
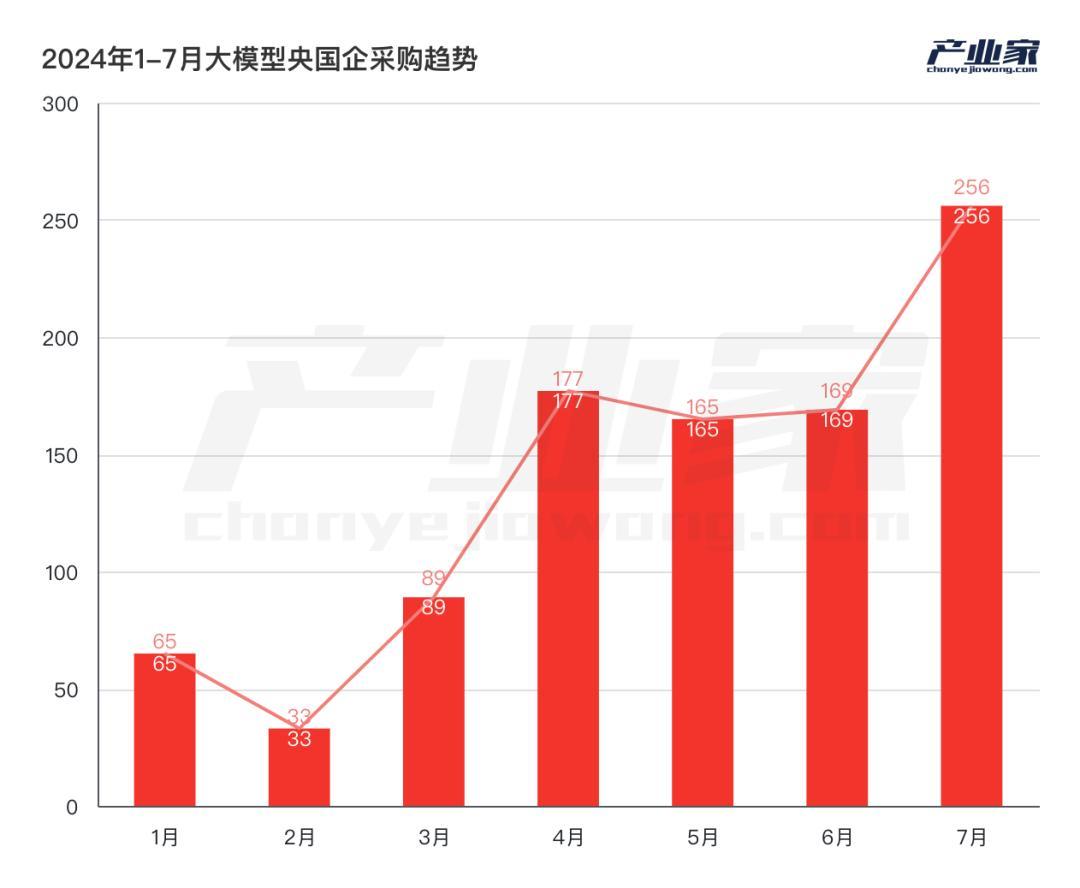
2024年1月至2024年7月,中央国企采购的大模型项目数量已超过950个,均匀分布在智能计算中心、大模型预训练、代理和行业应用等多个方向。除了政策影响,央企大规模模式落地还有哪些驱动因素?
最高的为191亿元,最低的不到1万元。大模型蓬勃发展两年,国内“AGI团队”已形成。同时,还有央企大型样板工程建设。
8月6日,神州数码集团发布公告称,旗下昆泰中国中标“中国移动2024-2025年新型智能计算中心采购(标包1)”,中标价格约191亿元,中标中标份额为10.53%。 2024年7月,湖南省委党校湖南行政学院发布采购数字机器人服务招标信息,报价9000元。


一是智能计算中心采购,二是数字机器人服务。可以看到,央企内部,大型样板工程的建设已经进行到一半。可以毫不夸张地说,在大模型浪潮席卷而来的今天,央企正在成为主导力量,带动了国内大部分人工智能大模型落地项目。
据不完全统计,2024年1月至7月,央企采购的大模型项目数量已超过950个,均匀分布在智能计算中心、大模型预训练、代理等多个方向。和行业应用。
大型模型纷纷在国有企业落地。如此磅礴势头的背后,政策推动成为决定性因素。据桑德希尔智库介绍,2023年以来,国资委多次对央企发展人工智能提出要求。其中,在2024年2月中央企业人工智能专项推进会上,提出中央企业要“开展AI+专项行动”。会上,10家央企签署倡议书,表示将主动向社会开放人工智能应用场景。
同年7月,国务院新闻办召开以“推动高质量发展”为主题的系列新闻发布会,提出未来五年中央企业预计安排投资总额超过3万亿元大规模装备升级改造,升级和部署一批高技术、高技术装备。设备先进,效率高,可靠性高。
政策推动当然是不可忽视的因素。但除了政策影响之外,站在产业数字化、数字智能化前沿,央企、国企大规模落地的驱动因素还有哪些?一个值得思考的问题是,与金融行业成为云计算时代的先行者不同,在当今大AI模式时代,央企为何成为先行者?
1、运营商、政务、能源牵头建设智能计算中心
AI大模型史上最大的项目无疑是“智能计算中心”。
预训练成本的疯狂上涨和推理需求的不断增长使得智能计算中心成为必要。近日,OpenAI CEO Sam Altman在接受采访时表示,“OpenAI不会在今年内发布ChatGPT-5,公司目前专注于ChatGPT-o1的开发和运营。”
为什么 GPT-5 没有发布?原本预计延期的o1为何提前出道?这背后的原因耐人寻味,培训成本是关键因素之一。
言归正传,国内对大模型预训练的需求日益迫切。在加速国内AGI梯队建设的同时,性能不断刷新的大型模型需要大规模智能计算集群的支撑。如今,万卡集群已经成为大型模型军备竞赛的标配。除了国内AI企业和电信运营商之外,正在推动落地的央企也在加快智能计算集群的建设,以提高大型AI模型的训练和推理效率。
一般来说,智能计算中心的建设由地方政府或电信运营商主导。据中国信息通信研究院不完全统计,截至2024年7月末,已监测智能计算中心(含已建和在建)87个。
2023年10月,沉阳智能计算中心新基建项目工程总承包(EPC)结果公布。百度联合中建八局有限公司(中建八局)成功中标,中标金额9.1亿元。具体包括机房建设、机柜设计、智能计算中心平台以及百度提供的具有AI软硬件能力的综合解决方案。
对于像这样的智能计算中心采购项目,央企已经开始广泛建设。对此,实业家根据金额列出了近两年价值最高的10个央企采购智能计算中心项目。
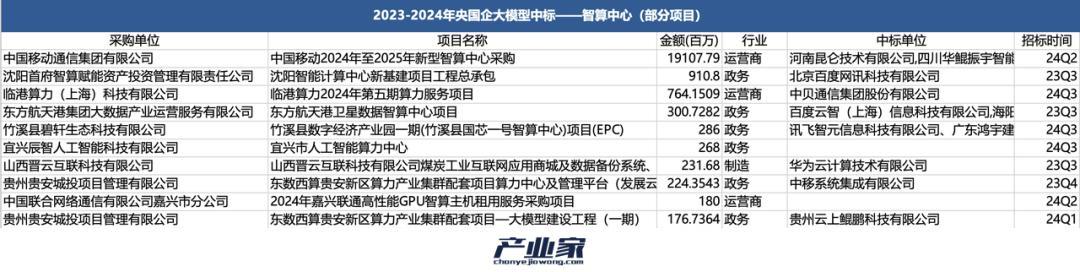
与云计算时代相比,传统数据中心的中标者大多是IDC厂商;如今的AI时代,AI公司和互联网厂商越来越多。
此外,从行业分布来看,政府和运营商对智能计算中心的投入较多。对此,实业家统计了运营商、能源、政务三大领域的智能计算中心项目占比:结果显示,政务行业对智能计算中心的投入较多,包括GPU租赁、硬件和算力调度等平台采购。
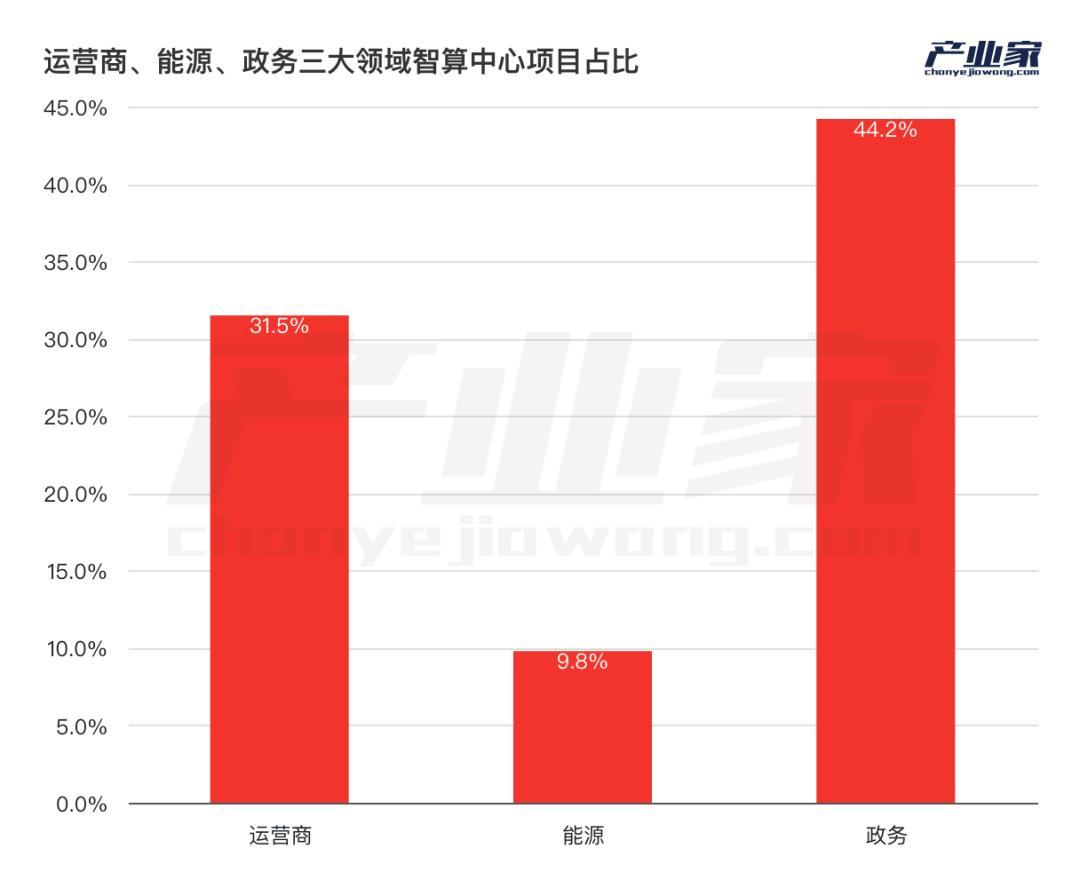
事实上,从智能计算中心的投资比例就可以看出央企对大型AI模型的需求。
可以看到的是,2023年三季度以来,央企就开始紧锣密鼓地筹备智能计算中心的建设。智能计算中心只是央企实施人工智能的一个起点。
一方面,这与上述政策时机相吻合;另一方面,2023年第三季度也恰好是以百度、阿里巴巴、华为和电信运营商为首的“国内AGI梯队”刚刚形成之时。
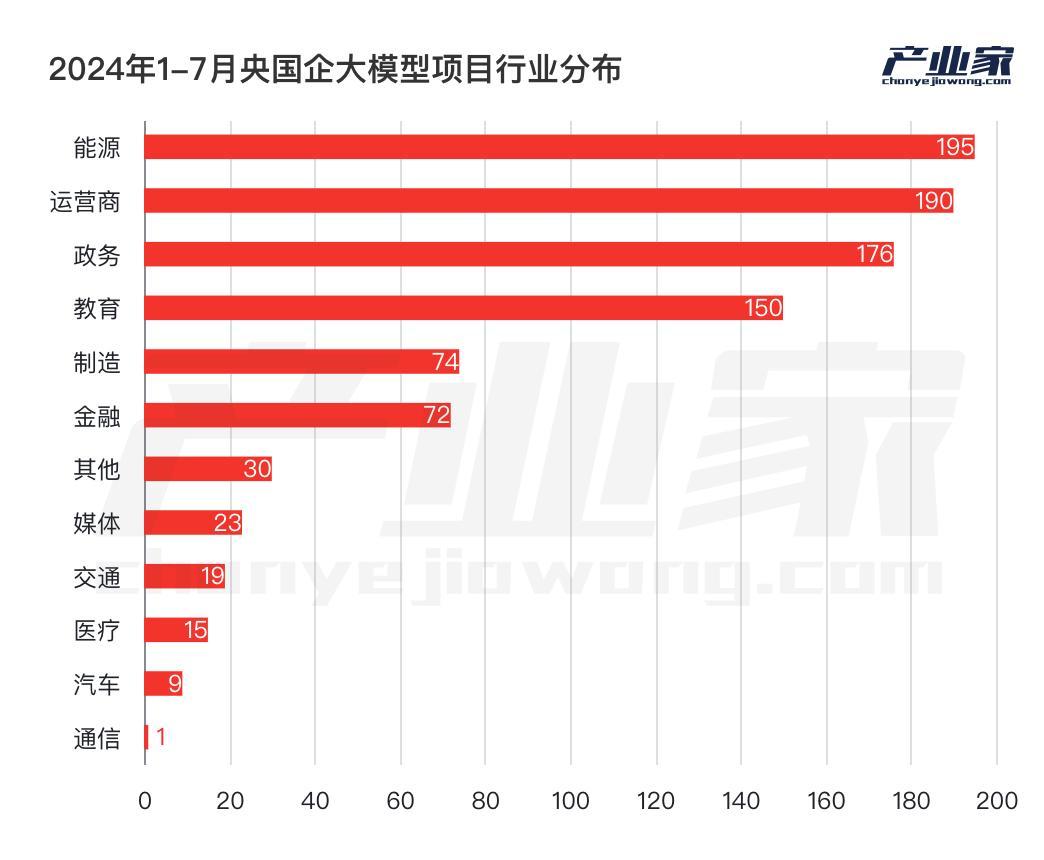
除了智能计算中心,央企人工智能大模型建设的另一个重点是行业应用,即针对特定场景构建大模型平台或应用。
以电信运营商为例。据不完全统计,2023年至今,运营商已上线大型AI模型项目238个。除了75个智能计算中心建设项目外,其余都是围绕特定场景构建大模型。 ,主要包括智能客服、营销和数字人采购。
不同的行业对大型AI模型的需求不同,自然项目侧重点也不同。对于政务和运营商行业来说,智能计算中心之所以占比较大,除了政策推动外,更重要的原因是私有化部署和本地化部署的需求极高,尤其是政务领域;另一方面,相对其他行业专注于单点或个别环节大规模模型应用的开发,政务、运营商对大规模模型的需求更为系统化,需要从GPU资源到算力调度等方方面面发挥平台作用。
相比之下,在应用大型AI模型最多的三个行业中,能源行业对智能计算中心的投入较少,更多地关注大型模型的训练和开发,特别是如何针对特殊场景训练和优化算法。如何微调模型等等。
此外,值得注意的是,对于这些行业专业知识要求较高的领域,他们在选择中标单位时也更加讲究;例如,在选择算力调度平台、大模型预训练和开发阶段时,中标企业集中在以百度、科大讯飞为首的AI公司;在大机型开发过程中,在选择具体技术研究时,他们会选择像南方电网这样技术含量较高的公司。
最后,与云计算时代不同,金融行业成为先行者立足的试验场;当今AI大模型时代,央企中,教育、能源、运营商、政务四大行业脱颖而出;而金融行业则没有像云计算时代那样表现出强烈的意愿。
2、AI大模型:颠覆传统IT架构的背后
时代变了。
在过去的云计算时代,大型企业的数字化转型需要从购买或租赁服务器,到选择建设数据中心的地点,再到选择合适的云架构,再到平台开发和上层建设。应用程序。
一般来说,对于大型企业,例如能源或工业企业,当面对分布在各个环节的数据时,通常需要构建底层PaaS平台来实现灵活的调用和互联。然而,尽管如此,数据孤岛和数据烟囱仍然存在。
然而这种从IaaS到PaaS再到SaaS的架构在如今的AI大模型时代已经被彻底颠覆。企业往往需要一个庞大的行业模型来应对,不再为了构建多个复杂的应用程序而浪费时间构建PaaS平台。
诚然,企业在云计算时代所缴纳的学费并没有浪费。在人工智能大模型时代,由于政策引导、需求倒逼和环境因素,央企首先开始实施人工智能大模型。
这很大一部分是基于过去云计算时代的一些无法解决的问题。我们希望在大型AI模型中找到更好的解决方案。
可以观察到一种现象。目前,央企大模型的落地主要集中在两点,一是智能计算中心,二是行业应用。后者包括大模型预训练、大模型开发以及针对单个环节或特定场景构建大模型应用或解决方案。
总体来说,后者是通过大模型基于具体场景的解决方案,这在过去的云计算时代是不可能的。
以运营商为例。虽然智能客服已经存在很多年了。准确地说,云计算时代以来,各种智能客服软件和解决方案层出不穷。但对于整个行业来说,劳动力流失率仍然较高,普遍都在80%以上。当时,时代的列车刚刚进入大模型时代,智能客服成为大模型落地的第一个试验田。

再比如,在能源行业,如何积累知识,如何让新人运用,一直是一个大问题。即使在云计算和工业互联网平台激增的时代,许多问题仍然没有答案。在当今大模型时代,一个行业大模型可以解决很多问题。其中关键的作用就是构建大行业模型过程中的RAG构建过程。它相当于一个企业知识库,任何输入的知识都可以轻松调用。

如上所示,对于某些行业来说,大模型并非“一无是处”。相反,它可以发挥“超级大脑”的作用,汇集企业的全部智慧,并有针对性地发挥出来。
然而,对于某些行业来说,大型模型尚未找到用途。
例如,在金融行业,目前实施的很多项目主要集中在知识库问答上,很难深入到核心业务。一方面是出于金融监管、数据隐私等方面的担忧;另一方面,更重要的是,AI错觉问题仍然难以彻底解决。任何人工智能算法都可能给金融行业带来错误的预测和建议。可能造成重大经济损失。
无论是智能客服还是大行业模式,无论是政务、运营商领域还是能源、政务、教育等行业,央企推行大模式背后有三大核心原因。
首先,大模型时代,央企、国企多年积累的数据都可以利用。它们不仅包括经过汇总整理的财务报表、交易记录等结构化数据,还包括分散在各地的一些重要的企业资产。系统内的聊天记录、文件、图片等,这些非结构化数据现在可以变成大AI模型中的“企业知识库”并发挥其价值;
其次,与过去云计算时代从IaaS到PaaS再到SaaS的三层架构不同,大模型具有很强的协同性。只需要在早期大模型开发阶段进行训练和微调,后期就可以直接基于数据。前端行为的加持。
最后,也是非常重要的一点,中央国企本身拥有庞大的服务器集群,拥有强大的算力基础。基于这些基础,他们可以更好地推动大模型的落地。
3. 赛点:赛前训练、安全及行业知识
从中标情况来看,可以毫不夸张地说,央企支持了国产大车型商业化的一半。
然而,大模型实施到一半,仍然存在很多问题需要解决。
中信建投的数据显示,2024年至2027年全球大型模型推理峰值算力需求年复合增长率为113%,远高于训练的78%。预训练成本和推理成本的叠加也推高了整个AI基础设施的市场份额。
根据艾瑞咨询测算,2023年中国AI基础数据服务市场规模为45亿元,预计到2028年其市场规模将达到170亿元,未来五年复合增长率达30.4%。
这也解释了为何中央国企近两年争相建设智能计算中心。然而,阻碍大型模型实现的不仅仅是计算资源的短缺。
虽然大模型时代颠覆了传统的三层架构,从IaaS到PaaS再到SaaS,但在新时代,新架构也迎来了一些新的挑战,比如从AI Infra到MaaS,再到上层人工智能应用涉及模型构建的多个环节,需要大型模型服务商和企业共同探索实施路径。
对于央企来说,虽然用AI大模型赋能已经成为共识,但如何使用大模型,具体在哪里添加大模型,大模型如何发挥作用,如何开发和训练大模型,面对这些问题,公司并没有太多头绪。因此,这对AI大模型供应商提出了更高的要求。
在这个过程中,供应商是否具备行业知识有时甚至会成为能否中标的关键因素。对此,以百度、华为、科大讯飞为首的大型AI模型公司,都在2024年扛起了“行业大模型”的大旗。
据统计,在能源领域,2024年上半年预培训过程中,已有不少针对某些技术研究的招标项目。
此外,值得注意的是,随着人工智能应用走向深水区,数据安全、数据共享、数据溯源等问题开始被一一摆上台面。据悉,10月9日,中共中央办公厅、国务院办公厅正式印发《关于加快公共数据资源开发利用的意见》,提出到2025年,制度规则公共数据资源开发利用初步建立;到2030年,公共数据资源开发利用制度规则更加成熟,资源开发利用体系全面建立。
虽然如今的大型AI模型已经可以让数据溯源成为现实,但职责分工、数据安全等问题仍需要AI服务商和企业共同探索。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/270879.html
