
仅经过“预训练”的模型无法直接使用。存在输出有毒、危险信息的风险,且无法有效遵循人类指令。因此,通常需要进行后期训练,例如“指令微调”和“从人类反馈中学习”,为各种下游用例准备模型。
早期的训练后工作主要遵循InstructGPT等模型的标准解决方案,如指令调优、偏好微调等。然而,训练后仍然充满玄学。例如,在提高模型编码能力的同时,也可能会削弱模型。写诗或遵循指令的能力,如何获得正确的“数据组合”和“超参数”,使模型能够获得新的知识而不失去其通用能力,仍然是棘手的。
为了解决后培训问题,各大公司都增加了后培训方法的复杂性,包括多轮训练、人工数据加合成数据、多种训练算法和目标等,达到专业知识与通用知识并重。功能。然而这类方法大多是闭源的,开源模型的性能无法满足需求。在LMSYS的ChatBotArena上,排名前50的模型尚未发布其训练后数据。
最近,艾伦人工智能研究所(AI2)发布了 Tülu 3,这是一系列完全开放、最先进的训练后模型,以及所有数据、数据混合、配方、代码、基础设施和评估框架,突破训练后研究的界限,缩小开源和闭源模型微调配方之间的性能差距。

论文链接:
图鲁3-70B:
图鲁3-8B:
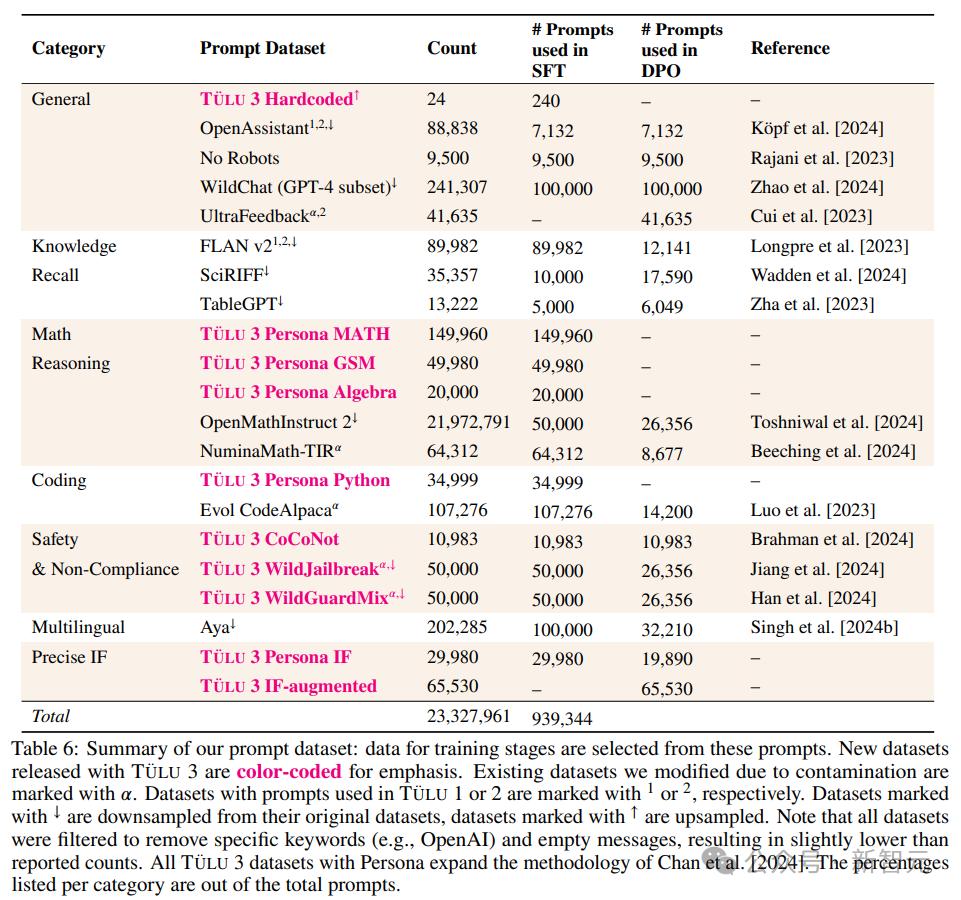
TÜLU 3 数据:
TÜLU 3 代码:
TÜLU 3 评测:
演示:
模型训练算法包括监督微调(SFT)、直接偏好优化(DPO)和可验证奖励的强化学习(RLVR)
TÜLU 3建立在Llama 3.1的基础模型之上,其性能超越了Llama 3.1-instruct、Qwen 2.5、Mistral,甚至GPT-4o-mini和Claude 3.5-Haiku等模型。
TÜLU 3的训练过程结合了强化学习的新算法、尖端的基础设施和严格的实验来结构化数据并优化不同训练阶段的数据组合、方法和参数。它主要由四个阶段组成。
第一阶段:数据建设
研究人员主要关注模型的知识回忆、推理、数学、编程、指令跟随、一般聊天和安全等核心通用技能,然后根据目标需求收集人工和合成数据。
第 2 阶段:监督微调 (SFT)
研究人员对精心挑选的提示和补全进行监督微调 (SFT),首先使用在 TÜLU 2 数据集上训练的 Llama 3.1 模型作为基线,确定哪些技能落后于最先进的模型,然后针对持续收集高质量的公共和综合数据集。
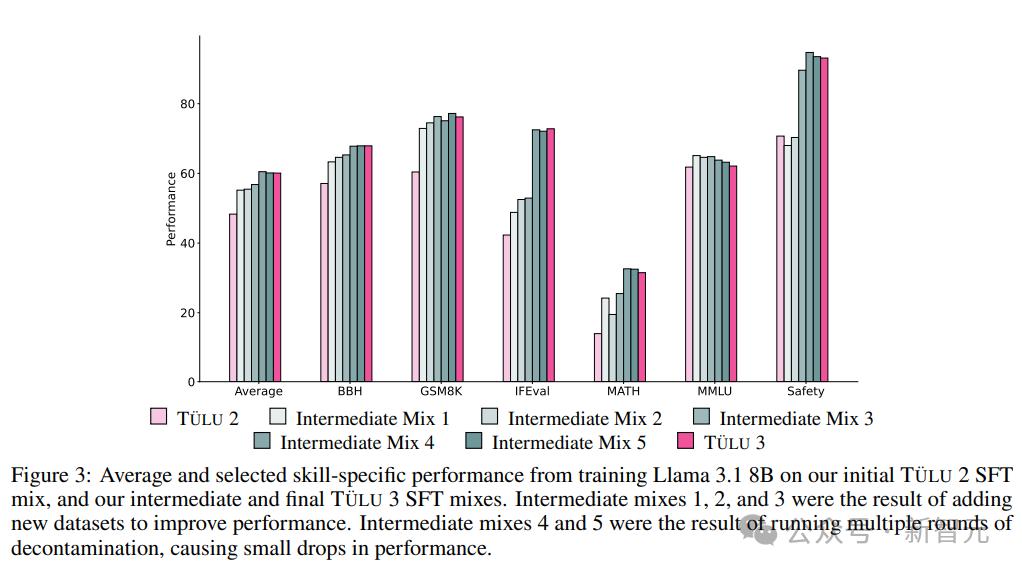
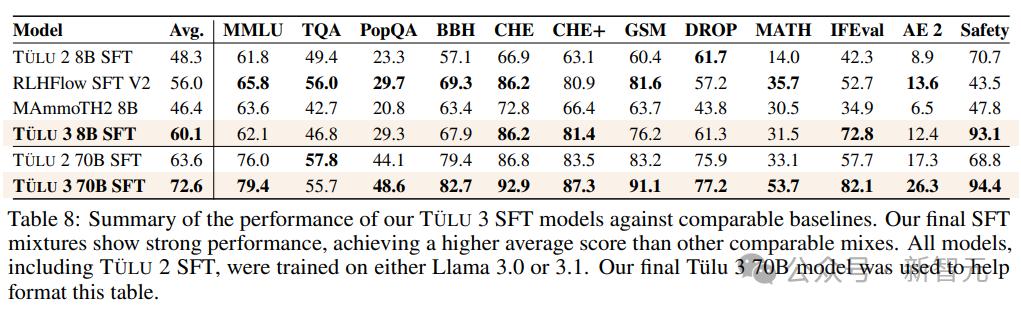
通过彻底的实验,确定了最终的SFT数据和训练超参数,以增强目标核心技能,而不显着影响其他技能的表现。
关键数据实验包括:
1.聊天数据多样化:主要来自WildChat。如果删除这个数据集,您可以看到大多数技能都有小幅但显着的下降,尤其是在 Alpaca Eval 上,凸显了“多样化的现实世界数据”的重要性。
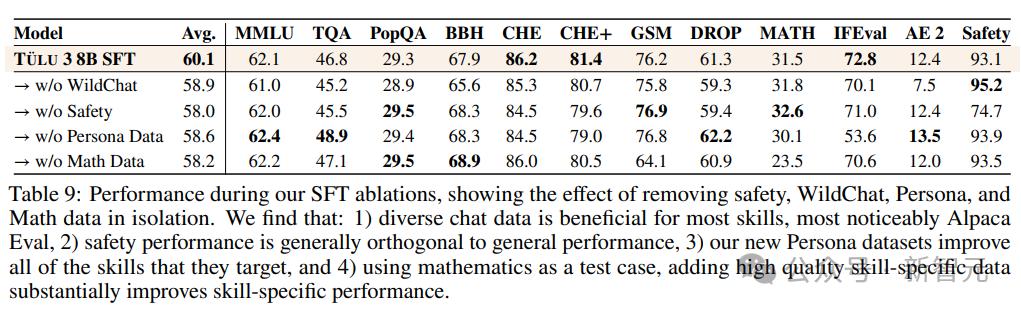
2.安全性是独立的:去除特定的安全性数据集后,可以看到大多数技能的结果大致相同;添加对比提示(例如 CoCoNot)有助于防止模型过度拒绝安全提示。
3. 新的角色数据主要是为数学、编程和指令跟踪而构建的。删除后,HumanEval(+)、GSM8K、MATH 和 IFEval 的性能将显着下降。
4. 针对特定技能,去除所有数学相关数据后,GSM8K 和 MATH 均大幅下降。
5.智能体训练数据的数量,可以发现,当数据集规模继续增大时,模型的平均性能不断提高。增加到完整的混合数据集后,GSM8K等指标的性能明显提升,但TruthfulQA的性能却有所下降。

第三阶段:偏好调整
研究人员主要使用直接偏好优化(DPO),针对新构建的、基于政策的综合偏好数据,以及从选定线索获得的非政策数据。与 SFT 阶段一样,我们通过彻底的实验确定最佳的首选数据组合,揭示哪些数据格式、方法或超参数可以带来改进。
在TÜLU 3项目中,研究人员探索了多种偏好微调方法,目的是提高整个评估套件的性能;并研究了各种训练算法,从直接偏好优化(DPO)及其衍生物到强化学习算法,例如近端策略优化(PPO)。
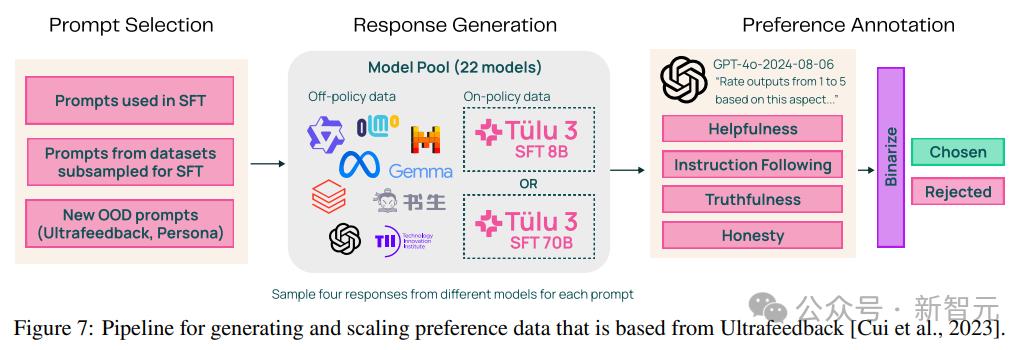
通过改进和扩展UltraFeedback流程,研究人员根据提示创建了政策内偏好数据(包括输入、两个输出选项和标签),使用大语言模型(LLM)作为裁判构建“偏好、拒绝”数据是的,主要包括三个阶段:
1. 提示选择
除了来自数据构建阶段的提示之外,还包括来自其他来源的提示,例如没有 TruthfulQA 实例的 Ultrafeedback 版本,或者通过向提示添加新的 IF 约束。

本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/273200.html
