

作者|王兆洋
邮箱|zywang@pingwest.com
“GPT系列不是我们前沿的模型。”
一个月前,你很难想象当 OpenAI 发布 GPT 的下一个大版本更新时,它会这样说自己。
2 月 27 日,OpenAI 突然通过一个直播发布了 GPT4.5。从这一天开始,一切都发生了变化。
GPT 的定位不再是 OpenAI 用以震撼外界的模型,它变成了一个逐渐退居舞台后方的“底座”。
它的发布不再是 OpenAI 引领行业叙事的重大举动,而是更多地带有了一种防御的意味。
这是GPT目前“最大”的一款,也是它在舞台中心的最后一舞。

OpenAI最初文档里的表述,后已删除。图源:推特
GPT4.5 的亮点简单总结如下:在于它“更大,更暖”。它是 OpenAI 迄今最大的模型,并且知识最为丰富。
OpenAI 介绍称,GPT-4.5 在多个方面超越了 GPT-4o 以及其他众多 AI 模型。比如,在 OpenAI 的 SimpleQA 基准测试里,此测试是考察 AI 处理简单、事实性问题的准确度的,GPT-4.5 的表现要比 GPT-4o 以及 OpenAI 的推理模型 o1、o3-mini 都好。
在 SWE-Bench Verified 基准测试中用于测试编程能力。它在该测试上与 GPT-4o 和 o3-mini 的表现相近。然而,它不如 OpenAI 的 deep research 以及 Anthropic 的 Claude 3.7 Sonnet。AI 在生成完整软件功能方面具有一定能力,它在 SWE-Lancer 上的表现比 GPT-4o 要好,同时也比 o3-mini 要好。
以往只会刷新榜单,而这次情况不同。这次 OpenAI 在发布时就展示了自身在榜单中的差距。在一些学术基准测试像 AIME 和 GPQA 上,GPT 4.5 在数学和科学相关问题上处于领先地位。不过,在其他多个维度的评测方面,它不及 DeepSeek 和 Anthropic 的模型。当然,这么做的原因是,它自身所开发的新一代推理模型在榜单中依然处于领先地位。
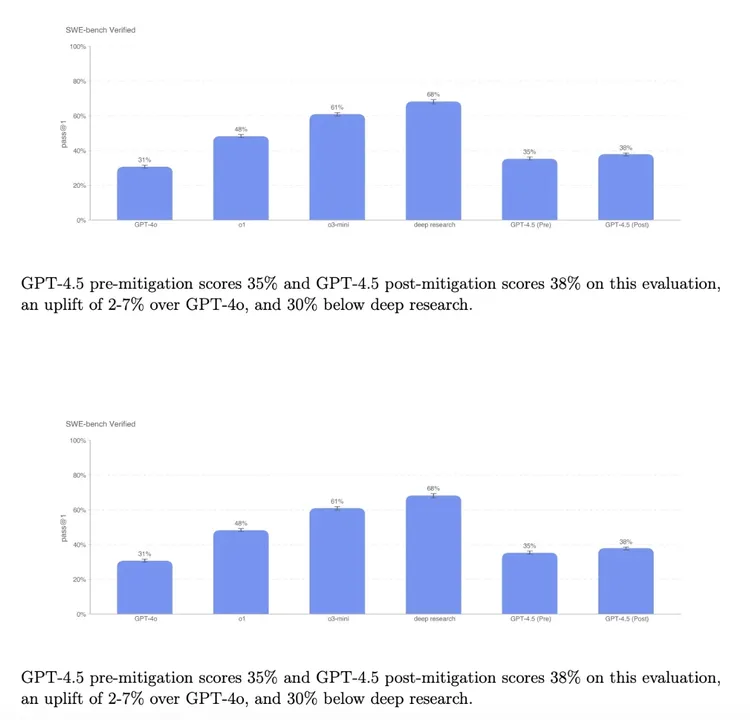
很明显,OpenAI 对 GPT4.5 的定位已不再是最强的模型。所以,基准测试也就不再是 GPT4.5 想要向外展现的重点内容了。
4. 对人工智能的发展方向有了更深入的思考和探索。
更暖,更少幻觉
GPT-4.5最引人注目的特性是“情商”的显著提升。
它通过深度学习大量的人类对话数据,一方面能够识别文本里的情绪,像愤怒、焦虑等;另一方面还可以解析情感背后潜藏的需求,并且能够生成更富有同理心的回应。
当用户诉说“朋友老是爽约”时,GPT-4.5不再死板地给出建议,而是首先给予情感上的支持,接着引导出理性的解决办法,还会借助鼓励性的语言帮助用户调整心态。这种能力是因为对语境以及情感细微差别进行了深入的剖析,而不是仅仅依靠简单的关键词匹配。
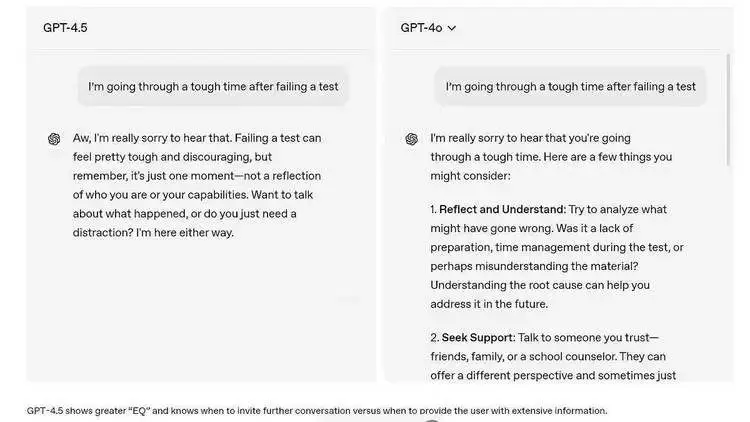
知识广度与准确性的提升
无监督学习进行了规模化扩展,据 OpenAI 研究员称,其预训练算力比 GPT-4 提升了 10 倍,不过这一点后来被官方从文档中去除了。通过这种方式,GPT-4.5 的世界知识覆盖深度有了显著增强。
在回答“海水为何是咸的”这类问题时,它能够给出结构清晰且通俗易懂的解释,还会主动增添科学不确定性,使“幻觉率”降低到 37.1%,这个比率比前代模型低很多。
这种进步体现在知识量方面,同时也体现在对用户意图的精准捕捉上。比如,能够从“我需要减肥”这句话里识别出其中隐含的健康管理需求,而不是仅仅推荐食谱。
多场景实用性的优化
GPT-4.5 在写作方面展现出更强的上下文连贯性,在编程方面也展现出更强的上下文连贯性,在日常问题解决方面同样展现出更强的上下文连贯性。它能够辅助生成创意文案,能够修复代码漏洞,甚至能够通过联网检索实时信息。
在数学和编程等深度推理任务方面提升较为有限,代码能力仅提升 7%-10%。然而,在依赖世界知识和创造力的领域,比如设计、教育咨询等领域,它的表现十分卓越。另外,多语言支持增加到了 14 种,像斯瓦希里语这样的低资源语言的表现有了显著提升,从而进一步打破了语言的壁垒。
在训练方面,OpenAI 强调了其训练方法具有高效率且规模更大。他们运用了低精度训练,并且提升了跨数据中心的训练资源的使用效率。
以上这些种种特点都难免让人想到DeepSeek。
DeepSeek R1 是一个强调逻辑推理能力的模型,然而它在文字表达方面给人带来了惊喜。GPT4.5 是一个“知识型”模型,并且开始强调它的情感能力。
在训练方面,GPT4.5采用了低精度训练这种方式,并且这种方式是“激进地”使用的。而当初 deepseek 最初公布 V3 时,引发外界震动的绝活之一几乎就是这种低精度训练。
OpenAI 为使 GPT4.5“变大”,在预训练阶段借助跨多个数据中心的计算设施进行扩展。这使人联想到 DeepSeek“起家”的技术,以及关于其自建萤火集群的一系列跨数据中心的研究论文。
OpenAI 宣称 GPT-4.5 将会成为未来推理模型的基础模型。这就如同 V3 与 R1 之间的关系一样。
DeepSeek 开源之前,OpenAI 称 GPT 系列和 o 系列是两个不同系列的模型。DeepSeek 的详细论文解释了基座模型与推理模型的关系,并且自然而然地将竞争引向了 OpenAI 和 Anthropic 最近两个模型所展现出的模型融合的路线上。

API非常贵
当我们停下来看看,这一切的变化还是很神奇的:
一个月之前不会发生这样的情况。现在,每一个在 AI 领域的重要动作,都在一定程度上被 DeepSeek 的“阴影”所笼罩。
所有迹象都显示这是一个 OpenAI 计划外发布的模型,它不能太强,不能超过它主打的 o3。然而,它又必须发布,因为 DeepSeek 带来了一波开源冲击,人人都知晓了 GPT 系列和 o 系列的紧密关系。它需要证明在基础模型上的进展,而不能仅仅依靠 o 系列来震撼大家。
OpenAI 此次发布使许多事情得以确定。例如,曾经依靠数据和计算能力扩展而实现的 GPT 系列能力增强已正式结束;它所带来的 o 系列计算时间扩展定律已正式成为后续的行业主题;同时,GPT 系列的意义从处于最前端直接参与竞争的角色,转变为在比拼推理模型时的重要支撑。
GPT 从舞台中央逐渐淡出,它的时代已然结束。随后,正式迈入了群雄竞争的推理时代。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/274634.html
