
团队的贡献
量子位|官方帐户QBITAI
兔子可以准确地感知捕食者在两只耳朵中的每一步,从而创造出一种以不同品种在世界范围内广泛分布的生命奇迹。人们还需要通过沉浸式耳朵来享受电影的视听盛宴,判断驾驶环境并感知周围的活动状况。
那么,流行的扩散生成模型是否可以直接生成符合物理世界定律的空间音频?
以前,经典的Text2audio工作可以通过文本抽象的语义生成更准确的单渠道音频。
但是,这忽略了人类天生的感知双通道音频的能力。从应用程序的角度来看,通过文本控制的多渠道音频产生在电影,电视,娱乐,AR/VR和其他领域中具有重要的应用。
在这种趋势上,为了增强文本对多渠道音频生成的控制,HKUST的北京邮政团队创新了控制声音源方向,从数据,模型和评估标准的角度将控制声源方向纳入了生成范围。
什么是空间音频产生?
什么是空间音频?
似乎能够通过声音来判断事物的方向和状态是自然人的先天能力。早在20世纪,就深入探讨了生物声学。一个人的声音的方向主要来自以下三个方面:

实施与空间音频产生有关的技术路线?
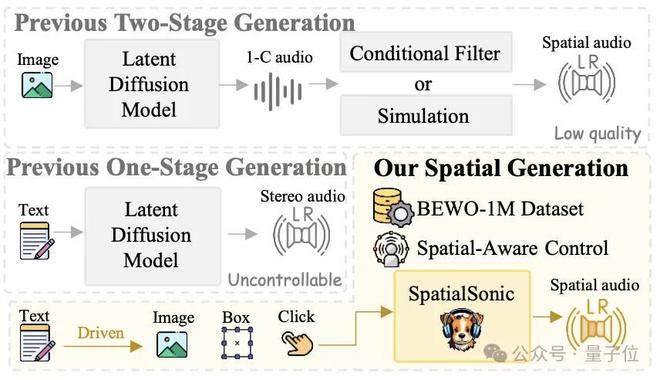
1。两个阶段解决方案:首先通过普通的文本2audio模型生成单通道音频,然后通过仿真或可学习的过滤器进行串联连接。这使多通道空间音频的最终获得。该系统显然不够强大,无法适应复杂场景的生成任务。
2。先前的单阶段解决方案:尽管这种类型的系统可以生成立体声音频,但它远非控制空间音频的控制能力。
3。本研究计划:提出了来自数据集,方法和评估指标的一站式解决方案,可以更好地改善空间音频的控制。
数据结构:允许机器“聆听所有方向”的数据工厂
在这项研究中,数据结构是整个系统的基石!
要在各个方向上生成音频,生成模型必须了解方向的差异。例如,如果您希望系统从左到右生成摩托车,则需要从左,右,从左到右向左向左向左提供摩托车音频,以使系统理解差异。以这种方式收集音频的成本显然非常巨大。为什么不建立有效的“数据工厂”?
接下来,让我们揭示Bewo-1m(两个耳朵宽1m)数据集的“生产管道”。
为什么需要bewo-1m?
如今,一般音频文本数据集缺乏明确的空间信息描述。例如,即使有双通道音频,随附的文本说明只是“汽车通过”,并且没有特定的方向信息(例如“从右前向左前驾驶的汽车驱动到左前”)。这还不够以方向感产生空间音频!
因此,需要一个具有丰富空间描述的超大双通道音频数据集,并且出现了Bewo-1m。它包含超过100万音频文本对,并支持复杂的场景,例如动态音源和多声源。
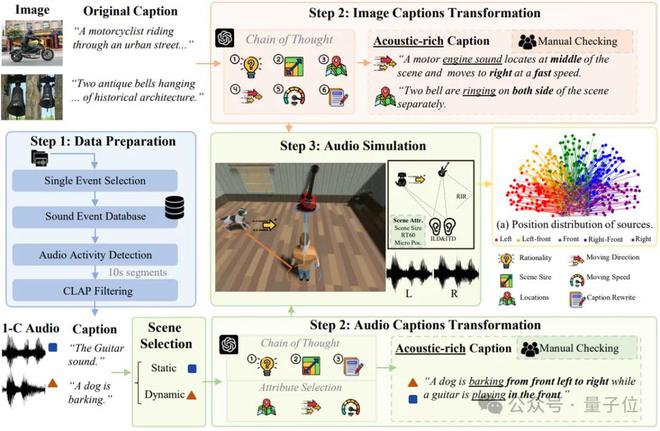
近年来,在流行的GPT-4和严格的模拟实验的帮助下,最终通过思想链构建了一个大规模的数据集,其中包含100万个音频,总计约2,800小时,包括:
单个静止:例如,“猫在左侧嘶哑。”单个动态:例如,“直升机从左到右苍蝇”。多源音频子集(双重,混合):例如,“左侧有雷声,右侧有狗的吠叫”。现实世界音频子集(现实世界):还手动标记了少数现实世界的双通道音频,以确保测试集的真实性。
一眼数据多样性:

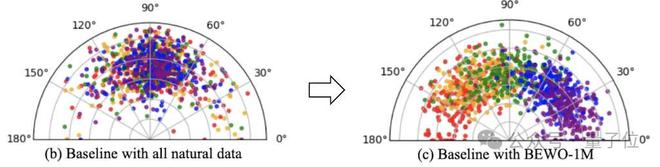
BEWO-1M当前是第一个包含方向描述的大规模双通道音频数据集。它不仅适用于空间音频生成,而且还可以扩展到空间音频字幕生成(附录.g.5),音频 - 文本检索(附录G.6)和其他任务。在实验中,发现它可以显着提高生成模型的空间控制能力,从而使机器能够真正“倾听所有方向”。
生成方法的简要说明
多亏了稳定的AI研究人员,他们开发了生成双渠道的模型。但是,这里的一代模型中存在相对明显的音频发电问题。例如:在稳定的音频中输入“左侧存在钢琴声音”,最终生成的钢琴声音的方向是无法控制的。这是因为他们的双通道音频是通过真实数据完全训练的,并且在方向上没有足够的多样性。因此,迫在眉睫的具有可控方向的音频生成模型。
可以直接使用fineTune使用Bewo-1m吗?好的!直接使用定向自然语言的propt并直接执行芬太日,该模型可以获得在指定方向上生成音频的最基本能力。对于该作者提供了由自然语言控制的Gradio演示。
但是,在方向性的自然语言理解方面有非常多样的表达方式。这些各种表达式对文本的编码者构成了巨大的挑战。对于非常经典的T5编码模型,更长的文本长度将导致更长的编码和更大的理解难度。
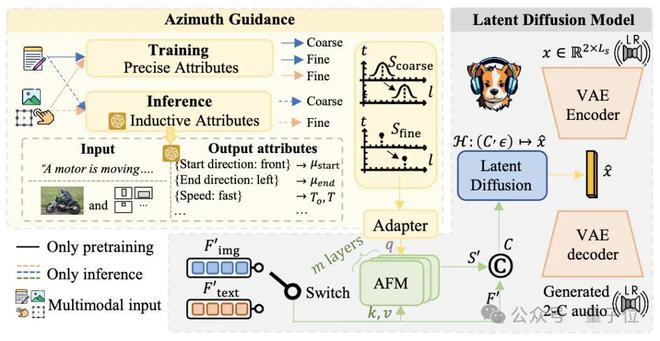
然后,还有两个非常自然的想法可以应对此类挑战。 (1)将空间控制和文本控制切换; (2)使用大型模型理解文本的能力。
脱钩空间控制和文本控制意味着增加空间控制的指导!空间控制的实施主要来自模拟培训数据。作者具有非常准确的模拟建模,因此训练期间的角度与4个小数点的四个小数位。然后,在训练过程中使用此角度是非常自然的。为此,作者提供了一个由精确方向信息控制的Gradio演示。
使用大型模型理解文本的能力,您可以使用推理和上下文学习在推理时获得可靠的方向信息(有关详细信息,请参见论文)。这个方向的手动验证最多可正确90%。
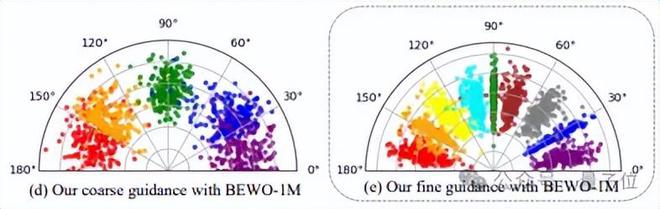
如上图所示,对可视化的音频方向的更准确控制是通过空间控制和文本解耦来实现的。与Direct Finetune相比,其控制性能的精度提高了
在实验过程中,作者发现,如果使用了极其准确的角度建模,则可以生成更精确的方向的音频,但是生成的音频语义的多样化差。因此,同时开发了粗制的建模方法以获得更多样化的音频产生,但是方向控制将是不准确的。
“差异或控制”这一代问题仍然是这里的权衡。
是否有基于大量文本音频对的数据的文本控制模型?因此,如何迁移到其他方式。此外,编码文本是T5编码。
众所周知,在当前的大型模型中已消除了T5作为编码器+解码器模型。研究团队只是使用他的前任的VL-T5来实施简单的图像空间音频生成,这只是为社区提供简单而粗糙的图像引导的音频生成的基线。
评估和结果
为了与其他模型进行比较,研究团队在语义和声音源方向上开发了各种评估算法。
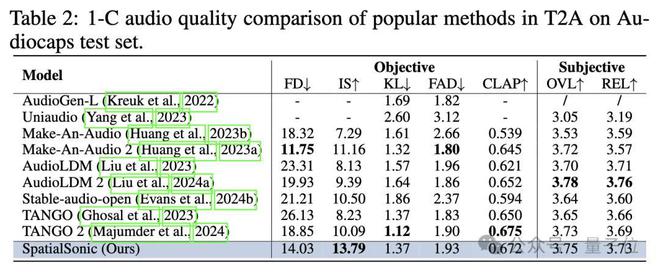
在语义层面上,Text2audio生成的评估算法仍然有效。作者直接评估了声带平均水平之后的语义水平相似程度。下表显示,基于单通道模型的评估标准的空间模型的评估仍然具有某种高级性质。
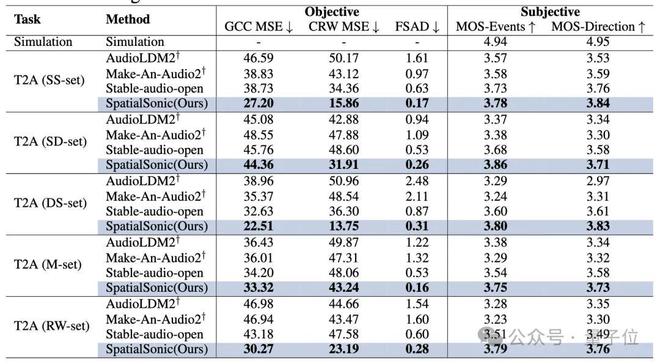
在声音源方向层面上,研究团队首次创新提出了通过ITD查找方向错误。根据背景,人们主要使用IT来判断对象的近似取向,而ITD也被用作评估方法。
以前的ITD评估通常来自两种方法:
传统信号方法:GCC-PHAT深度学习方法:立体con
本文使用这两种ITD评估方法来开发两个音频段(GCC MSE,CRW MSE和FSAD)中不同程度评估ITD的算法。这些指标通过模型在文本引导的空间音频产生中的优势得到很好的证明。
由于音频本身的耦合性质,研究团队坚信,这不是产生音频相似性的评估算法的最终形式。该团队将继续在GitHub上更新更好的算法。有关更多实验结果,请参阅论文。
如果您对以下问题感到好奇,请在论文中寻求答案!
1。参与程度会影响音频产生的质量吗? (附录.g.9)
是的。作者发现,增加方向的中间距离之间的偏差越大,生成的音频的质量将逐渐下降。例如,就质量而言,纯净的左
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/274294.html
