
[文本/观察者网络专栏作家Pan Gongyu]
DeepSeek具有“小按钮和大声音”。在半年多的时间里,它不仅从LLM通用模型的V2迭代到V3,而且还进一步启动了R1模型,重点是推理能力。从培训成本,建筑调整和开源模型中,技术震惊了世界,并引发了海啸的赞誉。在春季音乐节期间,大海的资本市场上的急剧波动以及一年初后的国内“ DeepSeek概念股票”的急剧上升使这一现象继续成为公众中热门讨论的重点。
DeepSeek的成功遵循了推理AI模型预训练的不可避免的演变过程。为什么DeepSeek的崛起是随后的举动?让我们先看看两个段落。
NVIDIA首席执行官詹森·黄(Jensen Huang)在去年2月下旬在接受《美国技术媒体连线》采访时说:“今天的Nvidia的业务可能是推理的40%和60%的培训,这是一件好事,因为它使您意识到AI已经意识到AI已有AI已有终于成功了。
去年12月,OpenAI的首席财务官Sarah Friar在接受技术媒体采访时说:“ Openai的Chatgpt Pro每月可向C-End用户使用200美元,这确实很便宜,这是合理的,价格应为每月2,000美元“进一步加上她的上下文采访的含义,她主要说Openai是“善良的”,并坚持AI的道德意识,以服务于公众的平等权利,因此她没有使价格如此高。如今,他们的虚伪皮肤在DeepSeek R1开源模型面前被完全撕裂了。
这两个段落是相当代表性的,一个点是AI技术应用的演变,另一个与AI培训模型实施的商业化有关。这两个级别的问题是交织和人际关系的。
正如Openai带头开发“星门”,将计算能力的规模定律扩展到私人资本市场和国家投资领域,并试图将AI行业束缚到美国国家命运时,DeepSeek也做出了叙述从火底部切断的解决方案。 。
在人群的喧嚣中,海洋另一侧的怀疑,甚至具有恶意性质的诽谤也值得关注。
分析美国AI大型模型行业的某些顶级人物的评论可以进一步加深我们对DeepSeek真正击中另一方的痛苦点的理解。众所周知的半导体咨询机构Semiarsis和Anthropic首席执行官Dario Amodei的总裁Dylan Patel代表了整个海洋的详细分析数据和质疑声音。在中国互联网世界中翻译后,这两家公司的文章已被大量翻译和重印。

人道首席执行官达里奥·阿莫迪(Dario Amodei)
他们主要试图告诉公众DeepSeek的突破并不是从四个角度来看:GPU库存,成本计算,非技术营销以及在模型数据蒸馏中不合规。
1。“灵敏度”高端GPU的DeepSeek库存
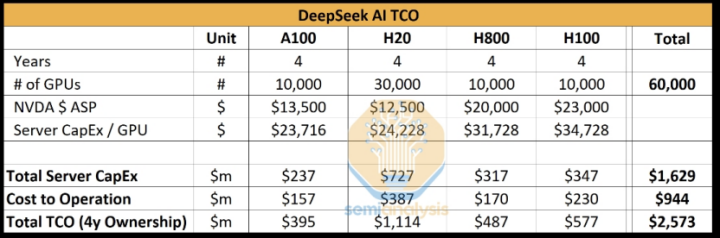
根据SemianAylsis的计算,“ DeepSeek大约有10,000 H800 GPU芯片,10,000 H100 GPU芯片和大量H20 GPU芯片。”
达里奥·阿莫迪(Dario Amodei)在一篇长文章中叙述了半耶尔斯(Semianaylsis)的计算,他们认为DeepSeek拥有NVIDIA GPU卡(cast割和非堆积版本),并使用用于培训和推理的料斗结构(约50,000)。美国大型AI模型培训机构(例如OpenAI和DeepMind)之间的差距大约是两到三次。结合基于合成数据生成和增强学习以提高推理能力的训练后方法,他认为DeepSeek最初站在巨人的肩膀上,并使用大量的GPU来实现当今的成绩。
为什么达里奥·阿莫迪(Dario Amodei)使用semianaylsis数据将自己吸引到大横幅上?
由于达里奥·阿莫迪(Dario Amodei)在他看来,他对AI培训费用有一个所谓的“摩尔定律” - 每年可以减少大约三到四次。如果使用加强学习方法调整了推理体系结构,则可以将成本降低到六到八次。 ,但这是降低成本的极限。基于此成本估算假设,DeepSeek拥有50,000张料斗卡。
因此,如果我们进一步询问,Semianaylsis认为DeepSeek手上有许多高端GPU卡,他们如何计算它?他们使用了类似于荒谬方法的推理:拟人化的训练成本仅是Claude 3.5十四行诗将高达数千万美元。如果DeepSeek采取了如此神奇的举动,为什么人类会竭尽全力在亚马逊筹集数亿美元? ?
关于关于人类如何消费投资者的钱的问题,也许马斯克的道路(政府效率部)对回答它更感兴趣。与代表云服务提供商亚马逊的拟人首席执行官Microsoft和Google相比,不禁会写长篇文章。正是他深刻意识到,基于GPU级别至100,000至数百万美元的生态系统正在促进培训。 ,他们的克劳德(Claude)系列的总价最高,总体成本效益最低。
与H100合法拥有的H800相比,H800主要是castates nvlink的通信带宽;尽管H20也是cast割版本,单一卡计算能力仅为H100的20%,但H20可以通过多卡堆叠模式及其HBM容量(96GB)。 )甚至高于A100/H100(80GB)。换句话说,H20的内存带宽可以使DeepSeek Decode阶段生成的每个令牌所需的时间小于A100和H100。
DeepSeek使用cast割版来实现禁运版本没有的影响,允许Dario Amodei发表恶意言论,以进一步加强对中国大陆的GPU控制。这可能是他对DeepSeek的批评的目的。
从话语的角度来看,半溶方法利用拟人化的缺乏公平性来训练成本,并反复推论DeepSeek绕开控制和非法持有高端GPU的潜力,而人类使用的是在沙堆上构建的推理来讨论DeepSeek的推理,没有任何非凡的问题。成本问题,这实际上是一个阴谋和循环论证。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/274209.html
