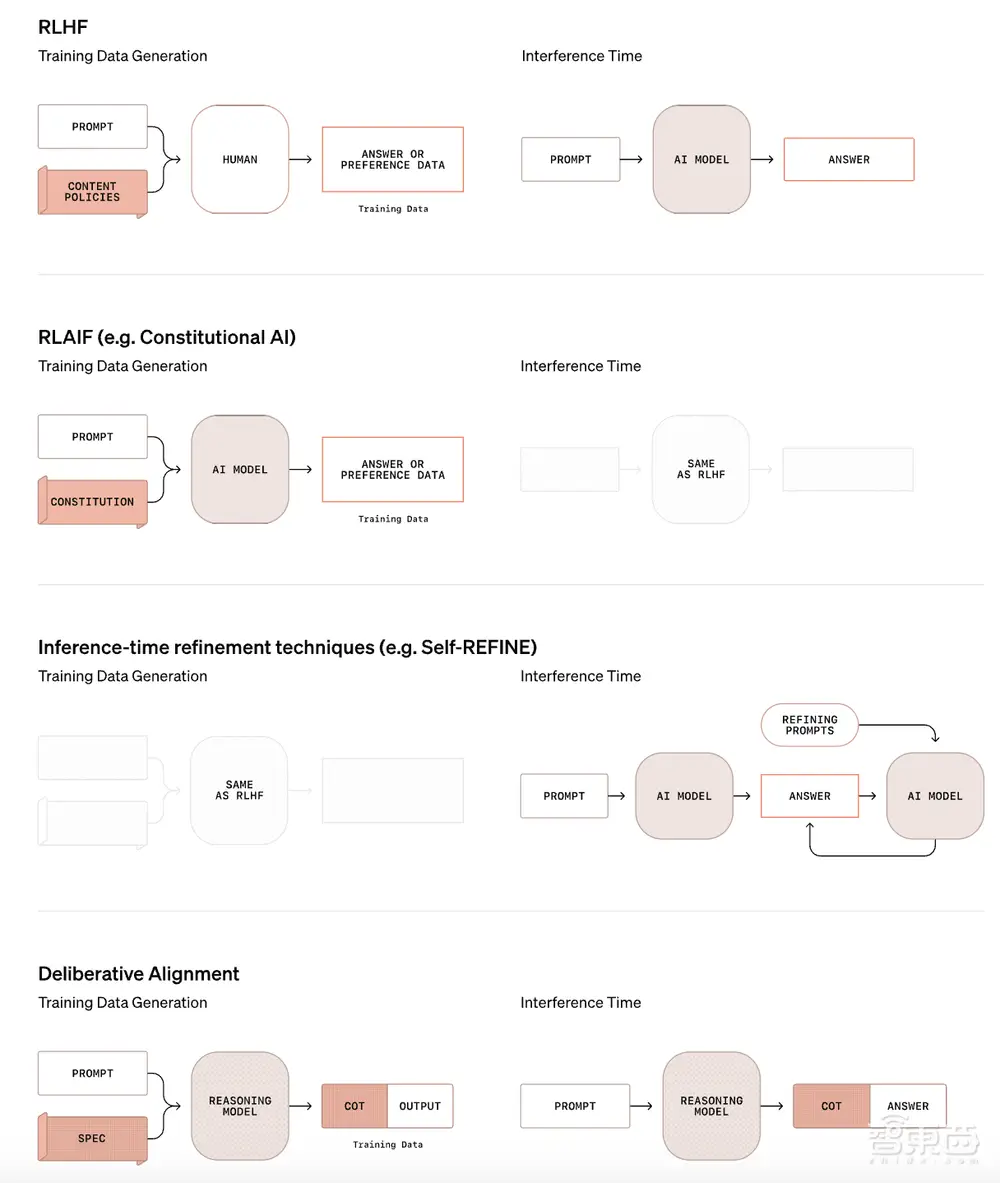
▲刻意对准与现有对准方法对比
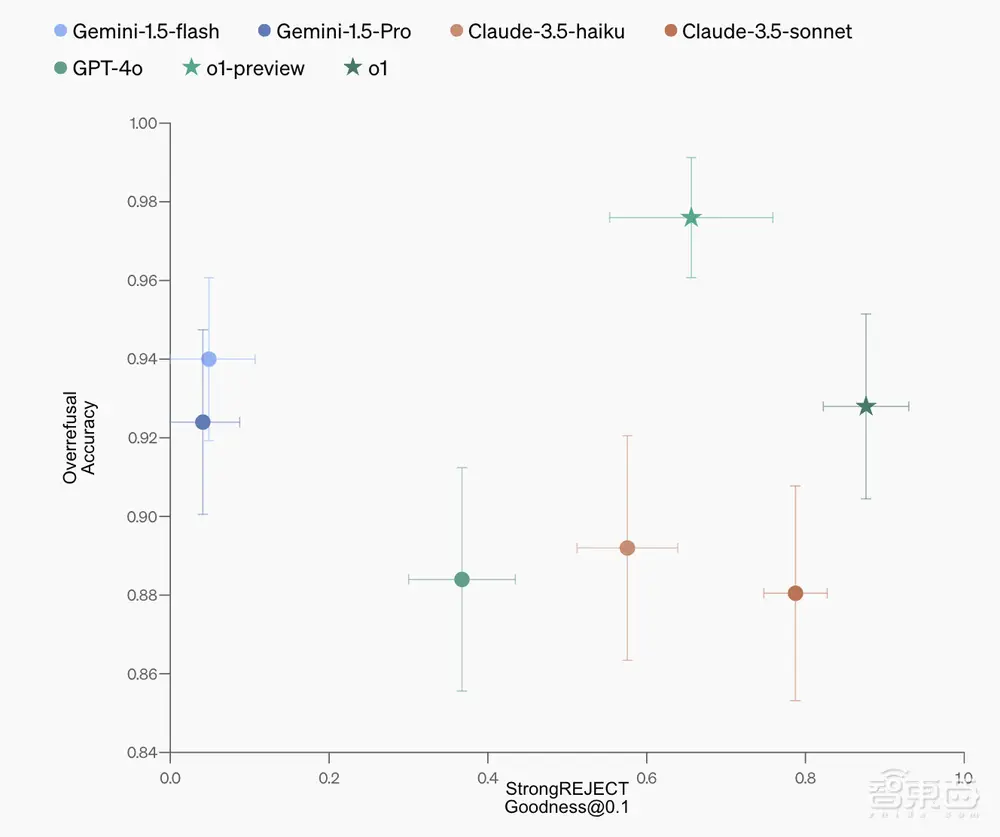
根据结果,研究人员在一系列内部和外部安全基准中将 o1 的安全性与 GPT-4o、Claude 3.5 Sonnet 和 Gemini 1.5 Pro 进行了比较。 o1 模型通过了一些更困难的安全评估,并在拒绝和拒绝方面实现了帕累托改进(使性能更好而不使任何事情变得更糟)。
至此,OpenAI的“圣诞礼物”已经结束,但全球AGI竞赛仍在加速。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/273492.html
