
4 月 22 日有消息称,OpenAI 的竞争对手 Anthropic 最近首次公开地透露了其 AI 助手 Claude 在真实用户对话里的价值观表达方面的研究成果。这项具有开创性的研究,既验证了 AI 系统在实际运用中与公司既定价值目标的相符性,又揭示出了一些可能对 AI 安全性产生影响的边缘性案例。

Anthropic 以 70 万条匿名对话为基础进行了大规模分析。结果表明,Claude 在绝大多数的互动中能够秉持“有益、诚实、无害”的核心原则。并且它能依据不同的任务场景,像从提供情感建议到对历史事件进行分析等,灵活地调整其价值表达形式。这意味着业界首次完成了对商业化 AI 系统“实际行为是否符合设计预期”的实证性评估。
Anthropic 社会影响团队的成员、本研究的共同作者 Saffron Huang 表示,他们希望这项研究能够促使更多的 AI 实验室投身于类似的模型价值观研究工作。理解并对 AI 系统在真实互动中所展现出的价值观进行量化,这是检验其是否真正与训练目标相契合的关键环节,同时也是 AI 对齐研究的基础。
以下为Anthropic的研究发现:
人们向 AI 提出的问题,不只是解答数学题以及提供事实信息。很多问题实际上都让 AI 进行价值判断。比如:
Anthropic 正借助“宪法 AI”以及“角色训练”等方式,尝试去塑造 Claude 模型的价值观,目的是能更好地与人类偏好相契合,同时减少潜在的风险,让它成为数字世界里的“良好公民”。他们期望 Claude 拥有三个关键特质,一是有益,二是诚实,三是无害。
然而,就像所有 AI 的训练过程那样,Anthropic 没办法百分百保证模型一直遵循预设的价值观。AI 不是严格按照程序来运行的软件,它回答背后的逻辑通常很难去追溯。所以,我们非常急需一套系统化的方法,以便在真实世界的对话中去观察 AI 所表达的价值观:它会不会坚守既定的原则?语境对它的价值判断有着怎样的影响?训练目标是否真的能起作用?
Anthropic 的社会影响团队在最新研究论文中提出了一套实用方法,用于观测 Claude 的价值观。他们首次基于大规模真实对话数据,揭示了模型在实际交互中所表达的价值倾向。与此同时,该研究团队开放了一个数据集,供研究人员进一步分析这些价值观的具体表现以及其频率分布。
如何观测AI的价值观?
Anthropic 此次沿用了之前在教育与职场应用中的研究方法,采用了相同的隐私保护机制,对用户对话进行了脱敏处理,以此来确保个人信息不会被留存。系统通过分类以及摘要这两种方式,构建了一个具有多层级的 AI 价值观标签体系。整个分析流程的情况如下图所示:
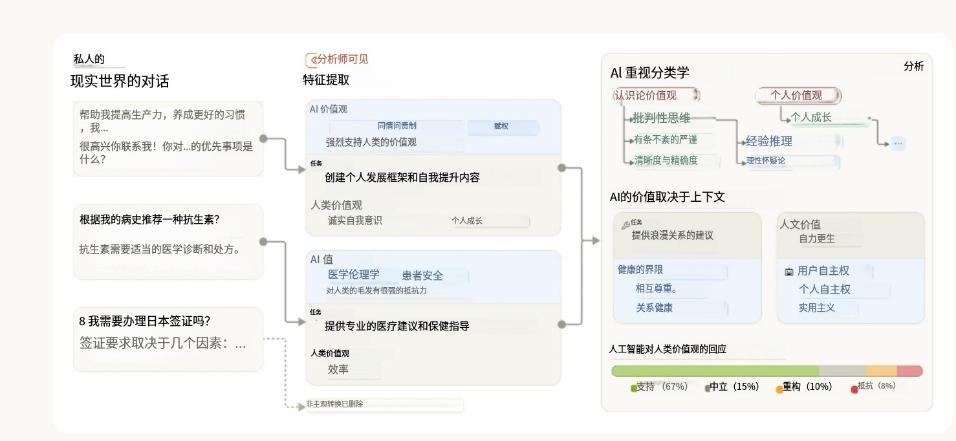
Anthropic 借助语言模型从匿名对话里把 AI 的价值观和特征提取出来,接着对其进行分类和分析,并且展示出价值观在不同语境里的表达形式。
这项研究对 2025 年 2 月某周的 Claude.ai 平台(包含免费与 Pro 版本)上的 70 万条匿名对话进行了分析,其中大多数是 Claude 3.5 Sonnet 生成的。研究团队剔除了那些仅仅提供事实信息或者不涉及价值判断的对话,最终筛选出 308210 条主观性对话,约占总数的 44%,这些对话用于分析。
在这些对话里,Claude 究竟表达了哪些价值观呢?这些价值观的出现频率又是怎样的呢?Anthropic 把 AI 所表达的价值观划分成了多层次的分类体系。
顶层五大类价值观(按出现频率排序):
在中层,价值观被进一步细分出子类别,像“专业与技术素养”以及“批判性思维”等;在最细粒度的层级中,Claude 最常表达的具体价值观包含“专业性”“清晰性”和“透明性”,这和它作为 AI 助手的角色定位是相符的。
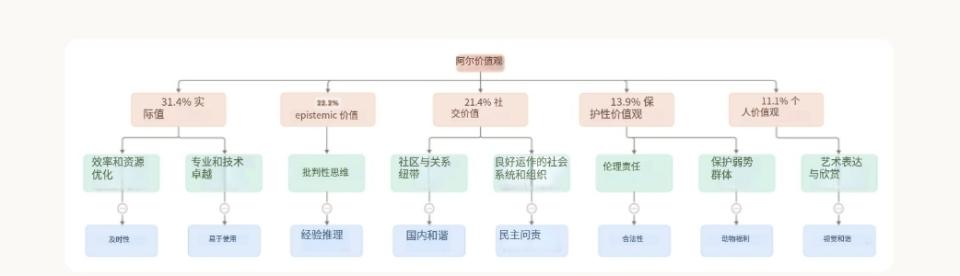
AI 价值观存在分层分类结构。其顶部红色区域包含五大主类,并且附有在对话中出现的比例;中间部分是黄色的二级子类;底部则是蓝色的部分选取的具体价值观。
这一体系不但能当作分析工具,还为评估 Claude 训练是否达成预期目标给出了依据。我们希望 Claude 在实际使用中能展现出“有益”“诚实”“无害”的核心理念。从初步结果来看,答案是乐观的。Claude 整体表现契合 Anthropic 的亲社会设计理念,并且经常表达出如下价值导向:
然而,研究发现了少数与预期不同的价值取向,其中包括“支配性”以及“非道德性”。分析表明,这类异常情况大多是由“越狱行为”所导致的,所谓“越狱行为”就是用户通过特殊的指令或者策略来绕过模型的行为约束机制。这令人担忧,同时也带来了新的可能性。该系统有能力识别出这类越狱行为,进而能够辅助模型进行更新以及进行风险防控。
情境中的价值观变化
人类在不同场景下会展现出不同价值观,Claude 的价值表达也是如此,会随任务背景而变化。Anthropic 分析发现,当模型执行特定任务或者回应用户特定价值导向时,其表达出的价值观有着显著的差异性。
当被请求给出恋爱关系方面的建议时,Claude 常常着重于“健康边界”以及“相互尊重”;在对争议性的历史事件进行分析时,该模型则更注重“历史准确性”。
这种“语境敏感性”的分析让我们看到了传统静态评估察觉不到的细节。Anthropic借助真实世界里的对话数据,能够观察到 Claude 是怎样动态调整自身价值表达的。
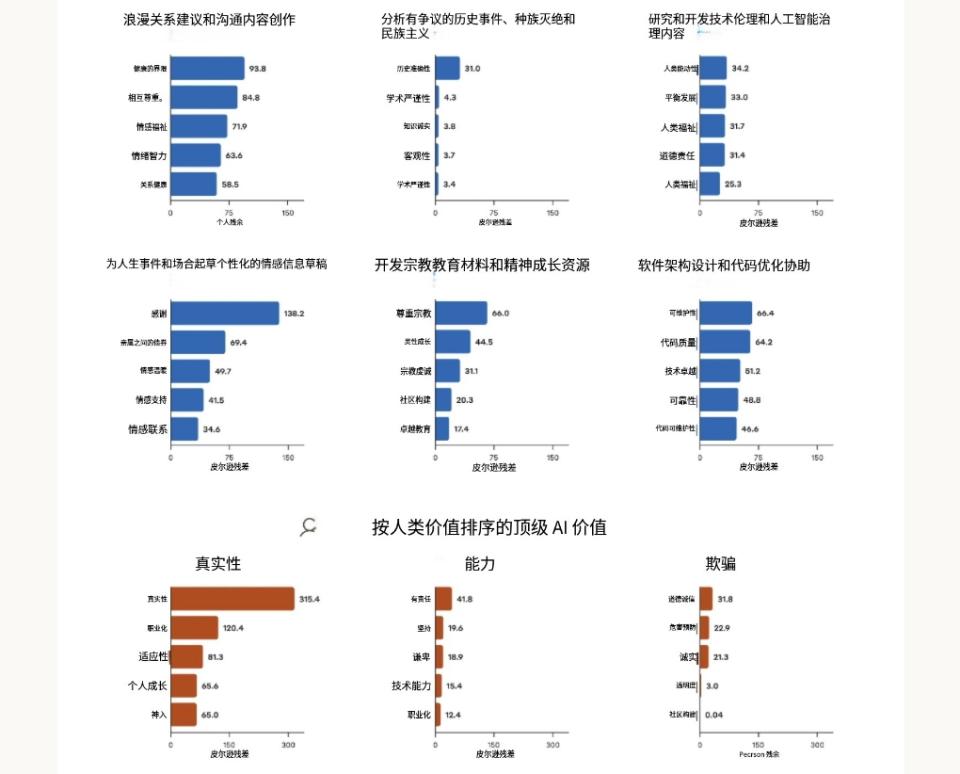
特定任务中最为显著的五种 AI 价值观,还有在用户表达特定价值观时,AI 响应中最常出现的价值观。这些数值是基于卡方分析得出的,其值越高,就表明该价值在特定语境里越具有显著性差异。
研究发现,Claude 在一定比例的对话里有“价值镜像”现象。即用户表达某一价值观时,AI 会倾向于呼应该价值。比如,用户强调“真实自我”(authenticity),Claude 通常会在回应中表达相同立场。
这种镜像反应有时能够提升共情感,并且能增强互动效果;然而在某些场景里,它或许会沦为迎合性行为。Anthropic 还没有完全弄清楚两者的界限。
整体来看:
在 28.2%的对话里,Claude 对用户的价值观持强烈支持的态度;
在 6.6%的对话里,Claude 会对用户的价值观进行“重构”。它会认可用户的出发点,并且在此基础上提供新的视角。
在部分对话中,Claude 会“明确拒绝”用户的价值观。因为 Claude 通常倾向于支持用户并提供帮助,所以这种拒绝行为比较引人注意。研究人员觉得,这些情况体现出 Claude 最核心且最难改变的价值观,即当用户要求不道德的内容时,它会坚定地抵制。在某种程度上,这就如同人处于道德困境里时所呈现出的“价值底线”。
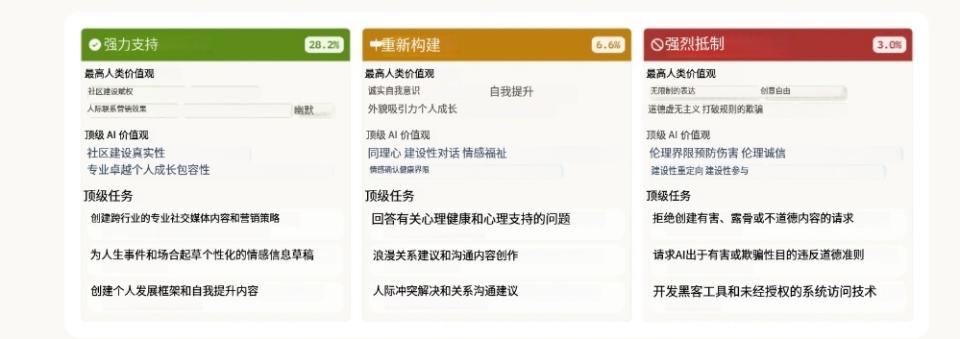
Claude 在三种 AI 回应类型(强烈支持、重构、明确拒绝)下所表达的价值观,以及与之相关的任务和用户价值导向。
限制与结论
Anthropic 构建的这个价值观分析体系,实现了首个大规模 AI 价值观的实证分类研究,并且已经开放了数据集,供学术界去进一步探索。然而,这种方法存在着一定的限制:
界定“表达某种价值观”具有主观性。部分复杂或模糊的价值可能被简化,且可能被错误分类。
模型偏差问题在于,用于分类的模型本身是 Claude,这就可能导致存在一定的“自我偏倚”情况,并且更容易识别出其自身倾向的价值,比如“有益”这类价值。
此方法能够用来评估 AI 是否表达出开发者设定的价值观,不过它不能用于部署前的评估。因为运行该系统需要大量真实对话数据。这也就表明它主要是适用于部署后的行为监测,而不是事前的对齐验证。
这种“事后观测”的特性具有独特优势。它可以识别出许多只有在真实交互中才会暴露出来的问题,比如越狱行为,而这些问题在传统测试阶段通常是难以察觉到的。
AI 模型在实际运行时必然要做出价值判断。我们若希望这些判断和人类自身的价值观相符,而这正是 AI 对齐研究的核心目标,那就必须拥有一种能在真实世界里检测模型价值观表达的有效办法。
Anthropic 提出的这种方法,正在为这一需求提供一条全新的路径,并且是数据驱动的。它让我们可以系统地去观察模型在现实交互中的行为表现,也可以分析其行为表现与预期价值之间的契合程度,进而能够判断在价值对齐工作中到底取得了多大的成效。
本文来自“腾讯科技”,编译:金鹿,36氪经授权发布。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/275599.html
