
朱小胡(Zhu Xiaohu)是一位著名的投资者,他去年不相信AGI(通用人工智能)的投资叙事,他在整个春节都被DeepSeek统治后改变了自己的态度。 “ DeepSeek即将使我相信Agi。”
在最近对Tencent News的采访中,朱小胡胡(Zhu Xiaohu)一再惊叹于内容一代中的深度和深度。
不仅是朱小胡胡。在DeepSeek用假的假货和模仿Liang Wenfeng的语气回应了Feng Ji的假“国家财富理论”之后,作家和脱口秀演员Li Dan评论说,这篇文章揭示了非常详尽的味道。李丹总结为“技术抒情诗歌”。
更重要的是,除了美丽和深度外,DeepSeek还允许更多的普通人首次体验AI对话产品的易用性。
在此之前,如果用户想制作AI对话产品(例如ChatGpt)输出更准确的答案,则他们通常需要学习一组更复杂的提示(提示)技术,但是在DeepSeek上,用户只需要输入一个简单的自然语言即可能够获得相对准确的响应,这些答复也可以显示拟人化的特征。
DeepSeek对人类情感价值的精确掌握曾经使其以“讽刺”的中国10级表演获得了“ Cybert's Suttute”的声誉。
飙升的用户数据已成为外界追求DeepSeek的另一个证明。 AI产品列表中的统计数据表明,启动DeepSeek申请后的20天,其DAU(日常活跃用户)超过2000万,并且临近,成为具有日常活动的第一AI对话应用程序中国用户。
尽管DeepSeek坚持使用开源路线,但DeepSeek并未在其最新的R1模型上透露其预培训的语料库,该模型引起了激烈的讨论,这也使外界对其美丽而华丽的写作风格感到好奇。
字母列表(ID:Wujicaijing)首先将此问题扔给了DeepSeek,该问题从诸如风格化的数据蒸馏系统,动态风格转移体系结构和对抗性增强学习框架等维度中提供了自己的解释。
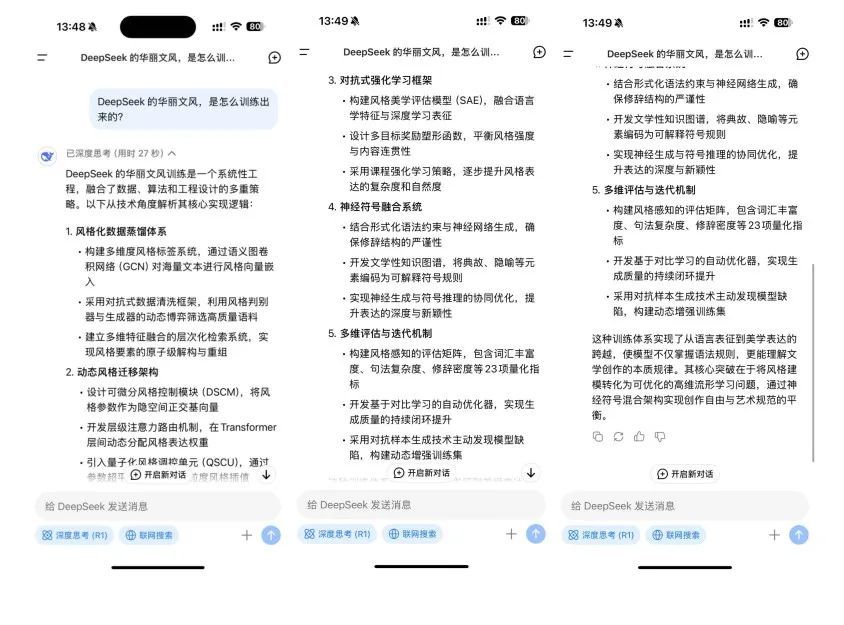
此后,字母表立即试图使前三名国内每月活跃用户(DeepSeek除外)回答。他们给出了一个共同的理由,因为DeepSeek可能在选择语料库中使用了更多的文学新颖材料。
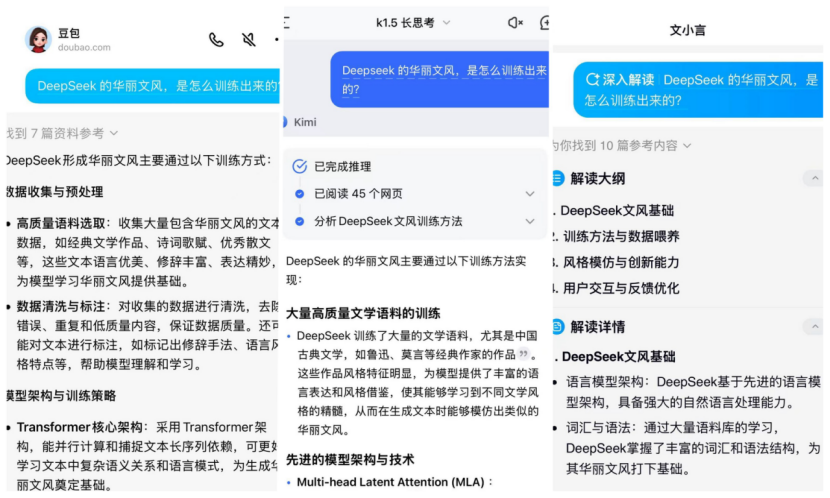
甚至朱小胡胡(Ziaohu)也推测,这可能与Deepseek团队对美丽的单词,哲学,量子力学等的偏爱有关。
DeepSeek的文学青年气质可能是他们宣布追逐Agi的宣言。 2023年4月,当DeepSeek的母公司发布了一个大型模型公告时,它引用了法国新浪潮主管Truffaut的一句话,曾经警告过年轻的导演:“一定要为野心疯狂,并为此疯狂。”真挚地。”
在中国从事大型模型企业家精神的李Zhen(假名)也做出了类似的写作风格,“这意味着风格控制的粒度不同。其他国内大型模型产品可能不如Deepseek中的善良文学标签。” Li Zhen说,告诉字母清单,根据其猜测,就文学语言比例而言,其他国内大型模型可能会使语料库的比例保持10%至20%,而DeepSeek可能高达40%。
除了不同的数据源外,如何使用数据还会影响大规模产品的内容产生效果。生成人工智能的作者,人工智能商业化的专家丁·莱(Ding Lei)博士特别提到了DeepSeek R1模型中显示的“ AHA时刻” Epiphany,也就是说,该模型学会了反映,这证明了其不断增长的推理能力,这也表明增强学习可以带来复杂甚至意外的结果。”
无论是风格控制粒度的认知能力,还是“ AHA时刻”顿悟的到来,DeepSeek的高才能密度支持都是必不可少的。
在高密度和自主权方面,参加大型模型投资的亨格资本的创始合伙人江伊认为这是DeepSeek一代美丽而华丽的写作风格的第一个因素。 “相比之下,大型模型公司的一些员工在自主权方面不够开放,这使他们在大型模型产品的研究和开发中更具针对性,而最终一代效应是公平的。”

DeepSeek生成的内容的优点之一是建立一个相对独特的文学增强数据生态系统,也就是说,将自然语言生成转变为可控制的样式系统,以便可以将文学创作领域的专业评估系统转化为相应的系统。功能,从而构建样式表示的数学建模。
为了实现上述效果,与其他国内大型模型相比,DeepSeek需要在数据标签中更详细和多样化。这也是国内大型企业家李Zhen叹了口气的原因,DeepSeek文学更多地是关于标签的原因。
去年3月,当他被邀请参加NVIDIA GTC 2024会议时,DeepSeek研究人员发表了题为“危害但差异:大语言模型价值观的一致性:大型模型价值和人类价值观的一致”,它提到,DeepSeek建立了一个跨学科的专家团队,该团队对具有不同社会背景的人的共同价值观进行了分类研究,从而构建了三级标签价值分类系统。
人工智能商业化专家丁·莱(Ding Lei)博士告诉信清单,除了数据注释外,早期数据质量对于模型培训至关重要。 “ DeepSeek是在长时间链接数据的收集和注释中,推理和非推理数据等。它具有独特的东西。”

根据官方技术报告,就获得高质量数据而言,R1模型使用数据蒸馏技术(蒸馏)生成的高质量数据,从而提高了培训效率。这也是DeepSeek实现性能与具有较小参数的OpenAI O1模型相当的能力的关键因素。
Ding Lei博士进一步解释说,模型参数的大小与最终模型所呈现的效果之间,两个“输入输出”不是比例的,而是非线性...数据主要只是定性的,更重要的是,它随着数据的增加,研究团队的数据清洁也会增加。
Google是过去的教训。无论是在计算能力还是算法方面,Google都不比Openai差,而且更强大。但是,正是由于基于人类反馈的数据培训增强了,Openai终于在Google面前进行了Chatgpt。
即使现在,Chatgpt已经在出生后已有两年多了,该行业中的一些大型模型公司仍在数据培训过程中具有机会主义行为,例如“使用数据注入方法,直接喂养尚未标记为大型大型数据模型。 。” Li Zhen说。
即使在李Zhen看来,不同的数据处理方法在训练范式中也使DeepSeek具有世代的差距优势。一些国内大型模型是更常见的语料库和基本过滤,可以完成培训前的工作,“ DeepSeek可能已经加入了。对抗数据清洁过程。” Li Zhen说。
DeepSeek确实正在进行对抗性测试。在去年3月的演讲中,研究人员DeepSeek曾经说过,在实际模型生产过程中,该模型将在内部开发,也就是说,在每一轮培训之后,将有一个独立的测试团队,为模型提供各种模型尺寸。该页面上的安全性经过了全面测试,并提供了反馈,以指导下一个周期的数据迭代和模型培训。”
不同的训练方法还导致了大型模型的完全不同的呈现,最终使用同一中国语料库进行了训练。
此外,在将R1模型添加到RL(增强学习)之后,强化学习时间的培训时间也可能导致不同的最终写作风格。 Li Zhen介绍了DeepSeek的PPO(加强学习)迭代赛可能在50到80之间,其他国内大型模型可能约为20。
不同回合的原因之一是每个公司对产品功能有不同的赌注。朱小胡胡与厨师烹饪的比喻,“就像厨师一样,将来会有几位米其林厨师,其中一些擅长于四川美食,有些擅长于广东话。权重将导致答案的差异。”

除了华丽而美丽的写作风格外,DeepSeek生成的内容的惊人之处在于,就表达而言,科学和抒情散文诗的主要先决条件是首先确保所产生的内容具有更高的事实准确性。
在Ding Lei博士的观点中,有两个原因:一个是模型的自我发展,该模型学会通过更多的推理计算来解决复杂的任务。这不是来自外部设置,而是该模型学习。另一个是模型的“ AHA时刻”顿悟的时刻,即该模型学会“反映”,证明了其不断增长的推理能力,还表明增强学习可以带来复杂甚至意外的结果。
基于DeepSeek R1模型,该官员还同时启动了R1-Zero模型,该模型直接应用于基本模型,而无需依赖SFT(有监督的微调)和标记的数据。
以前,OpenAI的数据培训在很大程度上依赖手动干预,其数据团队甚至内置了不同的水平。数据量很大,并且所需的浅数据已移交给廉价的外包工人,例如肯尼亚,高级数据已移交给高级数据。许多标记更高质量的人都是学院和大学中训练有素的博士生。
但是结果之一是,它具有高数据采集成本,并且面临着数据标记质量不平衡的问题,这限制了大型模型的规模概括能力。
R1-Zero的出现正是DeepSeek通过纯机器学习解决上述问题的主要尝试。困惑首席执行官Alavin Srinivas评论说:“需求是发明的母亲。因为DeepSeek必须找到解决方案,因此最终创造了更有效的技术。”
在DeepSeek共享的R1模型技术报告中,团队在加强学习推理阶段意外发现了“ AHA时刻”顿悟,这表明该模型本身开始在某个时刻反思自己。例如,在求解数学方程时,该模型将积极纠正早期错误步骤,并可以逐渐学会根据训练分配更多的思维时间,并生成更长的推理过程以解决复杂的问题。

这种“尖峰”现象的出现不能与特殊奖励机制的指导分开。根据官方技术文档,DeepSeek R1模型不使用MCT(Monte Carlo Tree搜索)型技术,而是使用PPO算法下使用基于规则的特殊奖励功能,该功能根据的格式和正确性是根据生成的输出。奖励通常包括三种情况:
如果输出以指定格式提供最终答案,并且是正确的,则将获得+1奖励;
如果输出提供了最终答案但不正确,则奖励设置为-0.5;
如果输出未能提供最终答案,则将奖励设置为-1。
“我们没有直接教模型如何解决问题,而只是给它正确的动机,以便该模型可以单独找出对问题的高级解决方案。” DeepSeek官员解释说。

无论是建立风格表现形式的数学建模,还是促进“ AHA时刻”顿悟的出现,DeepSeek对才能的强调和培养都与DeepSeek无可分割。
江耶资本的创始合伙人江伊(Jiang Yi)的观点,他参加了大型模型投资,DeepSeek的高才能密度,再加上内部才能的高度自主权,”导致DeepSeek内部多样性的出现,并筋疲力尽。一个选项是最好的选择,最后选择了当前的华丽和美丽的写作风格。
上述人才特征也可以通过Liang Wenfeng的外部采访来确认。在接受36KR的采访中,Liang Wenfeng曾经提出DeepSeek Management遵循自下而上的模型,每个人都没有上限的纸牌和人转移。 “如果您有一个主意,每个人都可以在未经批准的情况下随时致电培训集群的卡。”
DeepSeek V2模型是去年5月首次发动行业价格战的公司,是MLA(公牛的新潜在关注机制)建筑,这是技术创新之一,它来自年轻研究者的个人利益。
当时,在总结了注意力结构的一些主流变化之后,这位年轻的研究人员突然有了设计替代解决方案的想法。 DeepSeek为此组成了一个特别团队,并花了几个月的时间实施MLA。
在科学和技术领域,自信是创新的主要先决条件,而Liang Wenfeng认为,这种信心在年轻人中通常更为明显。因此,DeepSeek主要是一群来自顶尖大学的新鲜毕业生,来自尚未毕业的PhD 4和PhD 5的实习生以及一些仅毕业几年的年轻人。
“如果您追求短期目标,找到现成的和有经验的人是正确的。但是,如果您长期看经验,经验并不重要,那么基本的能力,创造力,爱情等是更重要的。 “ Liang Wenfeng解释说。
相比之下,在江伊的观察中,一些大规模的模型公司在员工中表现出更强的控制权,而员工缺乏自主权,“他们显示出更有针对性的研发特征,也就是说,部门确定了实现最终成就目标,并且已经实现了最终的成就目标。每个人都在努力履行职责,以便最终模型所产生的效果似乎是公平的。”
但是,应该指出的是,尽管DeepSeek产生的美丽写作风格受到某些人的喜爱,但它也开始引起某些人的警惕。乍一看,这些内容看起来不错,但是“如果您仔细阅读它们,您会发现许多语法错误。”内容是专业的王Xu告诉字母列表。
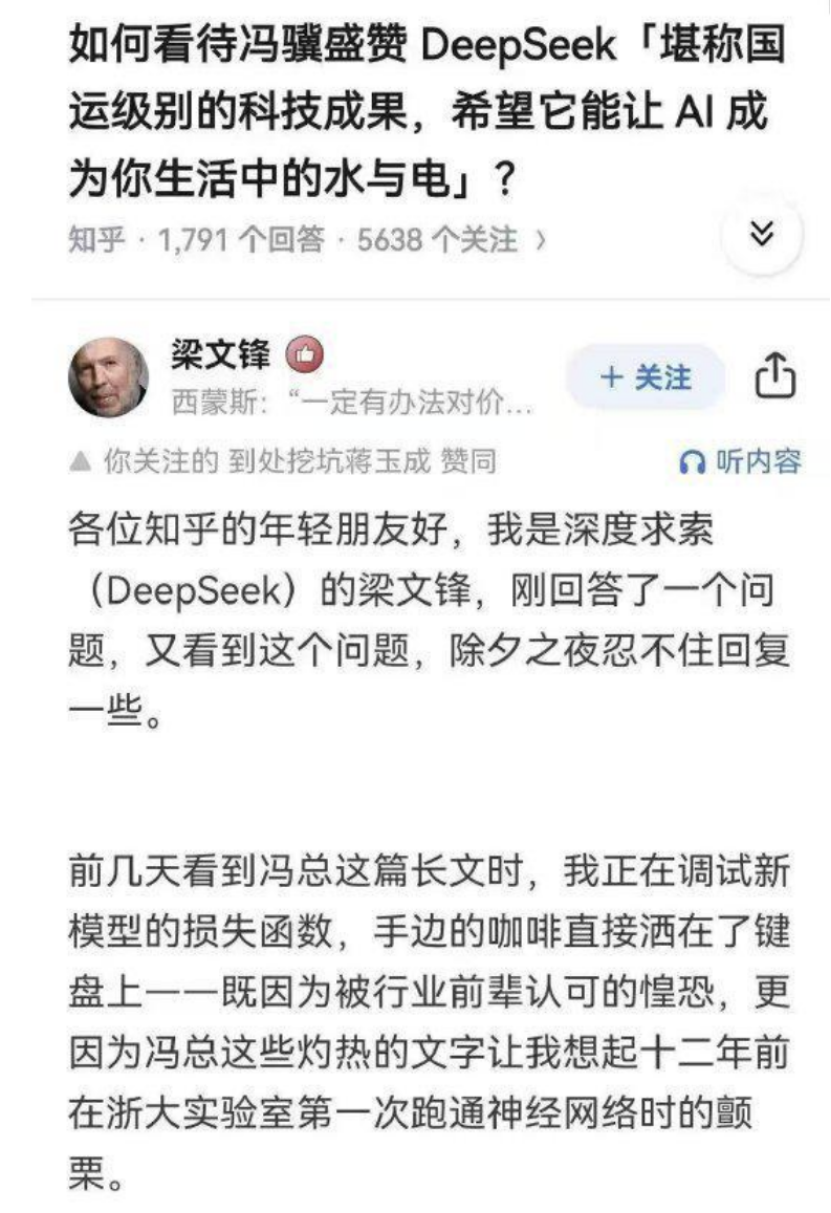
以虚假的文章Liang Wenfeng回应了Feng Ji的赞美为例,其中有一个句子:“这不仅是因为害怕被行业的前辈认可,而且还因为Feng先生的燃烧的话使我提醒我在智格大学的实验十二年前。
与语法疾病相比,不太明显的是,借助更现实和拟人的写作风格,DeepSeek的幻觉现象仍然存在。
当王Xupin读到语法问题时,“这不仅是因为害怕被行业的前辈认可,而且还因为冯先生的燃烧的话使我想起了我第一次跑到吉安格的神经网络时的颤抖十二年前的大学实验室。”乍一看,DeepSeek不仅提供了场景细节,而且还提供了特定的时间节点,这使人们相信这些都是实际发生的图片。
但是,简单地搜索了梁·温芬(Liang Wenfeng)的简历,这表明,2013年,十二年前,莉安格·温芬(Liang Wenfeng)毕业于郑明大学(Zhejiang University)已有三年的历史了。那时,梁·温芬(Liang Wenfeng)和他的千江大学同学徐金(Xu Jin)共同创立了杭州·杰奎琳投资管理公司(Hangzhou Jacqueline Investment Management Co.,Ltd.
随着大型模型显示可靠性的能力变得更强大,它们令人困惑的一面也会提高。作为人类,我们可能是时候学习如何在区分AI内容时如何提高我们的可靠性了。
参考:
“朱小胡胡的现实主义故事一周年:“ deepseek几乎让我相信agi”
“世界已经引发了深索克的复兴!硅谷巨人神话崩溃了,30位目睹了Ah ha时刻” Xin Zhiyuan
“危害与差异:大语模型的价值对齐和脱钩” DeepSeek
“疯狂的幻想广场:通往无形AI巨人的模型的道路”暗潮
“朱小胡胡与福尚,大型模型中的企业家精神的两个共识”字母列表
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/274055.html
