
大模型动辄有着百亿、千亿的参数,并且正在一路向前狂奔,然而“小而美”的模型也在散发着光芒。
2024 年底,微软正式推出了 Phi-4。Phi-4 是在同类产品中表现极为出色的小型语言模型(SLM)。它仅仅使用了 40%的合成数据,而参数数量为 140 亿的 Phi-4 在数学性能方面击败了 GPT-4o。
微软刚刚隆重介绍了 Phi-4 模型家族的两位新成员。一位是 Phi-4-multimodal,它是多模态模型;另一位是 Phi-4-mini,它是语言模型。Phi-4-multimodal 对语音识别、翻译、摘要、音频理解和图像分析进行了改进。Phi-4-mini 是专门为速度和效率而设计的。两者都能够供智能手机、PC 和汽车上的开发人员使用。
项目地址:
在技术报告中,微软对这两个模型进行了更加详细的介绍。
这家公司的首个多模态语言模型是 Phi-4-Multimodal 。微软称:“Phi-4-multimodal 标志着我们人工智能发展进程中的一个新的里程碑。”
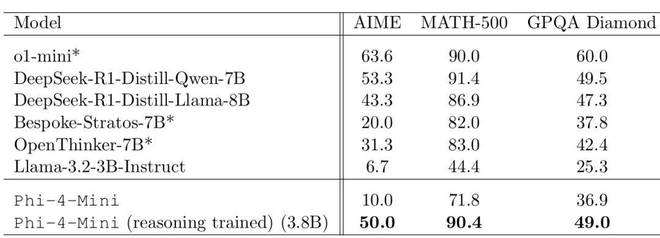
微软进一步训练了 Phi-4-Mini 来提升其推理能力。结果表明,它与 DeepSeek-R1-Distill-Qwen-7B 以及 DeepSeek-R1-Distill-Llama-8B 等规模更大的先进推理系统具有同等水平。
接下来,让我们看看技术细节。
模型架构
模型使用 tokenizer o200k base tiktoken ,其词汇量为 200,064 个。此模型旨在更高效地支持多语言和多模态输入与输出。所有模型均基于仅解码器的 Transformer ,并且支持基于 LongRoPE 的 128K 上下文长度。
语言模型架构
Phi-4-mini 是由 32 层 Transformer 构成的。它是专门为速度和效率而进行设计的。Phi-4-Mini 还具备一些特别的“省内存”方面的技巧。
分组查询注意力机制(GQA)首先发挥作用,在处理长序列时,它能够迅速聚焦于关键信息片段。这对长上下文生成时的 KV 缓存起到了优化作用。具体而言,该模型运用 24 个查询头以及 8 个 K/V 头,从而将 KV 缓存的消耗降低至标准大小的三分之一。
其次是输入与输出嵌入绑定技术,这种技术实现了资源的优化利用。并且,与 Phi-3.5 相比,它提供了更广泛的覆盖,涵盖了 20 万词汇。
此外,在 RoPE 配置里,使用了分数 RoPE 维度。这样做能确保有 25%的注意力头维度与位置无关。这种设计使得模型可以更平滑地处理较长的上下文。
Phi-4-Mini 峰值学习率的计算公式为:
LR*(D) = BD^(-0.32),
其中 B 属于超参数,D 为训练 token 的总数。通过对 D 进行调整,使其分别为 12.5B、25B、37.5B 和 50B,从而实现对 B 值的拟合。
多模态模型架构
Phi-4-Multimodal 运用了“Mixture of LoRA”这项技术,它通过把特定模态的 LoRAs 整合在一起,从而达成了多模态的功能,并且在此期间,基础语言模型被完全冻结。这项技术比现有的方法更优秀,并且在多模态基准上达到了与完全微调模型相近的性能。Phi-4-Multimodal 的设计具备高度的可扩展性。它允许能够无缝地集成新的 LoRA。这样做是为了支持更多的模态,并且在这个过程中不会对现有的模态产生影响。
该模型的训练过程包含多个阶段。其一为语言训练,此阶段包含预训练和后训练。其二是将语言骨干扩展至视觉模态以及语音 / 音频模态。
研究者使用高质量且推理丰富的文本数据来训练 Phi-4-Mini。他们加入了精心策划的高质量代码数据集,值得注意的是,这样做是为了提高编码任务的性能。
语言模型训练完毕之后,研究者将语言模型进行了冻结。接着,研究者实施了“Mixture of LoRA”技术,随后开始了多模态训练阶段。
具体而言,在训练特定模态的编码器和投影器之际,也训练了两个额外的 LoRA 模块。这两个模块可用于实现与视觉相关的任务,像视觉 - 语言以及视觉 - 语音等;还可用于实现与语音 / 音频相关的任务,如语音 - 语言等。这些任务都包含预训练阶段和后训练阶段,预训练阶段用于模态对齐,后训练阶段用于指令微调。
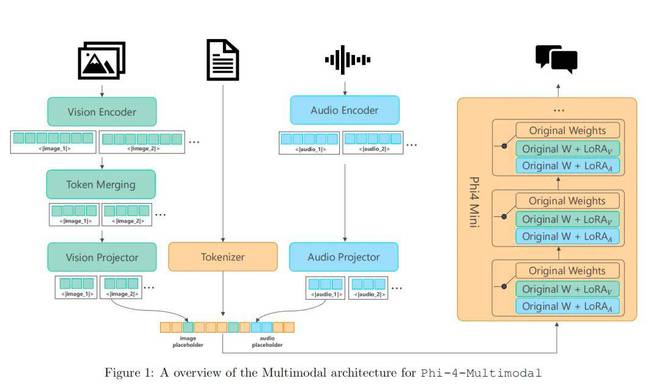
Phi-4-Multimodal 模型架构。
性能评估
Phi-4-multimodal
Phi-4-multimodal 仅有 5.6B 参数,然而它把语音、视觉以及文本处理完美地集成到了一个统一的架构里,并且所有这些模态都是在同一个表征空间内同时进行处理的。
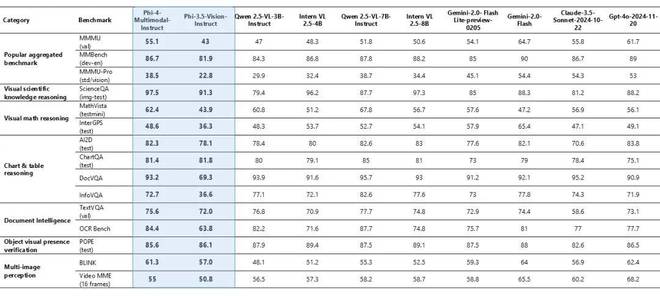
Phi-4 多模态具备同时处理视觉与音频的能力。在图表/表格理解以及文档推理任务中,以下表格展示了当视觉内容的输入查询为合成语音时的模型质量情况。与其他那些能够将音频和视觉信号当作输入的现有的最先进的全方位模型相比较而言,Phi-4 多模态模型在多个基准测试里取得了更为强劲的性能。

所列基准包含 SAi2D、SChartQA、SDocVQA 以及 SInfoVQA。对比的模型包括:Phi-4-multimodal-instruct ;InternOmni-7B ;Gemini-2.0-Flash-Lite-prvview-02-05 ;Gemini-2.0-Flash ;Gemini1.5-Pro 。
Phi-4-multimodal 在语音相关任务中展现出了优异的能力。它在自动语音识别(ASR)方面比 WhisperV3 等专业模型更优秀。它在语音翻译(ST)方面也比 SeamlessM4T-v2-Large 等专业模型更出色。该模型在 Huggingface OpenASR 排行榜上表现出色,单词错误率仅为 6.14%,名列前茅。它超过了 2025 年 2 月之前的最佳表现 6.5%。此外,它是少数能成功实现语音摘要且性能水平可与 GPT-4o 模型相媲美的开放模型之一。该模型在语音问答任务方面,与 Gemini-2.0-Flash 以及 GPT-4o-realtime-preview 等相近的模型相比存在差距。原因是其模型尺寸较小,所以在保留事实 QA 知识方面的能力较弱。
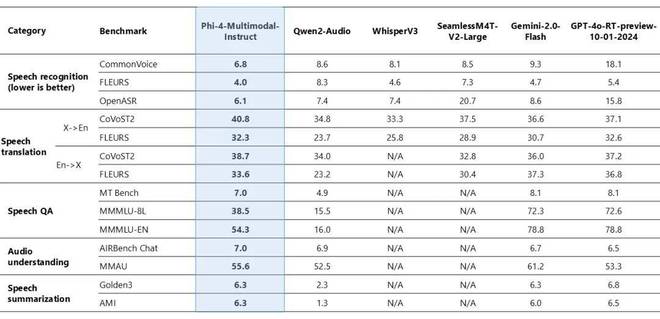
图 2:Phi-4 多模态语音基准。
在下方视频里,Phi-4-multimodal 对语音输入进行了分析,并且帮助规划了西雅图之旅。

视频链接:
Phi-4-multimodal 在各种基准测试中都展现出了卓越的视觉能力,其中在数学方面取得了优异表现,在科学推理方面也取得了优异表现。该模型规模较小,然而在通用多模态能力方面表现极具竞争力,比如在文档和图表理解、光学字符识别 (OCR) 以及视觉科学推理等方面,其表现与 Gemini-2-Flash-lite-preview/Claude-3.5-Sonnet 等相当或超过它们。
Phi-4-multimodal 展现出了强劲的推理与逻辑能力,适宜进行分析任务。参数量较为小巧这一特点,让微调或定制变得更加容易,同时也更为实惠。以下表格展示了 Phi-4-multimodal 的微调场景示例。

下方视频展现了 Phi-4-multimodal 所具备的推理能力。
视频链接:
Phi-4-mini:3.8B,小身材大能量
Phi-4-Mini 与 Phi-4-Multimodal 拥有同一个语言模型骨干网络。Phi-4-mini 体积较为小巧。它继承了 Phi 系列前作的传统。它在推理任务上超越了更大的模型。它在数学任务上超越了更大的模型。它在编程任务上超越了更大的模型。它在指令遵循任务上超越了更大的模型。它在函数调用任务上超越了更大的模型。
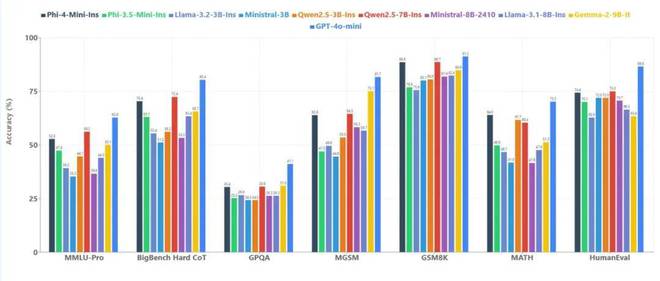
Phi-4-mini 在各种测试集中和较小模型的成绩对比
开发者们能够以 Phi-4-mini 为基础构建出一个可扩展的智能体系统。这个系统可以通过函数调用、指令跟随、处理长上下文以及运用推理能力来访问外部知识。这样就能弥补自身参数量有限的不足。
Phi-4-mini 的函数调用可通过标准化协议与结构化编程接口无缝集成。用户提出请求后,Phi-4-mini 能分析查询,识别并调用相关函数及合适参数,接收函数输出结果,将这些结果整合到最终回应中。
设置合适的数据源、API 和流程后,Phi-4-mini 能够部署在你家中,充当你的智能家居助手,帮你查看监控是否存在异常。
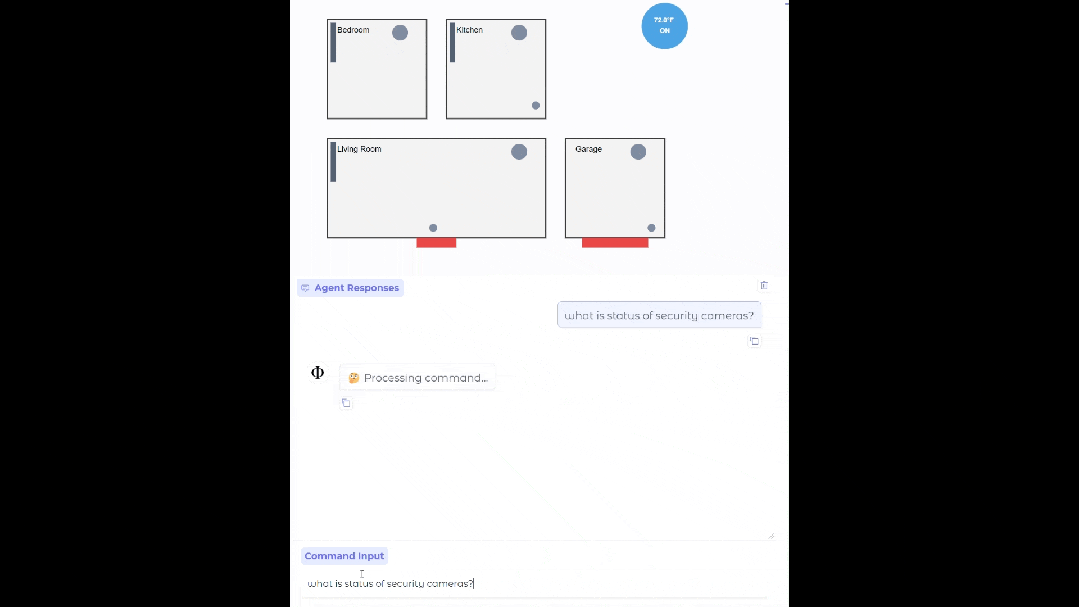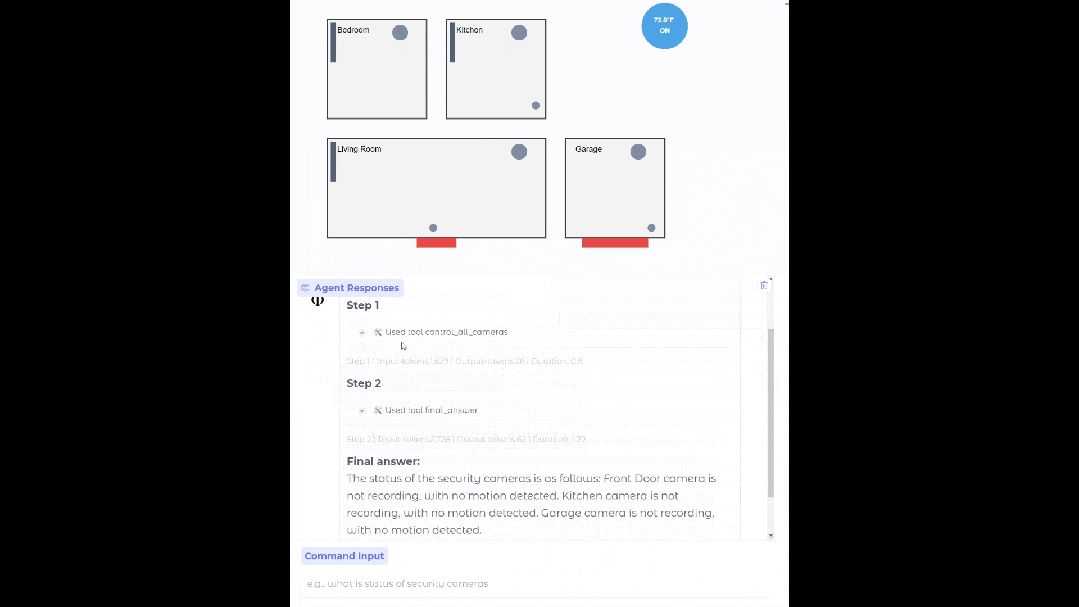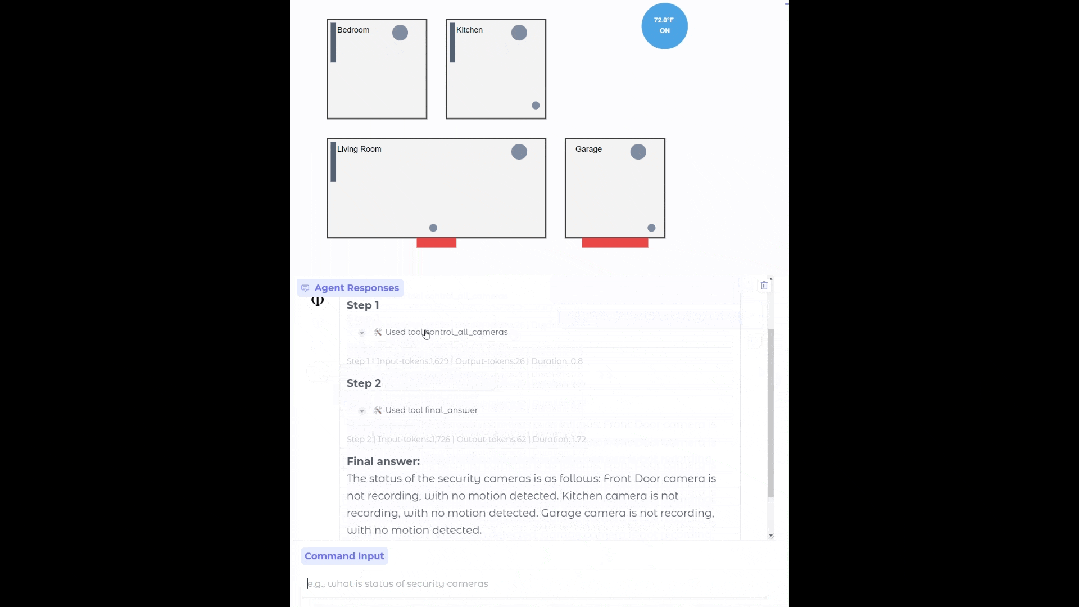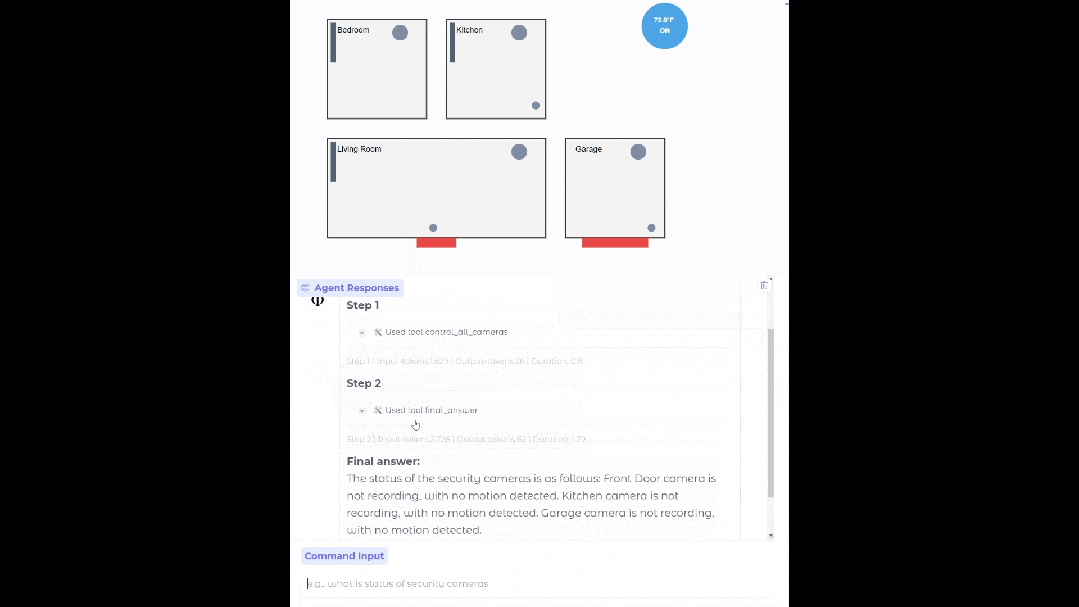
基于 Phi-4-mini 的家居智能体
函数调用借助标准化协议,能让模型与结构化的编程接口实现无缝集成。用户提出请求后,Phi-4-mini 能够分析查询,识别并调用相关函数以及合适的参数,接收函数输出的结果,再把这些结果整合到最终的回应里。构建了一个可扩展的基于智能体的系统,通过定义良好的函数接口,模型能够与外部工具、应用程序接口(API)以及数据源相连接,从而增强自身能力。下面的例子模拟了 Phi-4-mini 控制智能家居的场景。
Phi-4-mini 和 Phi-4-multimodal 模型体积较小,所以可以在计算资源有限的环境中使用,尤其是在经过 ONNX Runtime 优化之后。
训练数据
Phi-4-mini 的性能比近期类似规模的开源模型要明显更优,其中一个重要的原因在于拥有高质量的训练数据。
研究人员选择了更严格的数据过滤策略,与上一代 Phi-3.5-Mini 相比。他们加入了针对性的数学和编程训练数据,以及特殊清洗过的 Phi-4 合成数据。还通过消融实验重新调整了数据混合比例,增加了推理数据的比例,这些措施为模型带来了显著提升。
研究人员生成了大量由推理模型产出的合成思维链(CoT)数据。同时,他们采用了两种筛选方法,一种是基于规则的,另一种是基于模型的,以此来剔除错误的生成结果。他们把正确的采样答案标记为首选生成,把错误的标记为非首选,并且创建了 DPO 数据。
这些数据只是用于实验性推理模型的。因此,在正式发布的 Phi-4-Mini 版本检查点里,是没有这些 CoT 数据的。
在后训练阶段,Phi-4-Mini 与 Phi-3.5-Mini 相比,它使用了规模更大且多样化的函数调用以及摘要数据。研究人员合成了数量众多的指令跟随数据,以此来增强模型的指令跟随能力。
在编程领域,研究人员增添了诸多代码补全数据。例如,会让模型在已有的代码片段中间生成缺失的代码。这种做法对模型理解需求以及现有上下文的能力构成了挑战,同时也带来了非常明显的性能提升。
Phi-4-Multimodal 模型的预训练阶段包含多种数据集。其中,视觉 - 语言训练数据有 0.5T 图像 - 文本文档,还有 OCR 数据以及图表理解等内容。语音相关的训练数据涵盖了真实数据和合成数据,通过内部 ASR 模型转录音频,然后计算原始文本与转录之间的词错率(WER),以此来衡量合成语音的质量。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/274591.html
