
文字|问下一个问题
人工智能生成的文本和图片越来越多地充斥互联网。
OpenAI首席执行官Sam Altman今年2月表示,该公司每天产生约1000亿个单词——相当于每天一百万本小说的文本量。这些内容有多少最终流入互联网尚不清楚[1]。
人工智能生成的文本可能会出现在餐厅评论、约会资料或社交媒体帖子中,或者以新闻文章的形式出现 - NewsGuard [2] 是一家专门跟踪在线虚假信息的组织,最近发现了 1000 多个大规模网站,这些网站生成有缺陷的人工智能生成的新闻文章 [3]。
事实上,由于缺乏有效的检测方法,其中大部分内容仍未被检测到。
所有这些人工智能生成的信息不仅让我们难以辨别真假,也给人工智能公司带来了麻烦。浏览网络获取用于训练下一代模型的新数据将变得越来越困难[4]。一些自产的AI内容很可能被吸收,从而无意中形成闭环,即一代AI的输出成为另一代AI的输入。
从长远来看,这种闭环可能会对人工智能本身构成威胁。现有研究表明,如果生成式人工智能在大量自身输出上进行训练,其性能将显着下降[5-8]。
下面我们用一个简单的例子来说明当人工智能系统根据自己的输出反复训练时会发生什么。
01 真实手写数字
下图是由 60,000 个手写数字组成的数据集的一部分。

▷图1.部分原始笔迹数据集,基于Ilia Shumailov等人的研究。
当我们训练人工智能模仿这些数字时,它的输出如下所示:

▷图 2. 基于 Ilia Shumailov 等人的研究,由人工智能生成的数字集,在同样由人工智能生成的数字集上进行训练。
如果这个过程继续下去会发生什么?

▷图3.根据Ilia Shumailov等人的研究,在AI生成的数集上继续训练后生成的数集。
经过如上所述的 20 代训练后,AI 生成的数字开始模糊并消失。

▷图4. AI生成的数字集经过20代训练后生成的数字集。基于 Ilia Shumailov 等人的研究。
经过 30 代训练后,它们融合成一组形状。

▷图5. AI生成数集训练30代后生成的数集
尽管这是一个简化的示例,但它说明了可能发生的问题。
想象一下一个医疗咨询聊天机器人。在接受了上一代聊天机器人产生的有限医学知识的训练后,它可以根据症状列出的疾病数量可能非常少。或者是一位人工智能历史导师,在吸收了人工智能生成的宣传后,无法区分事实与虚构。
正如副本可能会偏离原始数据一样[9],当生成式人工智能在自我生成的内容上进行训练时,其输出也可能会偏离现实,与它想要模仿的原始数据越来越远。
在 2024 年 7 月《自然》杂志上发表的一篇论文中[10],来自英国和加拿大的研究人员展示了这一过程如何导致 AI 输出范围随着时间的推移而缩小——他们称之为“模型崩溃”的早期阶段。
上述例子中的数字侵蚀现象就是这种崩溃的例证。当与人类输入分离时,人工智能输出的质量会下降(数字变得模糊),多样性也会下降(它们变得相似)。

如果只有部分训练数据是人工智能生成的,这种衰减会显得更慢或更微妙。但研究人员表示,除非合成数据得到大量新的真实数据的补充,否则经济衰退最终将会发生。
02 人工智能的退化
在一项实验中,研究人员在大型语言模型(LLM)自己生成的句子上反复训练它,并在每一轮训练后使用相同的提示命令它完成句子。即使在一开始,人工智能就已经开始出现“幻觉”。但当研究人员进一步训练自己的句子时,情况变得更糟......
当他们要求人工智能完成一个以“感恩节煮火鸡,你……”开头的句子时,最初的回应是:
要在感恩节烹饪火鸡,您需要在烤箱中准备它。在火鸡中加入盐和胡椒,然后在烤箱中煮至内部呈金黄色。由于这种方法可以作为其他食物的替代品,因此已被证明可以有效降低患心脏病的风险。
即使在一开始,人工智能也会“产生幻觉”。但当研究人员用自己的句子进一步训练它时,事情变得更糟了……
两代之后,它开始输出一个简单的长列表:
感恩节要做火鸡,你必须能够一口气吃完。然而,如果你没有足够的时间,你可以选择其他食物,如土豆、豆类、大米、肉、鱼、蔬菜、水果、坚果、种子等。
四代之后,它开始毫无意义地重复短语:
要在感恩节烹饪火鸡,您需要知道自己要做什么。如果你不知道你这一生要做什么。如果你不知道你这一生要做什么。如果你不知道你要做什么。如果你不知道什么会影响你的生活。
“模型因其对现实的自我投射而受到毒害,”研究人员在谈到这种现象时写道[11]。
这个问题不仅限于文本生成。莱斯大学的另一组研究人员研究了当图像生成人工智能根据自己的输出反复训练时会发生什么——这个问题可能已经存在于网络上人工智能生成图像的激增中[12]。
他们发现,人工智能的输出中开始累积故障和图像缺陷,最终产生带有皱纹图案和扭曲手指的图像。
▷图 6。当人工智能图像模型根据自己的输出进行训练时,它们可能会产生扭曲的图像、扭曲的手指或奇怪的图案。
“它的一部分似乎正在进入‘禁飞区’空间,”领导人工智能图像模型研究的理查德·巴拉尼克教授说 [13]。
研究人员发现,再次避免这个问题的唯一方法是确保人工智能接受大量新的真实数据的训练。
虽然互联网上绝对不乏自拍照,但他们表示,在某些图像类别中,人工智能生成的图像可能比真实数据有更多的数据。
例如,在人工智能的训练数据中,以梵高风格生成的图像可能比梵高画作的实际照片更多,这可能会导致未来出现错误和扭曲。 (研究人员表示,该问题的早期迹象很难被发现,因为领先的人工智能模型不受外界审查。)
03 模型崩溃的原因
人工智能生成的数据通常只能很好地替代真实数据,这就是所有这些问题的原因。
例如,聊天机器人陈述的荒谬事实,或者人工智能生成的手指过多的手,都很容易被发现。导致模型崩溃的突变有时并不明显,甚至可能难以检测。
生成式人工智能对大量数据的“训练”实际上是形成“统计分布”或“一组概率”来预测句子中的下一个单词或图片中的像素。
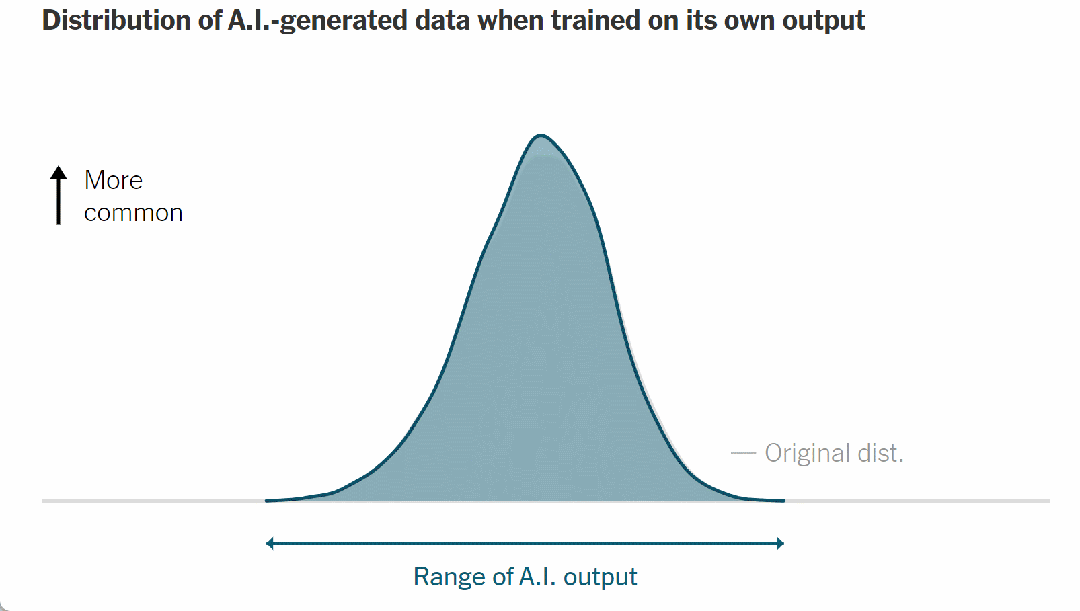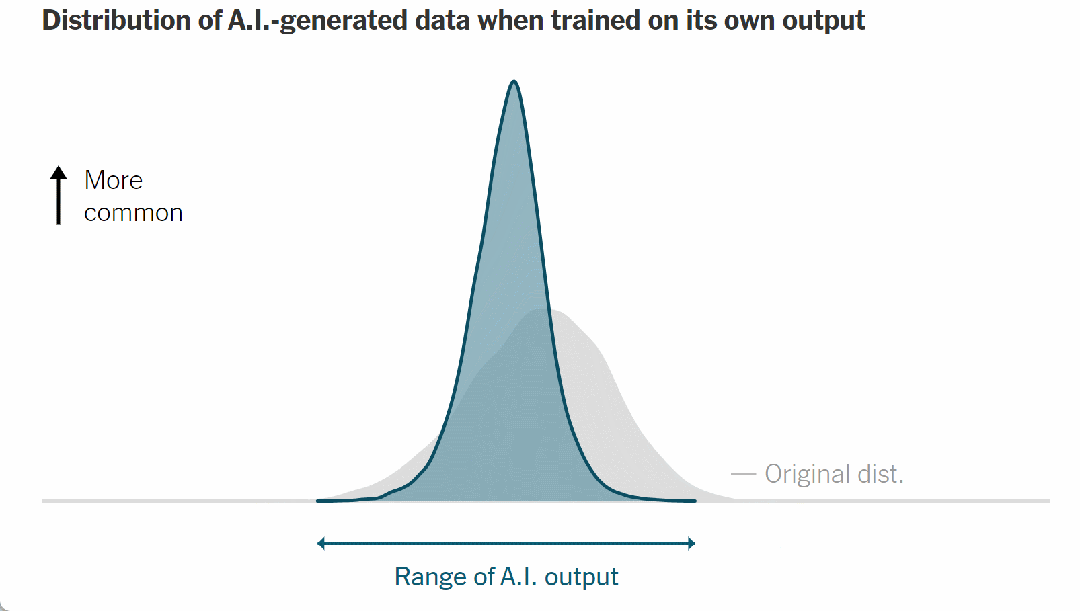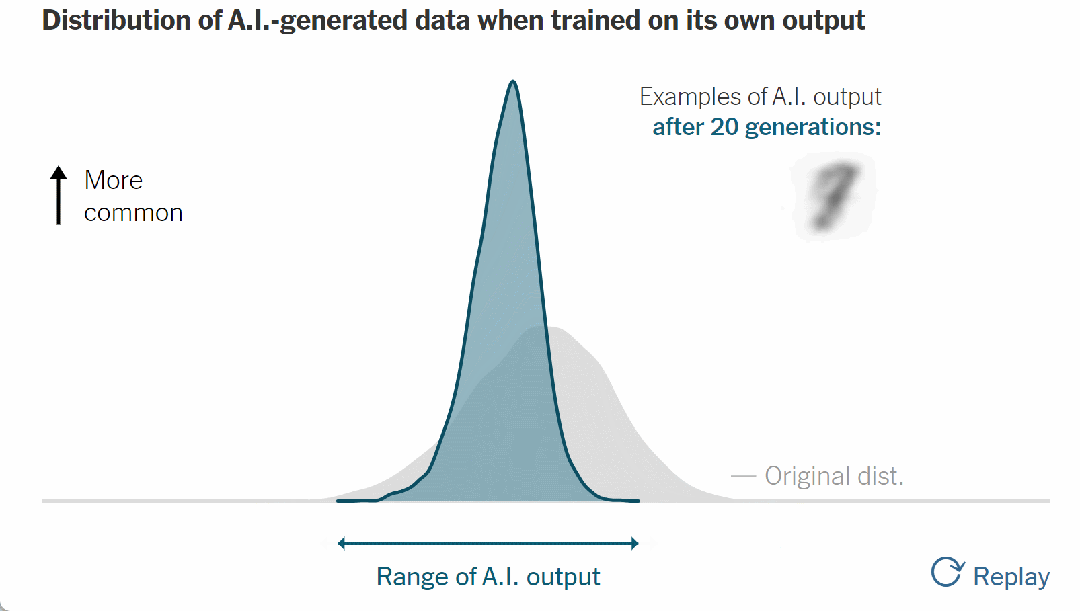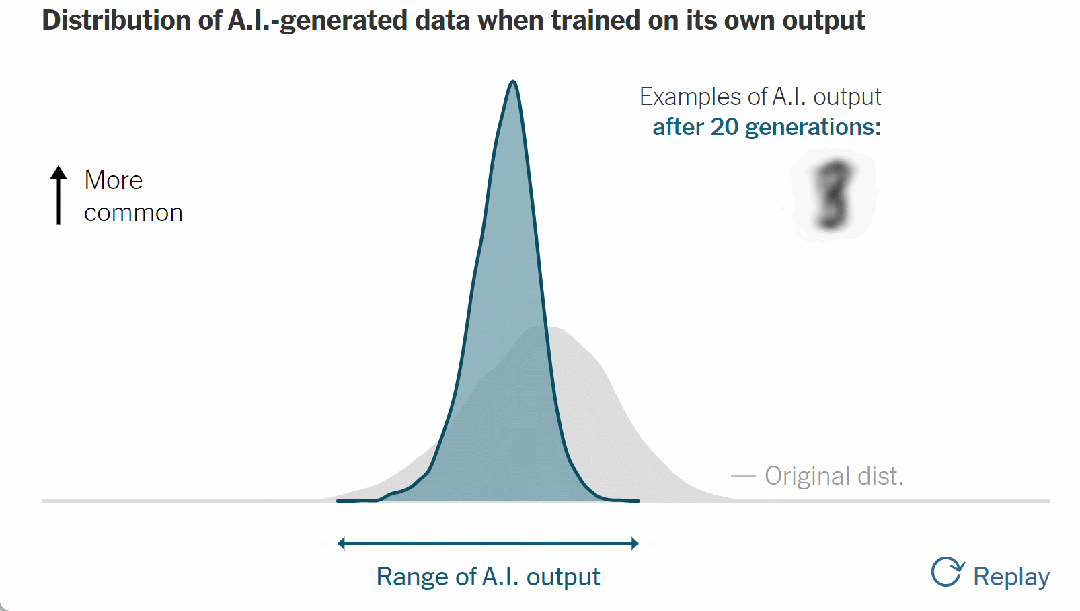
例如,当人工智能被训练模仿手写数字时,它会输出如下统计分布:
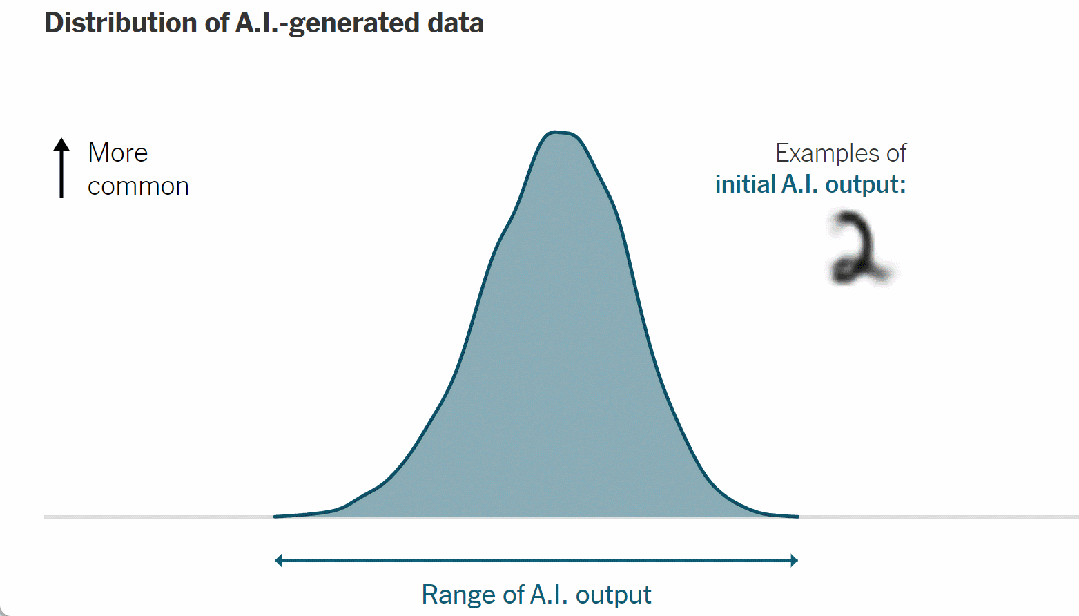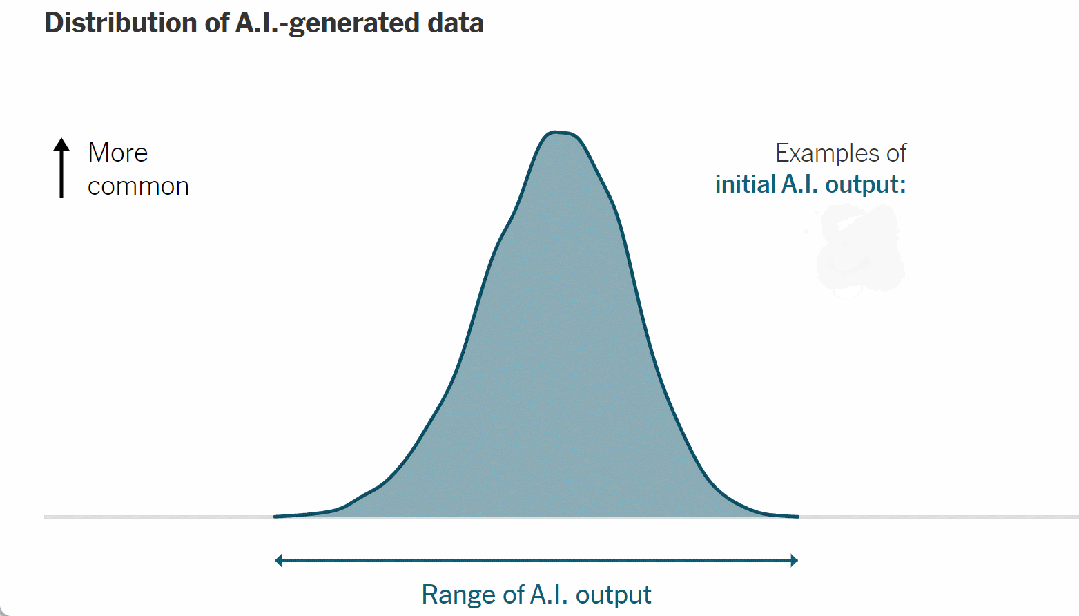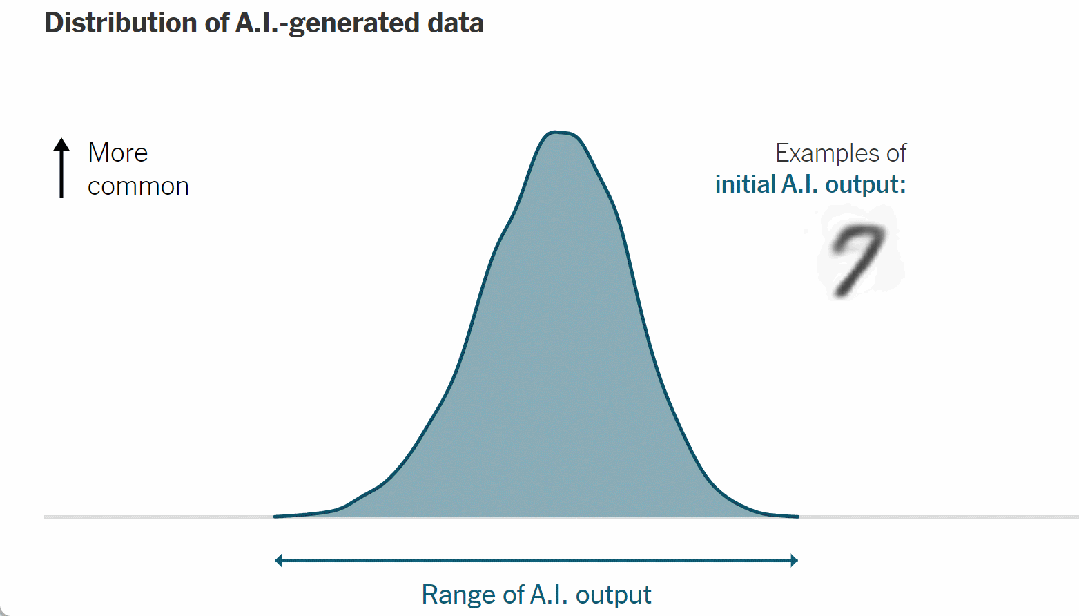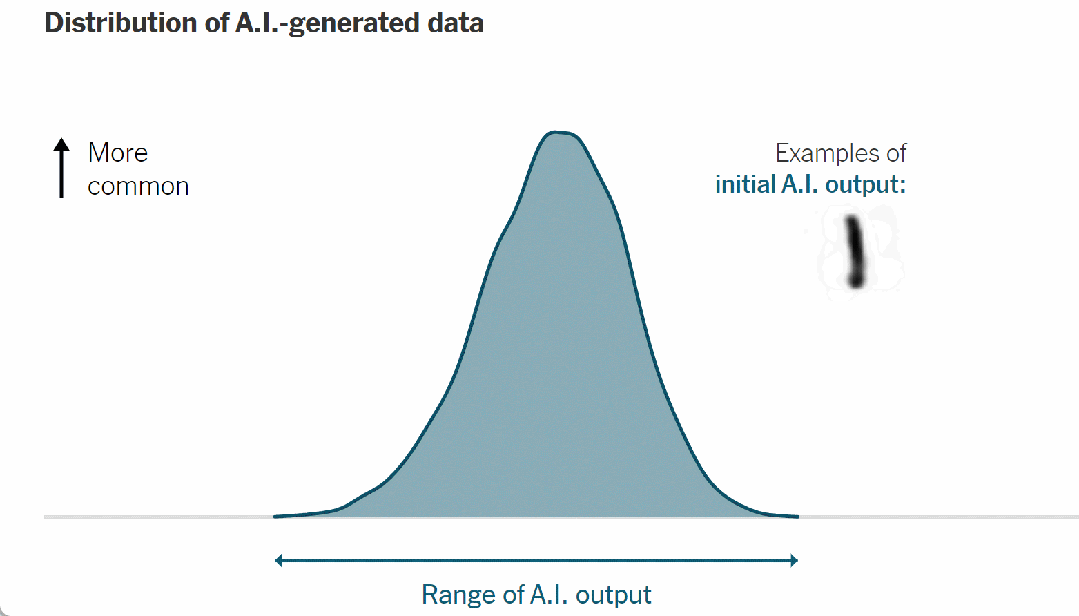
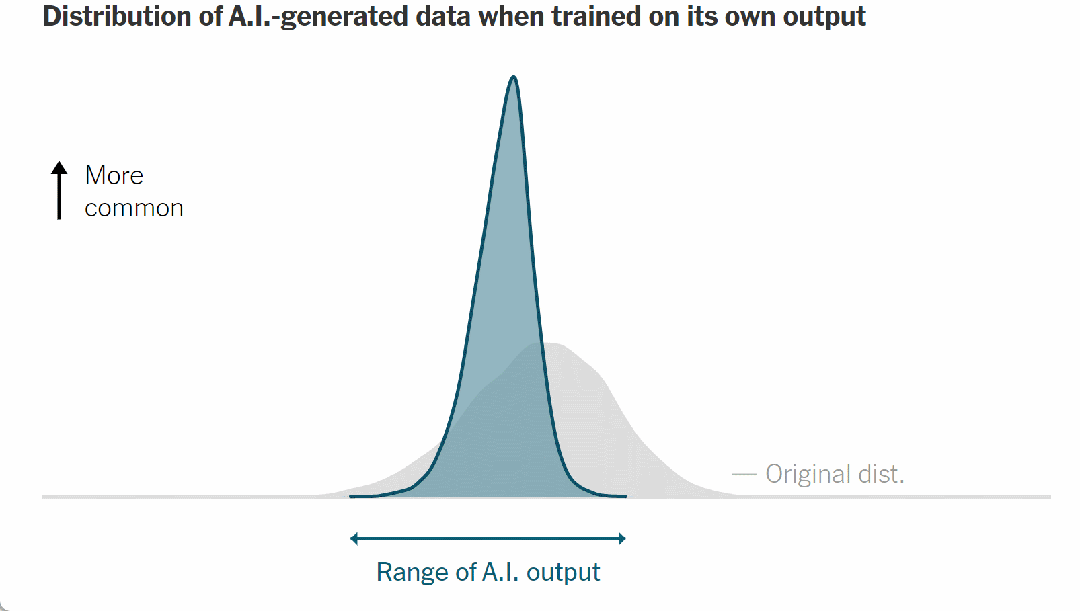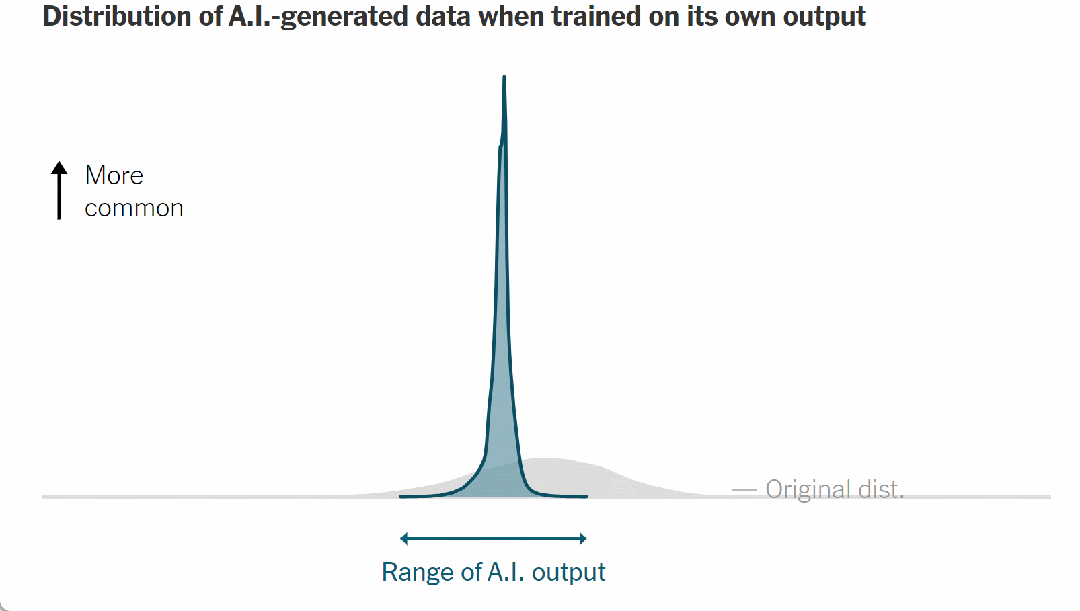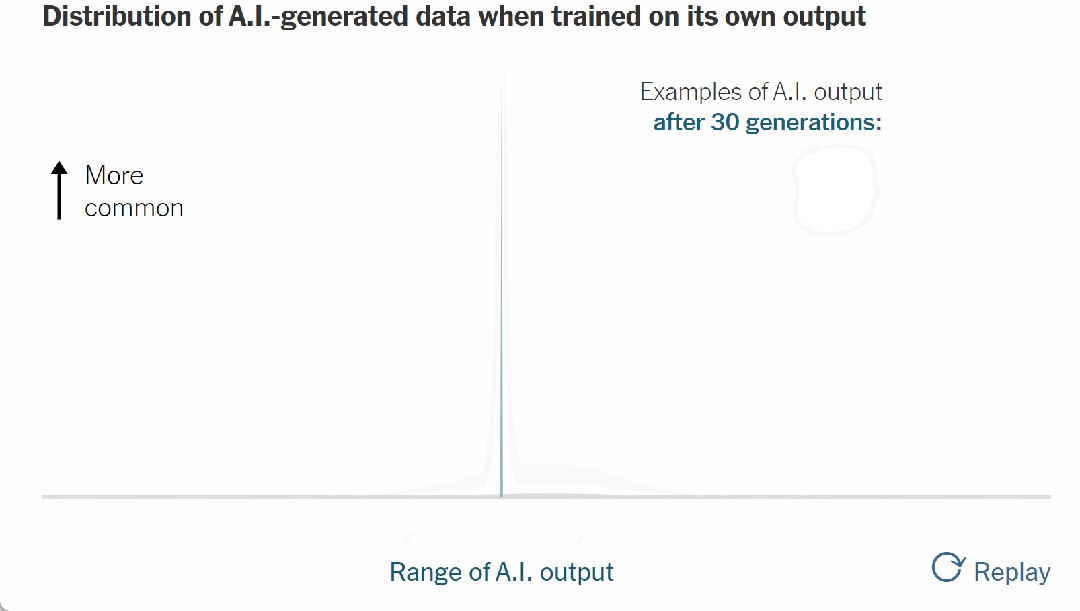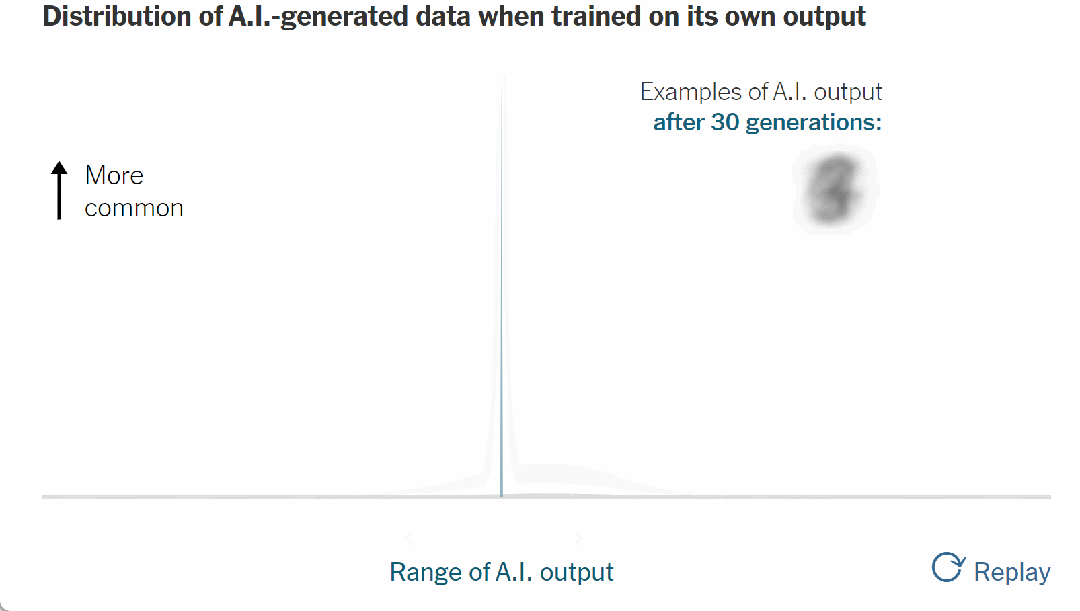
▷图 7. 人工智能生成数据的分布,经过简化以便清晰理解
这条钟形曲线的顶点代表最有可能的人工智能输出——在这种情况下,是为最典型的人工智能生成的数字;曲线的尾端描述了不太常见的输出。
请注意,当模型接受人类数据训练时,它具有“健康”的可能输出范围,反映在上图中的曲线宽度中。但在它对自己的输出进行训练后,曲线发生如下变化:
▷图 8. AI 生成的数据在根据自己的输出进行训练时的分布
它变得更高更窄。结果,模型可能输出的范围变得越来越小,甚至输出可能会偏离原始数据。
与此同时,出现了一种罕见的、不寻常的或令人惊讶的结果——曲线的尾端逐渐消失。这是模型崩溃的明显迹象——稀有数据变得更加稀有。
如果这个过程不受控制,曲线最终会变成尖峰:
▷图9. 30代后AI输出示例,当所有数字变得相同并且模型完全崩溃时
当所有数字变得相同时,模型就完全崩溃了。
04 为什么这很重要
这并不意味着生成式人工智能很快就会陷入停滞。一旦人工智能系统的质量开始恶化,制造工具的公司就会注意到。
但这可能会减慢这个过程。研究人员认为,随着现有数据源枯竭或被人工智能“渣滓”污染,这将使后来者更难以竞争[14,15,16]。
目前,人工智能生成的文本和图像已经开始在社交媒体和更广泛的互联网中激增[17],甚至隐藏在一些用于训练人工智能的数据集中[18]。 “网络正日益成为查找数据的危险场所,”莱斯大学研究生 Sina Alemohammad 说道,他研究人工智能污染如何影响图像模型 [19]。
大玩家也会受到影响。纽约大学的计算机科学家发现,当训练数据中有大量人工智能生成的内容时,需要更多的计算能力来训练人工智能——这意味着更多的精力和金钱[20]。 “模型不再按照应有的方式扩展,”领导这项工作的纽约大学教授 Julia Kempe 说 [21]。目前领先的人工智能模型需要花费数千万至数亿美元来训练,消耗的能源数量惊人,而更多的计算能力需求可能会成为一个相当大的问题[22, 23]。
05《隐患》
最后,即使是早期崩溃也存在一个潜在的威胁:多样性的侵蚀。
当公司试图避免人工智能数据经常出现的故障和“错觉”时,最容易观察到这种现象[24]。特别是,当数据可以与我们可以视觉识别的多种形式(例如人脸)匹配时,最容易观察到这种现象。 。
下图所示的这组AI人脸是莱斯大学的研究人员利用AI生成的一组扭曲的人脸。他们调整了模型以避免视觉错误。

▷图片来源:新浪Alemohammad等
下图是他们在前一组面孔上训练新人工智能后的输出。乍一看,模型更改似乎有效:没有错误。

▷经过一代AI输出训练,生成的AI人脸看起来更加相似。
经过两代人...

▷两代之后...三代之后...

▷经过三代...
四代人过去了,面孔似乎正在趋同。

▷四代之后,面孔似乎开始趋同。
阿勒穆罕默德表示,多样性的下降是“一个隐患”。 “你可能会忽视它,然后你就无法弄清楚,直到为时已晚。”
就像数字一样,当大部分数据是人工智能生成时,崩溃的变化最为明显。而如果合成数据与更真实的真实数据混合,下降速度会更慢。
但研究人员表示,这个问题很难与现实世界隔离,并且不可避免地会发生,除非人工智能公司竭尽全力避免使用自己的输出。
相关研究[25]表明,当AI语言模型用自生成词进行训练时,其词汇量会减少,句子在语法结构上的多样性也会减少——这就是“语言多样性”的损失[26]。
研究还发现,这一过程会放大数据中的偏差[27],并且更有可能删除与少数群体相关的数据[28]。
06 出路
也许这项研究的最大收获是高质量、多样化的数据是有价值的,并且计算机难以模仿。
因此,一种解决方案是人工智能公司为数据付费,以确保数据来自人力且高质量,而不是从互联网上抓取[29]。
例如,OpenAI 和谷歌已与一些出版商或网站达成协议,使用他们的数据来改进人工智能。 (纽约时报在2023年起诉OpenAI和微软侵权[30],而OpenAI和微软则认为他们的使用属于版权法下的合理使用[31,32]。)
更好的检测人工智能输出的方法也有助于缓解这些问题。
例如,谷歌和 OpenAI 正在开发人工智能“水印”工具,可用于识别人工智能生成的图像和文本,这些工具引入了隐藏模式[33,34,35]。
然而,研究人员认为文本水印仍然面临挑战[36],因为这些水印并不总是可靠地检测到并且很容易被规避(例如,它们可能无法被翻译成另一种语言)[37]。
人工智能糟粕并不是公司应对合成数据保持警惕的唯一可能原因。另一个问题是互联网上的文本数量有限。
一些专家估计,最大的人工智能模型已经在互联网上可用的文本池上进行了百分之几的训练[38]。他们预测,为了维持当前的增长率,这些模型可能会在十年内耗尽公共数据[39]。
“这些模型太大了,整个互联网几乎没有更多的图像或对话,”巴拉尼克教授说。
为了满足不断增长的数据需求,一些公司正在考虑使用“今天的”人工智能模型生成的数据来训练“明天的”模型[40]。但研究人员认为这可能会导致意想不到的后果,例如质量或多样性下降。
在某些情况下,合成数据可以帮助人工智能学习,例如,当较大人工智能模型的输出用于训练较小模型时,或者当可以验证正确答案时,例如解决数学问题或棋盘游戏中的最佳策略例如国际象棋或围棋 [41,42,43]。
与此同时,新的研究表明,当我们整理合成数据时(例如,通过对人工智能的响应进行排名来选择最佳答案),可以缓解一些崩溃问题[44, 45]。
肯佩教授表示,公司已经在数据争论上投入了大量资金,但随着他们了解合成数据的问题,这将变得更加重要。
但就目前而言,没有什么可以取代真实的东西。
关于数据:为了生成人工智能生成的数字图像,我们遵循研究人员概述的程序 [46]。我们首先使用 60,000 个手写数字的标准数据集训练了一个称为变分自动编码器的神经网络 [47, 48]。
然后,我们仅使用先前神经网络生成的 AI 数字来训练新的神经网络,并重复此过程 30 次。
为了创建 AI 输出的统计分布,我们使用每一代神经网络创建了 10,000 个数字地图。然后,我们使用第一个神经网络(在原始手写数字上训练的神经网络)将这些图画编码成一组数字,称为“潜在空间”编码[49]。这使我们能够定量比较不同代神经网络的输出。为简单起见,我们使用此潜在空间编码的平均值来生成本文中所示的统计分布。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/272929.html
