

经过一段时间的沉寂,国内又一家大型模型公司上市了OpenAI。
这不,Kimi最近推出了数学模型k0-math,号称其数学能力可与OpenAI的o1-mini和o1-preview相媲美。高中、高考、考研、入门竞赛题都可以和o1竞争。
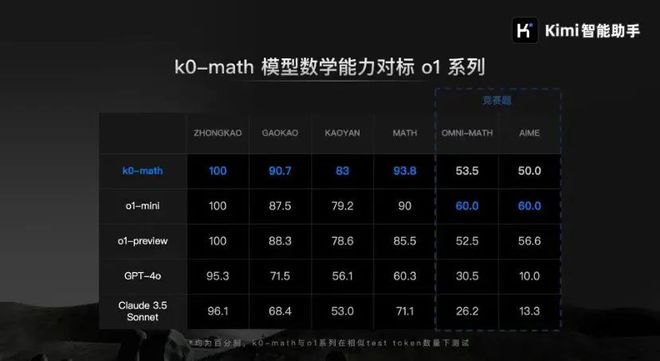
应该说,AI模型已经开始“炒作”数学能力。这很奇怪。毕竟,人工智能的数学能力长期以来一直在不断提高。草莓里甚至有无数的r。 。 。
甚至OpenAI的o1发布的时候,也没有直接说它在数学方面有多厉害,只是提到了它的推理能力。
于是原本以长文作家起家的 Kimi 这次突然开始涉足数学。世超实在是很好奇。这个k0-math是什么水平?
世超在哥们的帮助下,也提前体验了一段时间。今天,它全面开放了Kimi数学版本(基于k0-数学模型),向大家展示这个数学模型有多么强大。
目前,Kimi数学版只能在网页版上使用,入口与之前的普通版和探索版没有什么不同。不过,有一点:Kimi数学版仅支持一轮对话。
比如,世超一上来,就戳了Kimi的痛处,翻起旧谱问他:“13.11%和13.8%哪个大?” (kimi之前翻过这个,说13.11的整数部分和小数部分都大于13.8……)
这次我学聪明了,比较数值就很简单了。 Kimi数学版使用了“为了进一步确认”、“为了确保万无一失”、“通过多种方法验证”等字眼。库库输出二十或三十就OK了。

但当世超想再问的时候,出来的却不是k0-math模型。
当然,这只是一个小插曲。既然官方已经明确说明了k0-math的强度,那么我们就不欢迎了。
直接上今年高考新课程卷一的数学题:已知cos(a+β)=m,tanatanβ=2,那么cos(a-β)=?
虽然解题过程有些波折,但最终还是得到了-3m正确的最终答案。
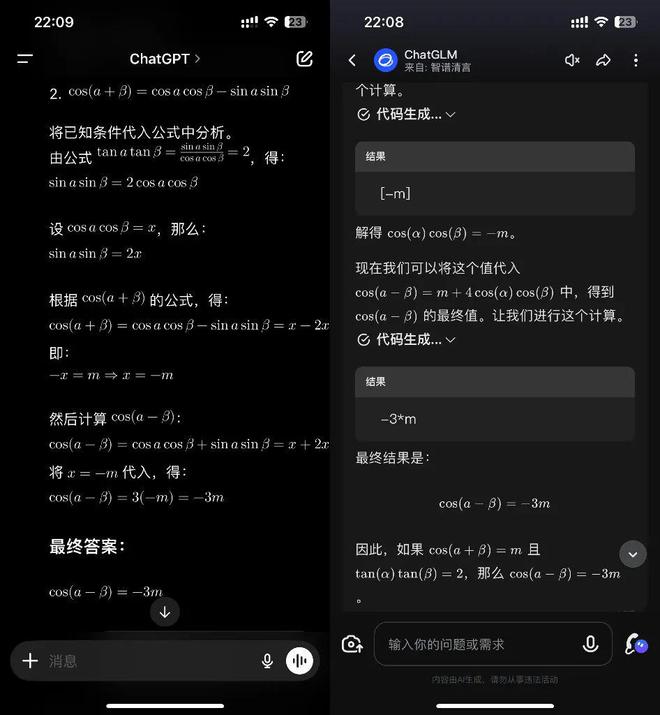
这个问题我也问过智浦清研和ChatGPT,得到的答案都是一样的,但与一步一步列出来不同,Kimi数学版给我的感觉是它真的很模仿人类的思维过程。
在模型推导的过程中,我怀疑自己的想法可能是错误的,并进行了验证。

但对于下面的概率题,Kimi数学版就没那么幸运了。

标准答案是1/2,只有ChatGPT答对了。
世超看了一下Kimi数学版本的推导过程。它列出了24种可能的情况,每种情况下的输家和赢家都讨论得很清楚,最后他还检查了一遍。

但最大的问题是漏掉了A总分≥2的一次。。 。真可惜。
我们从AMC数学竞赛中找到另一道题,交给Kimi数学版来尝试。
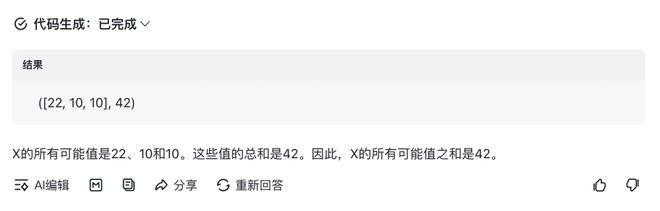
一组由 6 个(不不同的)正整数组成:1、7、5、2、5 和 X。6 个数字的平均值(算术平均值)等于该组中的一个值。 X所有可能值的总和是多少?
这次世超还添加了豆袋。对于同一个问题,四个模型中,只有芝浦青岩的模型是错误的。 (正确答案是36)
还有一个小插曲。本来世超还想给Kimi再出一道竞赛题,结果却直接问我了。 。我尝试了几次,得到了相同的答案。不知道是系统的bug,还是只是不知道如何回答这个问题,就装死了。
不得不说,在尝试了几道数学题后,《Kimi数学版》确实给了我很多惊喜,尤其是解题过程中所展现出来的思维和推理能力,刷新了我对AI模型数学能力的认识。知道。
可惜几何题还是一如既往。这只是一道初中水平的几何选择题。 Kimi数学版的CPU都快干了,答案还是错的。

至于为什么Kimi的k0-math模型有这么大的突破,世超前段时间参加了月之暗面的媒体发布会。月之暗面创始人杨志霖告诉时超,k0-math的成功很可能要归功于一种叫做COT(Chain of Thought)的技术。
这里我们不会使用太专业的术语。你可以把这个COT理解为AI模型模仿人脑进行逻辑推理,将复杂的任务分解,然后一步步解决。将这项技术应用到模型中,模型可以通过“思考”来完成任务,提高准确性。
至于为什么首先把这个东西用在数学模型上,杨志林直接引用了伽利略的名言,“宇宙是用数学的语言书写的”。

总之,我希望从数学问题入手,然后概括数学思维来理解整个世界。
当然,这并不意味着模型一旦使用思维链就会得到正确的答案,但这种方法确实可以提高模型对复杂任务的推理能力。
再举个例子,让 Kimi Math Edition 统计一下“chaping debug the world”中有多少个字母“e”。
首先,分别挑出“chaping”、“debug”、“the”和“world”,然后逐个字母地检查。虽然方法很笨,但至少不会出错。
这么说吧,世超尝试了这个简单的计数题,数学版本中只有克劳德和基米做对了。

包含在问题“我有一块1米长的面包,我每天吃一半,需要多少天吃完这块面包?”当大多数AI给出永远无法完成的答案时,Kimi数学版却觉得“存在物理极限”,认为一纳米之后就无法分离。 。 。

这种拆解任务的能力,太夸张了。即使你问它1+1等于多少,Kimi数学版也能跟你聊半天,而且你根本无法截图。

此外,在思维链的影响下,对于纠正AI模型笨、不抓重点的老问题也有一定效果。
比如苹果前段时间发表了一篇论文,这很可能意味着该模型根本无法推理。如果添加一些不相关的干扰条件,模型的精度就会下降。
但这次世超分别尝试了Kimi数学版和豆袋版。问题是:超市里,每袋大米卖50元,每瓶酱油卖10元。如果虾宝买了4袋大米和4瓶酱油,并送给邻居1袋大米和2瓶酱油,那么虾宝买大米的花费比买酱油的花费多多少?
这道题特意加上了“给邻居一袋米、两瓶酱油”的陷阱。
豆包的量有点简单,于是他把自己攒下来的米和酱油分别拿出来。

回顾《基米数学版》,我知道送礼物会泼掉水。

不管怎样,经过测试,k0-math的解题准确率不能说是100%,但调用思维链后的逻辑推理过程却让Kimi这个解题高手的数学水平有了很大的提升。
而且,世超还发现,除了k0-math之外,国内魔方DeepSeek前两天还开发了一款推理模型DeepSeek-R1-Lite,纸面上也和o1不相上下。

又是 o1 系列,它是 k0-math 和 DeepSeek-R1-Lite。有读者可能会好奇,之前不是还有长文吗?怎么突然影响了他们的推理能力?
事实上,传统的计算能力和数据处理在大模型领域遇到了一定的瓶颈。依靠强化学习来提高大型模型的推理能力已经成为大家的新方向。
说白了,这种强化学习就是让AI在训练的时候自己去尝试、犯错误,最终找到正确的答案。
例如,Claude Sonnet 3.5就是基于强化学习来提高编码能力。包括Kimi创始人杨志林,前段时间在媒体分享会上也无数次提到了强化学习,并表示他们会越来越关注基于强化学习的方法,不断迭代。
最后,借用杨之琳的《登月理论》,如果说之前的长文是迈向AGI的第一步,那么现在让AI学会思考正式开始第二阶段。
作词:西西
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/272609.html
