
Li Feifei的团队在16 h100时只花了26分钟的培训,而训练有素的模型超过了O1-preview,并震惊了该行业。
可以说,DeepSeek-R1已将全球AI模型带入了推理的新时代。
即使使用其培训方法GRPO,AI开源行业也开始了一场竞争:看看谁可以以最低的成本重现AI的“ Ahha时刻”。
刚才,DeepSeek-R1的推理成本被完全消除了!
开源项目Unsploth AI带来了好消息。您可以在没有云服务的情况下在本地体验“啊哈”。时刻:
DeepSeek-R1的推理现在可以在本地设备上复制!只需使用7GB的VRAM,您就可以体验“啊哈”的时刻。不足以将GRPO培训所需的内存降低80%。 15GB的VRAM可以将Llama-3.1(8b)和Phi-4(14b)转化为推理模型。

正确阅读:只有7GB VRAM GPU可以在本地体验“ aha时刻”。
AI的“ AHA时刻”是什么?它的功能是什么?
任何熟悉人工智能的人都知道,对于人类而言,这很简单,对于人工智能来说可能很困难。例如:
哪一个大于9.11和9.9?
但是,在经历了“ aha”时刻之后,AI模型PHI-4可以完成此类问题:从没有推理能力的模型中,它转变为与DeepSeek-R1相同的推理模型,而原始思维链和原始思维链和显示推理过程的种类。呢

原始链接:
简而言之,如果您现在有输入和输出数据(例如问题和答案),但是如果没有COT或推理过程,则可以见证Grpo-创建的奇迹
它可以为您创建推理过程,甚至可以做更多!
现在,这种方法在AI社区中变得很流行,讨论越来越大。
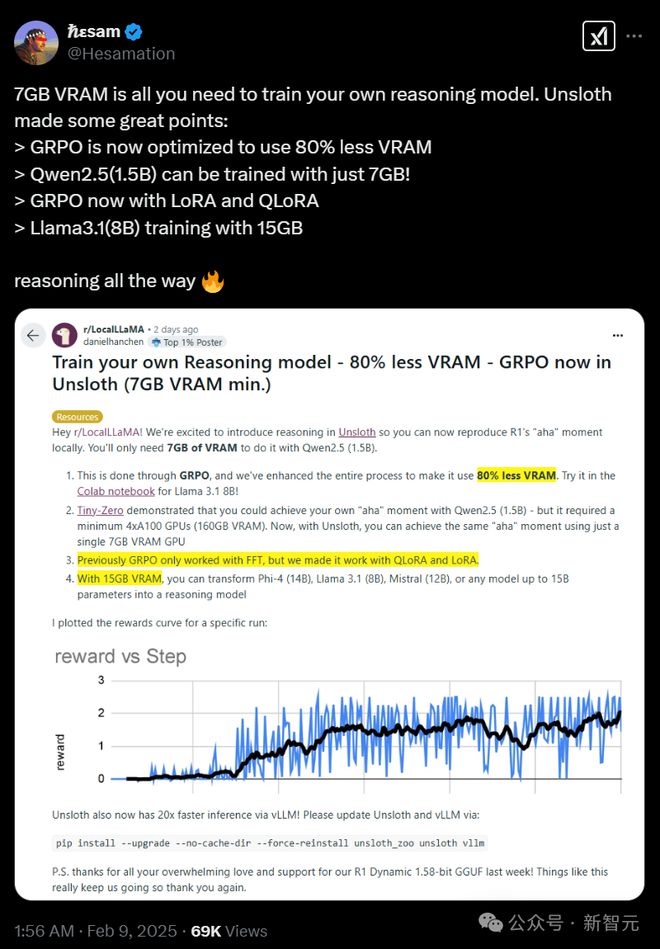
不舒服启动推理功能
DeepSeek的R1研究揭示了“啊哈”的时刻。通过小组相对策略优化(GRPO),R1-Zero自动学习如何在没有人类反馈的情况下分配更多的思维时间。
Unsploth增强了整个GRPO过程,与拥抱的脸部+FA2相比,VRAM使用率下降了80%。
这意味着只能使用QWEN2.5(1.5B)来重现R1-Zero的“ AHA”力矩的“ AHA”力矩。

项目链接:
对于包含其他模型的GRPO,请参见以下文档。
文档链接:
这次,不舒服的更新主要增强了GRPO对DeepSeek-R1-Zero增强学习训练方法的支持,从而减少了内存使用情况。
主要亮点如下:
15GB VRAM:使用Unsploth,您可以将最多15b参数的任何模型(例如Llama 3.1(8b),Phi-4(14b),Mistral(7b)或Qwen2.5(7b)转换为推理模型。
最低限度仅为7GB VRAM,足以在本地训练自己的推理模型。
Tiny-Zero团队曾经表明,使用QWEN2.5(1.5B)可以实现“ AHA”矩,但需要2个A100 GPU(160GB VRAM)。而现在,只需使用7GB VRAM GPU就可以实现相同的效果。
以前,GRPO仅支持完整的微调,但是现在它可以与Qlora和Lora一起使用。
请注意,这不是对DeepSeek-R1蒸馏模型的微调,也不是使用R1蒸馏数据进行调整(Unsploth已经支持)。实际上,该项目使用GRPO将标准模型转换为“全血”推理模型。
GRPO的应用方案:具有奖励机制的定制推理模型,例如法律和医学;需要显示推理链或思考过程的其他情况。
Grpo带来的“啊哈”时刻
在使用纯强化学习(RL)训练R1-Zero时,DeepSeek观察到了神奇的“ AHA时刻” -
没有任何人类的指导或预定义的说明,该模型实际上开始重新评估其初始方法并学会了延长思维时间。
即使您仅使用GRPO在100个步骤中使用GRPO训练PHI-4,结果也很清楚:没有GRPO的模型没有思想的象征性,并且经过GRPO培训的模型具有思想的象征性,正确的答案是获得!

纸链接:
这个“ AHHA时刻”表明,GRPO不仅有助于模型提高其推理能力,而且还允许模型在没有外部提示的情况下学习反思和调整,从而提高了解决问题的质量。
回到一个问题“哪个更大,9.11或9.9?”,在GRPO培训之前,PHI-4介绍了如何从左到右比较小数
经过GRPO培训后,PHI-4可以正确分析和回答这个问题,而推理过程是明确而严格的 -
在推理过程的第二步中,基于TENS的比较,获得了正确的答案。在第三步中,仍比较了9.11和9.90的百分位数,但是这次AI模型发现比较百分位数不影响步骤2中获得的结果。

PHI-4在GRPO培训之前和之后进行了比较,提示是:“哪个更大?9.11或9.9?”
这是Grpo的“魔力”。
GRPO是一种增强学习(RL)算法。与近端策略优化(PPO)不同,它不依赖价值功能,并且可以更有效地优化模型答案的质量。
在项目的笔记本中,使用GRPO培训模型可以独立发展自我验证和搜索功能,从而创建一个迷你“ aha mist”。
GRPO的一般过程如下:
1该模型生成多个答案组2根据正确性或其他集合奖励功能(与使用LLM作为奖励模型不同)的答案3计算该组4中答案的平均得分分数的组内比较5增强了模型对高分答案的偏好
例如,假设模型需要解决以下问题:
什么是1+1? >>思想链/锻炼>>答案是2。什么是2+2? >>思想链/锻炼>>答案是4。
最初,必须收集大量数据以填补工作/思维链。
但是,GRPO(DeepSeek使用的算法)和其他RL算法可以指导模型自动演示推理功能并创建推理轨迹。
RL不需要数据,而是需要精心设计的奖励功能或验证器。例如,如果得到正确的答案,请给出1分。如果某些单词拼写错误,则得分为0.1。等等。
强大的联合:在不舒服中使用grpo
如果您在本地使用GRPO进行培训,请先安装必要的依赖项:PIP安装扩散器。
培训技巧:耐心等待至少300个步骤,以了解奖励分数的显着提高;为了确保最佳兼容性,请使用最新版本的VLLM。
COLAB示例仅接受了1小时的训练,结果相对平均。为了获得高质量的结果,建议训练至少12小时(但可以随时停止)。
较小的模型可能无法生成思维令牌。建议使用至少1.5b参数模型正确生成“思考令牌”。
如果使用基本模型,请确保加载正确的聊天模板(避免格式化问题)。
Unsploth现在具有内置的GRPO培训损失跟踪,消除了对外部工具的需求(例如WandB)。
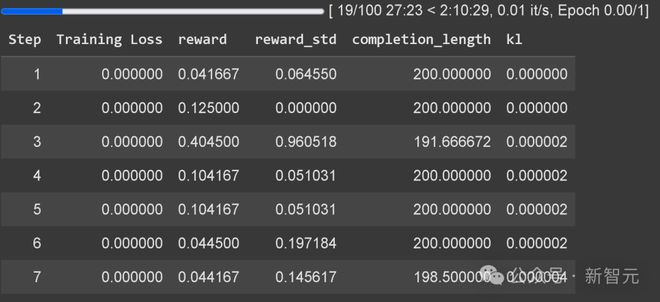
内置的GRPO培训损失跟踪示例
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/274064.html
