
最近,哈佛大学的一位教授透露,DeepSeek有机会出生在美国?最初,DeepSeek工程师可以得到NVIDIA的全职报价,但美国并没有留住他,这导致了“ Qian Xuesen返回中国”的故事,而美国通过“国家财富级AI级AI “!
对美国构成的DeepSeek的威胁仍在加剧。
就在昨天,DeepSeek的日常活跃用户达到了Chatgpt的23%,每日申请下载近500万!
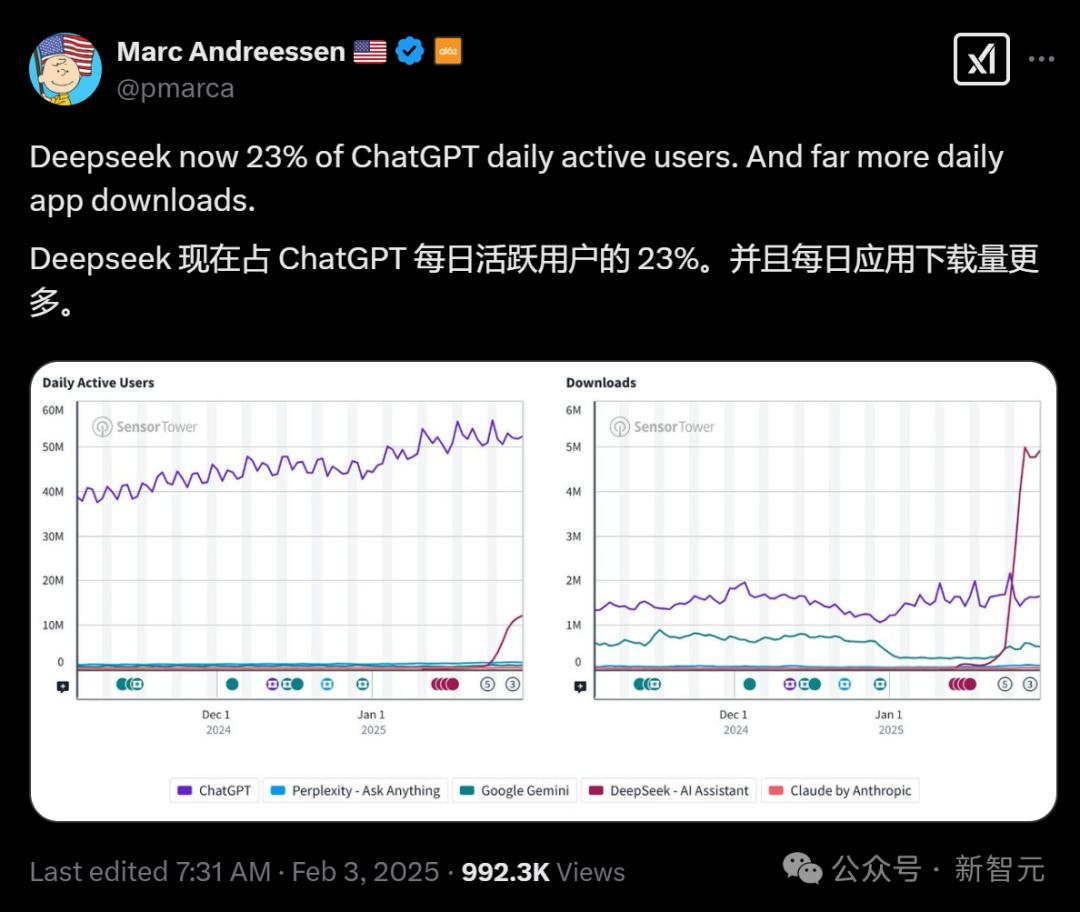
A16Z Lianchuang Marc Andreessen发布
谁会想到做出DeepSeek的关键贡献的才能可能会留在美国。
最近,哈佛大学的一位教授揭露了这个惊人的事实:DeepSeek多式联运团队的第四任工程师本来可以收到NVIDIA的全职报价。
但是,最后,他选择回家加入DeepSeek。结果是,美国在AI领域的统治地位被动摇了,一百万元人民币蒸发的关联公司的市场价值,全球AI景观被完全推翻。
这结果是巧合还是不可避免的结果?
美国错过了DeepSeek,允许Qian Xuesen再次回家
最近,政治学家,哈佛大学教授兼前国防助理部长格雷厄姆·艾莉森(Graham Allison)在X上问:“谁错过了DeepSeek?”

他在X上发表了一篇伤心欲绝的帖子,DeepSeek刷新了他对美国AI身份的理解,并且美国有机会保留了DeepSeek的一位主要员工:
(DeepSeek超越了与OpenAI相关的模型)颠覆了我们对美国AI主导地位的大部分理解。
这也生动地提醒我们,包括中国在内的美国必须认真对待美国的才华。
DeepSeek多模式团队的第四个多工程师潘·Zizheng(Pan Zizheng)在开发DeepSeek的R1模型中发挥了重要作用。
在返回中国之前,他在NVIDIA实习了4个月,并收到了Nvidia的全职邀请。
格雷厄姆·艾莉森(Graham Allison)认为,潘Zizheng(Pan Zizheng)就是这样,因为硅谷公司未能为他提供在美国这样做的机会。
这种“人才丧失”使格雷厄姆·艾莉森(Graham Allison)感到伤心欲绝,甚至使潘·Zizheng(Pan Zizheng)的中国恢复到Qian Xuesen的回归高峰!

Qian Xuesen,Huang Renxun和Musk等超级才华可以用脚投票,展示自己的才华并在任何地方取得巨大的成就。
他认为,美国应该尽力避免这种“人才丧失”:
美国的大学教练正在寻找并招募世界上最有才华的运动员。
在中国与美国之间的技术竞争中,美国应尽一切努力避免失去更多的人才,例如Qian Xuesen和Pan Zizheng。
NVIDIA遗憾失去人才
在得知DeepSeek超过Chatgpt之后,NVIDIA的高级研究科学家Yu Zhiding分享了Zizheng实习生的选择,以返回中国。他对自己目前的成就感到满意,并在AI比赛中分享了他的看法:

在2023年夏天,Azuma是Nvidia的实习生。后来,当我们考虑是否要为他提供全职工作时,他选择毫不犹豫地加入DeepSeek。
当时,DeepSeek的多模式团队只有三个人。
当时Zi Zheng的决定仍然给我留下了深刻的印象。
在DeepSeek,他做出了重要的贡献,并参加了多个关键项目,包括DeepSeek-VL2,DeepSeek-V3和DeepSeek-R1。我个人对他的决定和他的成就感到非常满意。
Zheng的案子是我近年来见过的一个典型例子。许多最佳才能来自中国,这些才能不一定仅在美国公司中取得成功。相反,我们从他们那里学到了很多东西。
早在2022年,在自主驾驶领域(AV),类似的“爆发时刻”已经发生,并将继续在机器人和大语言模型(LLM)行业中发生。
我喜欢Nvidia,并希望看到它仍然是AGI和通用自主系统发展的重要驱动力。但是,如果我们继续编织地缘政治议程并对中国研究人员产生敌意,我们只会破坏我们的未来并失去更多的竞争力。
我们需要更多出色的才能,更高的专业精神,更强大的学习能力,创造力和更强的执行能力。

Pan Zi是DeepSeek-VL2的联合工作
当DeepSeek超过Chatgpt到App Store下载列表最高时,Pan Zi分享了他对X的感受:
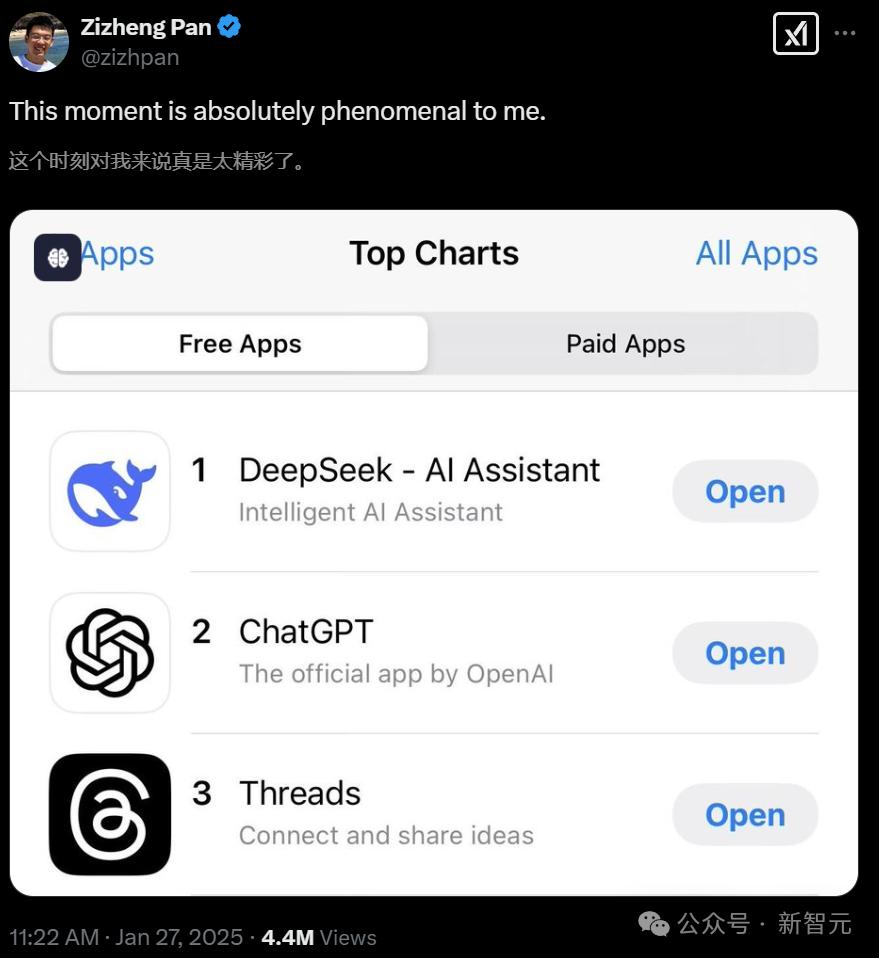
潘·Zizheng(Pan Zizheng)于2024年以研究人员的身份全职加入DeepSeek。他曾在NVIDIA的AI算法小组担任研究实习生。
2021年,Pan Zijing加入了Monash University的Zip Lab,攻读博士学位。在计算机科学领域,他的主管是Bohan Zhuang教授和Jianfei Cai教授。在此之前,他获得了阿德莱德大学的计算机科学硕士学位,并获得了Harbin Technology(Weihai)的软件工程学士学位。
在她的博士学位期间,潘·Zizheng(Pan Zizheng)的研究兴趣主要集中在深度神经网络的效率上,包括模型部署,变压器体系结构优化,注意力机制,推理加速和记忆效率训练。

Lex Fridman Hardcore播客揭示了中国的AI明星如何摇摆全球景观
就在最近,Lex Fridman发布了一个五个小时的播客,邀请AI2模型培训专家Nathan Lambert和Semiansis硬件专家Dylan Patel。
在与大量信息的对话中,他们在整个过程中专注于DeepSeek,并讨论了这位新的中国AI明星如何摇晃全球景观,Moe Architecture + MLA技术的双层边缘,DeepSeek开源迫使该行业开放和开放中国风格的极端优化硬件魔术等的方式。

DeepSeek使用OpenAI数据吗?
这次,几次大镜头之间的对话非常敏锐,直接指向问题的核心。
例如,这个关键问题:DeepSeek是否使用OpenAI数据?
以前,Openai公开表示DeepSeek使用自己的模型进行蒸馏。

《金融时报》简单地说:“ Openai有证据表明DeepSeek使用其模型进行训练。”
这在道德上和法律上是可定义的吗?
尽管OpenAI的服务条款规定,不允许用户使用自己的模型的输出来建立竞争对手。但是,这种所谓的规则实际上是Openai伪善的一种体现。
Lex Fridman说:“像大多数公司一样,他们最初是在未经许可就从Internet上的数据中受益。
大家好同意Openai声称DeepSeek使用其模型来训练,试图转移主题并赢得整个过程。
此外,在过去的几天中,许多人将DeepSeek的模型提炼为骆驼。操作以前的推论是非法的,而美洲驼很容易提供服务?

为什么DeepSeek的培训成本如此低
迪伦·帕特尔(Dylan Patel)说,DeepSeek的成本涉及两种关键技术:一个是Moe,另一个是MLA(肿块潜在的关注)。
MOE体系结构的优点是,一方面,该模型可以将数据嵌入较大的参数空间中,另一方面,当训练或推理时,该模型只需要激活某些参数,从而大大提高了效率。 。
与Llama 405B相比,DeepSeek模型具有超过6000亿个参数。从参数量表的角度来看,DeepSeek模型具有更大的信息压缩空间,可以容纳更多的世界知识。
但同时,DeepSeek模型一次仅激活约370亿个参数。也就是说,在培训或推理过程中,只需要计算370亿个参数。相比之下,Llama 405b模型需要为每个推理激活4050亿个参数。
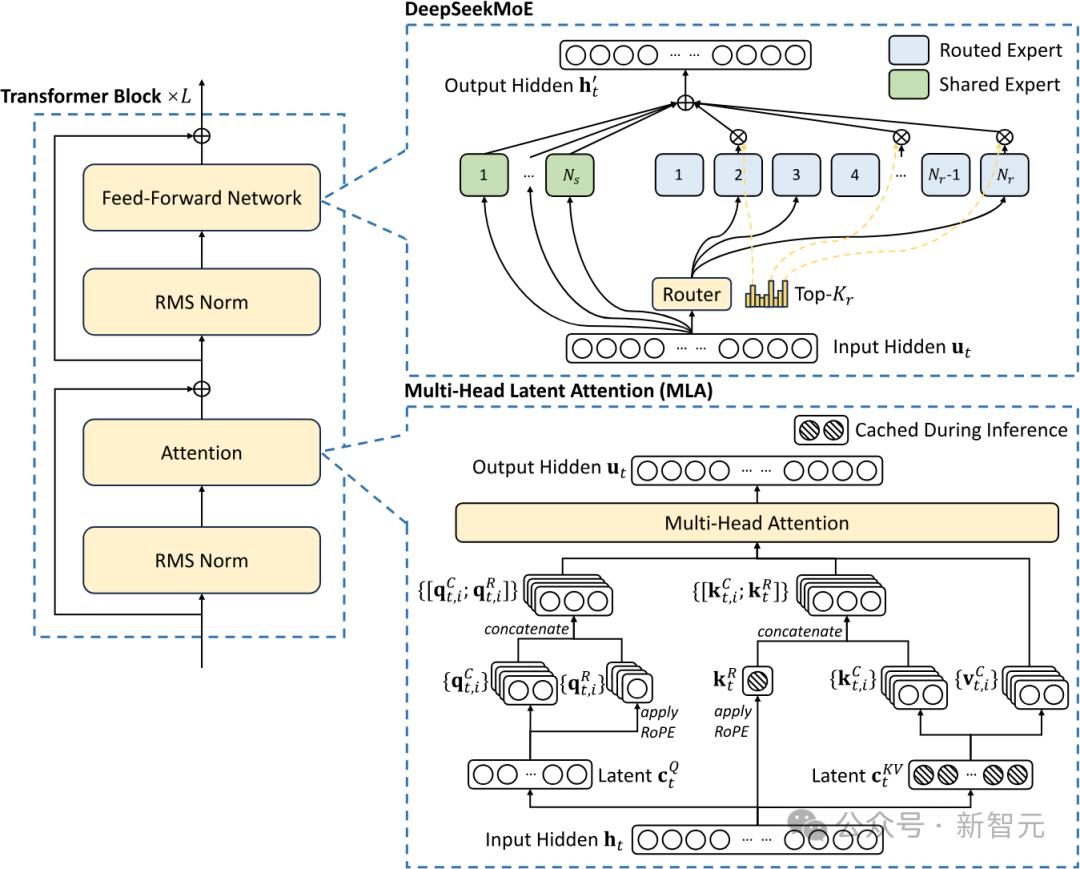
MLA主要用于减少推理期间的记忆使用量,在训练过程中也是如此,该训练利用了一些巧妙的低级近似数学技术。
内森·兰伯特(Nathan Lambert)说,对潜在关注的细节的深入研究将表明,DeepSeek为实施模型付出了很多努力。
因为除了注意机制外,语言模型还具有其他组件,例如用于扩展上下文长度的嵌入。 DeepSeek使用旋转位置代码(绳索)。
使用绳索与传统的MOE需要一系列操作,例如两个注意力矩阵的复杂旋转,涉及矩阵乘法。
DeepSeek的MLA架构需要一些巧妙的设计,因此实施的复杂性大大提高了。他们成功地集成了这些技术,表明DeepSeek处于有效的语言模型培训的最前沿。
迪伦·帕特尔(Dylan Patel)说,DeepSeek正在尝试提高模型培训的效率。其中一种方法是不直接调用NVIDIA的NCCL库,而是按本身安排GPU之间的通信。
使DeepSeek的独特之处在于,他们通过安排特定的SMS(流多处理器)来管理GPU通信。
DeepSeek很好地控制了SM内核负责模型计算以及哪些内核负责Alleduce或Allgather Communications,并在它们之间动态切换。这需要非常高级的编程技能。
为什么DeepSeek如此便宜
在声称提供R1服务的所有公司中,价格比DeepSeek API高得多,而且大多数服务都无法正常工作,并且吞吐量极低。
震惊的是,一方面,中国已经实现了这种能力,另一方面,价格如此之低。 (R1的价格比O1便宜27倍)
上面提到的为什么培训很便宜。为什么推理的成本如此低?
首先,DeepSeek在模型架构中的创新。 MLA的新注意力机制与变压器注意机制不同。
这种长期潜在的关注可以将注意机制的记忆使用降低约80%至90%,尤其是在长期以来的帮助。
此外,DeepSeek和OpenAI之间的服务成本差异很大,部分原因是Openai的利润率很高,其理由毛利率超过75%。
由于Openai目前正在亏损,并且在培训上花费了太多,所以推理的利润率很高。
下一个亮点在这里。几个大wigs让他们的想象力消失了,猜测这是否将是一个阴谋论:DeepSeek仔细计划了这一发布和定价,短暂的NVIDIA和美国公司的股票,并随着Stargate的释放而合作。
但是这种猜测立即被驳斥。迪伦·帕特尔(Dylan Patel)说,他们刚刚在《农历新年》之前尽快发布了该产品,并且不打算做大型产品。否则,他们为什么选择在圣诞节后一天发布V3?
中国的工业能力远远超过美国的工业能力
在GPU等筹码领域,美国无疑领先于中国。
但是,GPU出口的控制能否完全阻止中国?不太可能。
迪伦·帕特尔(Dylan Patel)认为,美国政府也清楚地意识到了这一点,而内森·兰伯特(Nathan Lambert)认为中国将自己制作筹码。
中国可能有更多的才能,更多的STEM毕业生和更多的程序员。当然,美国也可以使用来自世界各地的才能,但这不一定会给美国带来额外的优势。
真正重要的是计算能力。
中国拥有的总电量已经很棒。中国的钢铁厂相当于整个美国行业的总规模,并且有铝厂需要大量电力。
即使美国星际之门确实是建造的,达到了2 GW的电力,它仍然比中国最大的工业设施小。

可以说,如果中国建立世界上最大的数据中心,只要有芯片,它就可以立即完成。因此,这只是时间问题,而不是能力问题。
现在,建立发电,传输,变电站和变压器等数据中心所需的需要限制美国构建越来越大的培训系统,并部署越来越多的推理计算功能。
相比之下,如果中国像纳德拉(Nadella),扎克伯格(Zuckerberg)和皮希(Pichai)这样的美国高管这样的规模法律,甚至可以比美国更快地实现。
因此,为了减慢中国AI技术的发展并确保不能大规模培训AGI,美国已发布了一系列禁令 - 通过限制了诸如GPU和光刻机器等关键要素的出口,试图“禁止”整个半导体行业。
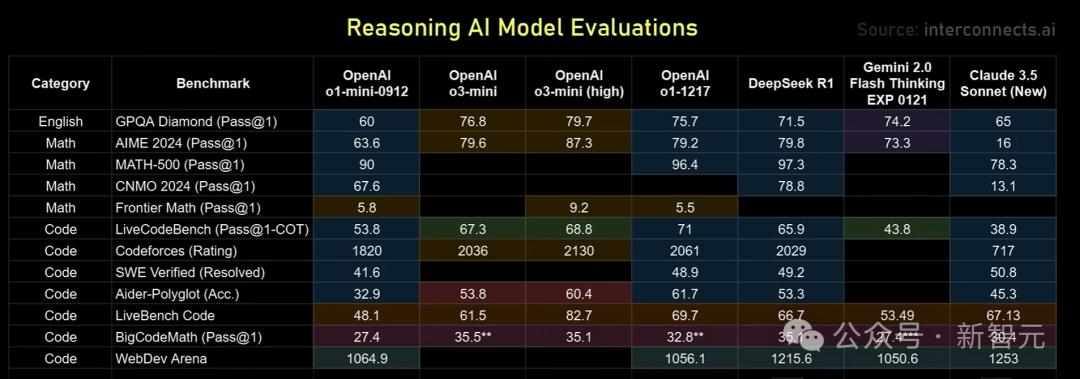
Openai O3 Mini可以追赶DeepSeek R1吗?
接下来,几个大wigs对几种名人推理模型进行了实际测试。

有趣的是,在价格和性能方面,Google的双子座闪光思维比R1更好,并于去年12月初发布,但没有人关心它...
在这方面,几种大镜头的感觉是,其行为模式不如O1的表现力,其应用程序场景较窄。 O1在特定任务上可能不是最完美的,但是它更灵活和多功能。
Lex Frieman说,我个人对R1的喜欢是,它将显示一个完整的思维链令牌。
在开放式的哲学问题中,作为可以欣赏智慧,推理和反思能力的人类,我们在阅读R1的原始思维链代币时会感到独特的美丽。
这种非线性思维过程类似于詹姆斯·乔伊斯(James Joyce)的《意识流》小说和芬尼根(Finnegan)的唤醒过程,令人着迷。

相比之下,O3米尼给人们一种聪明和快速的感觉,但缺乏亮点,通常是平庸的,缺乏深度和新颖性。
从下面的图,从GPT-3到GPT-3.5,再到Llama可以看出,推断成本是指数下降的趋势。
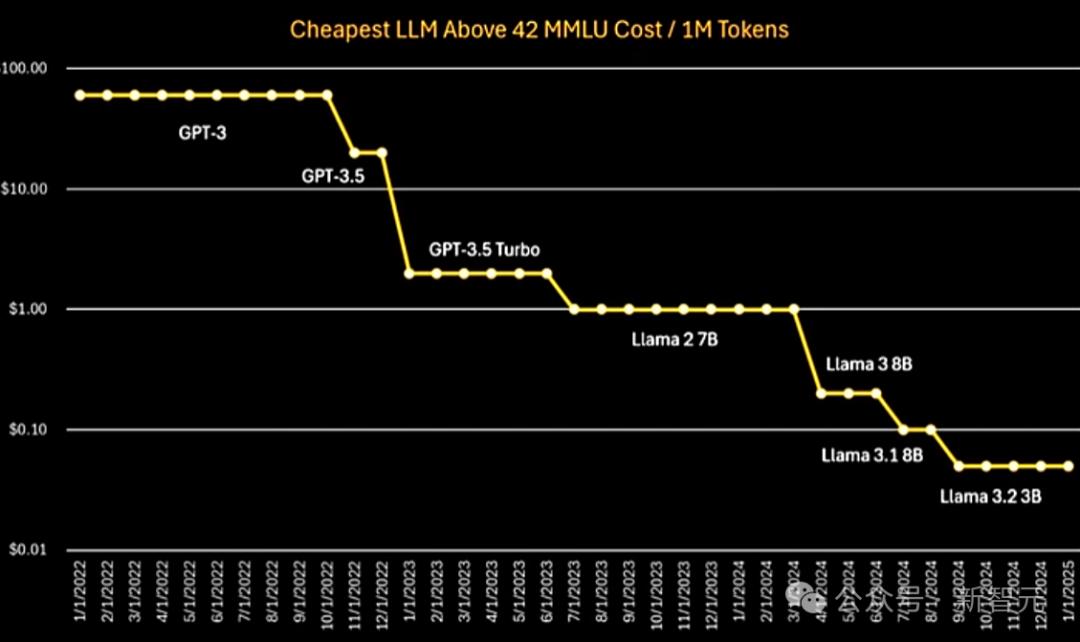
DeepSeek R1是实现如此低成本的第一个推理模型,这一成就令人惊讶,但其成本水平并不超出专家期望的范围。
将来,随着模型架构的创新,更高质量的培训数据,更高级的培训技术以及更有效的推理系统和硬件(例如新一代GPU和ASIC芯片),AI模型的推理成本将继续继续衰退。
最终,这将释放AGI的潜力。
谁将赢得AGI比赛
最后,几次大投篮预测,他们将成为AGI比赛的最终冠军。
Google似乎是领导者,因为其基础设施优势。
但是在公众舆论领域,Openai似乎是领导者。它已经处于商业化的最前沿,目前在AI领域的收入最高。
目前,谁在AI领域赚钱,有人在赚钱吗?

在大型球员上市之后,他们发现从财务报表中,微软在AI领域实现了盈利能力,但在基础设施上投资了巨大的资本支出。 Google和Amazon也是如此。
Meta获得的巨额利润来自推荐系统,而不是来自Llama等大型模型。
人类和Openai显然还没有盈利,否则就没有必要继续融资。但是,就收入和成本而言,GPT-4已经开始获利,因为其培训成本仅为几亿美元。
最后,没有人可以预测Openai是否会突然倒下。但是,目前,公司将继续筹集资金,因为一旦AGI到来,AI带来的回报是不可估量的。
人们可能不需要Openai来花费数十亿美元来开发“下一个最先进的模型”,而且只需要Chatgpt级的AI服务就足够了。
推论,代码生成,AI代理和计算机使用都是未来AI的真正有价值的应用领域。谁不做努力的人将被市场消除。
参考材料:
本文来自作者:Xin Zhiyuan的微信公共帐户“ Xin Zhiyuan”,由36KR发表并授权。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/273879.html
