
机器心脏报告
机器之心编辑部
一个非常简单的改变就可以提高LLM的推理能力。
在认知科学领域,关于语言是用于思考还是用于交流一直存在争论。
随着 LLM 和 CoT 的兴起,语言已成为机器推理的默认媒介——但这真的是最好的方法吗?
一般来说,LLM仅限于语言空间内的推理,通过思想链(CoT)表达推理过程来解决复杂的推理问题。
然而,语言空间可能并不总是最适合推理的。例如,许多单词标记主要用于文本连贯性而不是推理本身,而某些关键标记则需要复杂的规划。这种差异给LLM带来了巨大的挑战。
为了探索LLM在不受限制的潜在空间中而不是使用自然语言的推理潜力,Meta和加州大学圣地亚哥分校的研究人员提出了一种新的范式——Coconut(Chain of Continuous Thought),来探索LLM在无限制潜在空间中的推理潜力。潜在空间。

Coconut 涉及到对传统 CoT 流程的简单修改:Coconut 不再通过语言模型头和嵌入层将隐藏状态映射到语言 token,而是直接使用上一个隐藏状态(即持续思维)作为下一个 token 的输入嵌入(如图 1 所示)。
这种修改将推理从语言空间中解放出来,并且由于连续思维是完全可微的,因此系统可以通过梯度下降进行端到端优化。为了加强潜在推理的训练,本文采用多阶段训练策略,有效利用语言推理链来指导训练过程。
这种范式带来了一种高效的推理模式。与基于语言的推理不同,Coconut 中的连续思维可以同时编码多个潜在的下一步,从而实现类似于 BFS(广度优先搜索)的推理过程。尽管模型在初始阶段可能会做出错误的决策,但它可以在不断的思考中维持多种可能的选择,并通过推理(在一些隐含的价值函数的指导下)逐渐消除错误的路径。这种先进的推理机制超越了传统的 CoT,即使模型没有经过明确的训练或指示以这种方式运行。
实验表明Coconut成功增强了LLM的推理能力。对于数学推理(GSM8k),使用顺序思维已被证明有利于提高推理准确性,这与语言推理链的效果类似。通过连接更多连续的想法,可以扩展和解决越来越具有挑战性的问题。
在逻辑推理方面,包括ProntoQA和本文新提出的ProsQA,需要更强的规划能力,Coconut及其一些变体甚至超越了基于语言的CoT方法,同时在推理过程中生成的token明显更少。
这项研究在X上获得了非常高的讨论量,单人转发浏览量超过20万次。

持续思维链:椰子
方法概述。在Coconut方法中,LLM在语言模式和潜在模式之间切换(图1):
特殊标记<bot>和<eot>分别用于标记潜在思维模式的开始和结束。
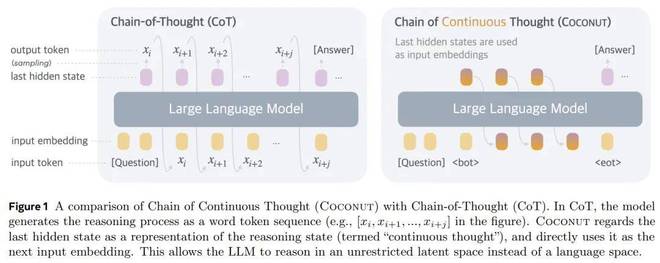
火车。本文重点介绍问题解决设置,其中模型接收问题作为输入并通过推理过程生成答案。作者使用语言 CoT 数据来监督顺序思维。如图 2 所示,在初始阶段,模型在常规 CoT 实例上进行训练。在随后的阶段,即第 k 阶段,CoT 中的前 k 个推理步骤被 k × c 个连续的想法所取代,其中 c 是一个超参数,用于控制取代单个口头推理步骤的潜在想法的数量。

推理过程。 Coconut 的推理过程与标准语言模型解码过程类似,只不过在 Latent 模式下,本文直接嵌入最后一个隐藏状态作为下一个输入。这样做的挑战是确定何时在潜在模式和语言模式之间切换。当重点关注问题解决方案设置时,本文会在问题标记之后立即插入 <bot> 标记。对于 <eot>,作者考虑了两种潜在的策略:a)针对潜在想法训练二元分类器,允许模型自主决定何时终止潜在推理,或者 b)始终将潜在想法填充到恒定长度。这篇文章发现这两种方法都效果很好。除非另有说明,本文在实验中均采用第二种方案,以简化操作。
实验
研究团队通过三个数据集验证了大型语言模型在连续潜在空间中进行推理的可行性。实验主要评估模型生成答案的准确性和推理效率。
实验涉及两种主要类型的任务:数学推理和逻辑推理。数学推理使用GSM8k数据集。逻辑推理使用两个数据集:团队开发的5-hop ProntoQA和ProsQA。
ProntoQA给出了层次化的分类知识结构,并要求模型判断不同类别之间的隶属关系是否正确。 ProsQA是一项更具挑战性的推理任务,包含许多随机生成的有向无环图,需要模型执行大量的规划和搜索。
实验装置
在实验设置方面,该研究使用预训练的GPT-2模型,学习率为1×10^−4,batch size为128。
对于数学推理任务,每个推理步骤由2个潜在思维向量表示,整个训练过程分为4个渐进阶段。
在逻辑推理任务中,每一步使用一个潜在思维向量,训练分为7个递进阶段,难度逐渐增加。所有实验在标准训练过程后继续训练到第 50 个 epoch,并通过评估验证集的准确性来选择性能最佳的模型检查点进行最终测试。
基线方法和椰子的各种版本
为了综合评价该方法的效果,研究团队设立了以下基线方法进行比较:
1.传统CoT:使用完整的思维链条进行训练,让模型生成每一步的推理过程
2.No-CoT:模型直接生成最终答案,不需要中间推理步骤。
3. iCoT:采用渐进策略,逐步去除推理链中的步骤
4.暂停标记:在问题和答案之间插入特殊的暂停标记
同时,他们还评估了椰子的三种变体:
1、无课学习版:跳过渐进式训练,直接采用最后阶段训练方式
2.无思维版本:去掉了持续思维表征,只保留阶段性训练机制
3.思维替换版本:用特殊代币替换持续思维的表示
结果与讨论
表 1 显示了所有数据集的总体结果。持续思考有效增强了大型语言模型的推理能力,这一点从其与没有CoT的基线相比一致性的提高就可以看出。在ProntoQA和ProsQA上,其性能甚至超过了CoT。
研究小组从实验中得出以下主要结论:
持续思维的“链”结合增强推理能力。
在传统的 CoT 中,输出的 token 将作为下一步的输入,这已被现有研究证明可以增加模型的有效深度和表达力。
研究小组进一步探讨了这一特性是否也适用于潜在空间推理,因为这意味着这种方法可以通过链接多个潜在想法来解决更复杂的问题。
在 GSM8k 数据集上的实验中,Coconut 优于使用类似策略训练的其他架构,尤其是超越了最新的 iCoT 基线,并显着优于同样提高了计算能力的 Coconut(暂停一下)变体。
尽管之前的研究已经证明特殊令牌可以解决高度并行化的问题,但研究团队的结果表明,Coconut 架构对于一般问题更有效,例如后续步骤高度依赖先前步骤的数学文字问题。
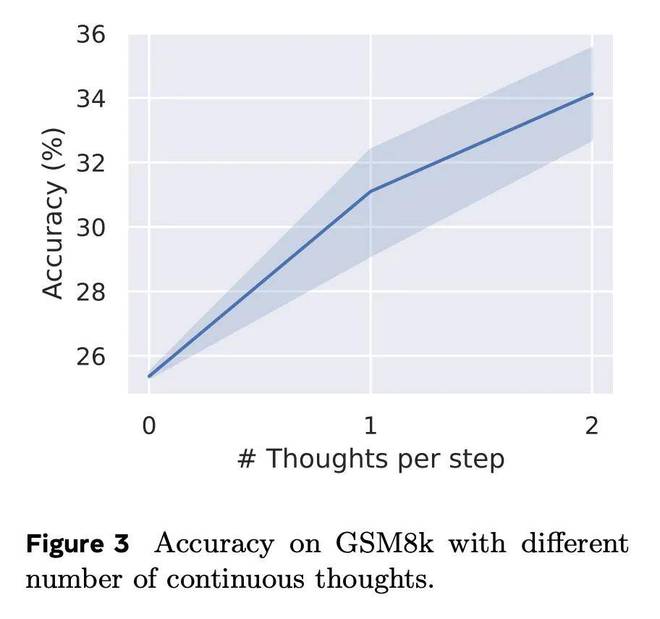
此外,当调整控制每个言语推理步骤对应的潜在想法数量的参数c时(见图3),随着c从0增加到1,然后增加到2,模型性能稳步提高。这表明连锁效应类似CoT 也存在于潜在空间中。
在计划密集型任务中,潜在空间推理优于语言推理。复杂的推理往往需要模型“向前看”并评估每一步的合理性。在研究团队的数据集中,GSM8k和ProntoQA由于其直观的问题结构和有限的分支,相对容易预测下一步。相比之下,ProsQA 随机生成的 DAG 结构极大地挑战了模型的规划能力。
如表1所示,CoT与No-CoT相比没有显着改善。然而,Coconut 及其变体和 iCoT 显着提高了 ProsQA 上的推理能力,表明潜在空间推理在需要大量规划的任务中具有明显的优势。
模型仍然需要指导来学习潜在空间推理
理想情况下,模型应该能够通过问答数据的梯度下降(即无课程版本的 Coconut)自动学习最有效的连续思维。然而,实验结果表明,这种训练方法的表现并不比 no-CoT 更好。通过按目标将培训分解为多阶段课程,Coconut 在各种任务中都取得了最佳表现。
持续思考是推理的有效表现
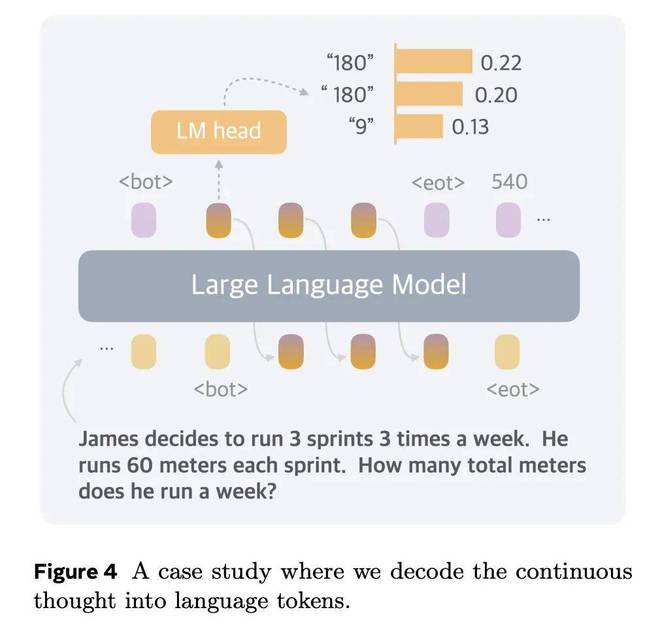
尽管顺序思维最初并不是为了转化为具体的文字而设计的,但团队发现它可以用来直观地解释推理过程。
图 4 显示了 Coconut 解决的数学应用问题的案例研究 (c=1)。第一个连续的想法可以被解码为诸如“180”、“180”(带空格)和“9”之类的标记。这个问题的推理过程应该是3×3×60=9×60=540,或者3×3×60=3×180=540。
这正好对应了解题过程中的第一个中间计算结果(3×3×60可以先计算到9或180)。更重要的是,持续思考可以同时包含多种不同的解决问题的思路。这一特性使其在需要复杂规划的推理任务中表现良好。
了解 Coconut 的底层推理机制
接下来,作者使用 Coconut 的变体对潜在的推理过程进行了分析。
模型:Coconut 允许在推理过程中通过手动设置 <eot> 的位置来控制潜在想法的数量。当 Coconut 被迫使用 k 个连续的想法时,模型预计会从步骤 k + 1 开始以语言输出剩余的推理链。实验使用 k∈{0,1,2,3,4,5,6}在 ProsQA 上测试 Coconut 变体。
图5展示了ProsQA上不同推理方法的对比分析。随着不断思考中进行更多的推理(k值增加),最终答案的准确性(图5左侧)和正确推理过程的比例(图5右侧的正确标签和正确路径)都得到提高。此外,幻觉和错误目标的发生率也有所降低。这也表明,当潜在空间中发生更多推理时,模型的规划能力得到提高。
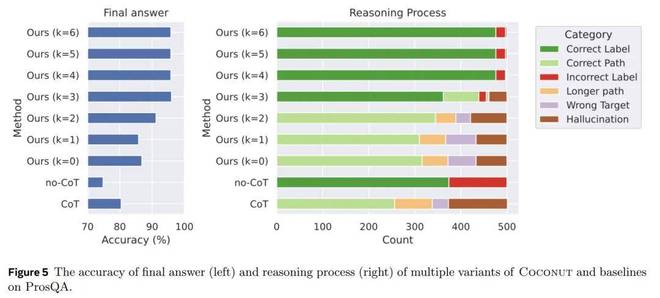
图 6 显示了一个案例研究,其中 CoT 产生幻觉,Coconut (k = 1) 导致错误的目标,但 Coconut (k = 2) 成功解决了问题。在此示例中,模型无法准确确定在早期步骤中选择哪条边。然而,由于潜在推理避免了早期做出艰难的选择,因此模型可以在后续步骤中逐步消除不正确的选项,并在推理结束时实现更高的准确性。
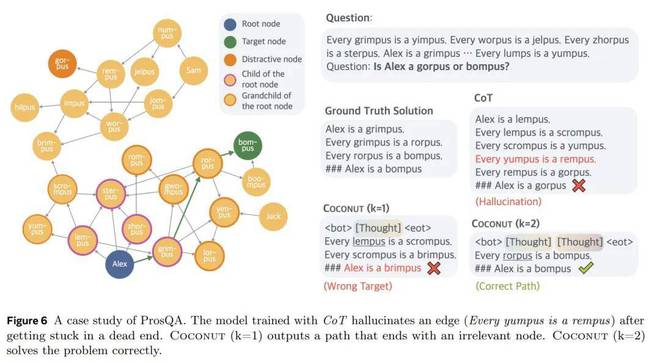
潜在搜索树的解释
由于顺序思维可以编码多个潜在的后续步骤,因此底层推理可以解释为搜索树而不仅仅是推理“链”。以图6为例,第一步,可以选择Alex的任意子节点:{lempus, sterpus, zhorpus, grimpus}。
图 7 的左侧显示了所有可能的分支。同样,第二步中的前沿节点是 Alex 的孙子节点(图 7 右侧)。
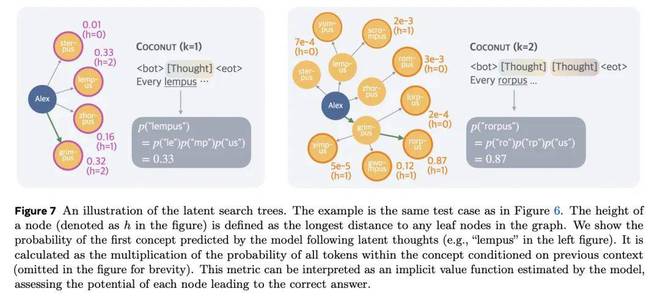
与标准的广度优先搜索不同,该模型表现出优先探索有前途的节点同时修剪不相关节点的能力。通过分析模型在语言空间中的后续输出,研究团队发现了模型的偏好。例如,当模型在潜在想法后切换回语言空间(k=1)时,它会以结构化格式预测下一步。通过检查概率分布,研究团队获得了根节点 Alex 的子节点的值(图 7 左)。类似地,当k=2时,也得到了所有前沿节点的预测概率(图7右)。
图 8 显示了模型如何在潜在思维空间中进行推理。在第一个潜在思维阶段,模型同时考虑多种可能的推理方向,以保持思维的多样性。在第二个潜在思维阶段,模型会逐渐缩小范围,聚焦于最有可能的正确推理路径。这种从发散到收敛的推理过程体现了模型在潜在空间中的推理能力。
为什么潜在空间更适合规划?
在本节中,研究团队探讨了潜在推理在规划中的优势。例如,图 6 中的“sterpus”是一个叶节点,无法通向目标节点“bompus”,很容易被识别为不正确的选项。相比之下,其他节点有更多的后续节点需要探索,使得推理更加困难。
研究团队通过测量树中节点的高度(到叶节点的最短距离)来量化探索潜力。他们发现,由于勘探潜力有限,海拔较低的节点更容易评估。在图 6 中,模型显示高度为 2 的“grimpus”和“lempus”节点具有更大的不确定性。
为了更严格地检验这一假设,研究团队在测试集中分析了第一步和第二步潜在推理过程中模型预测概率与节点高度之间的相关性。图9揭示了一种模式:当节点高度较低时,模型为不正确的节点分配较低的值,为正确的节点分配较高的值。
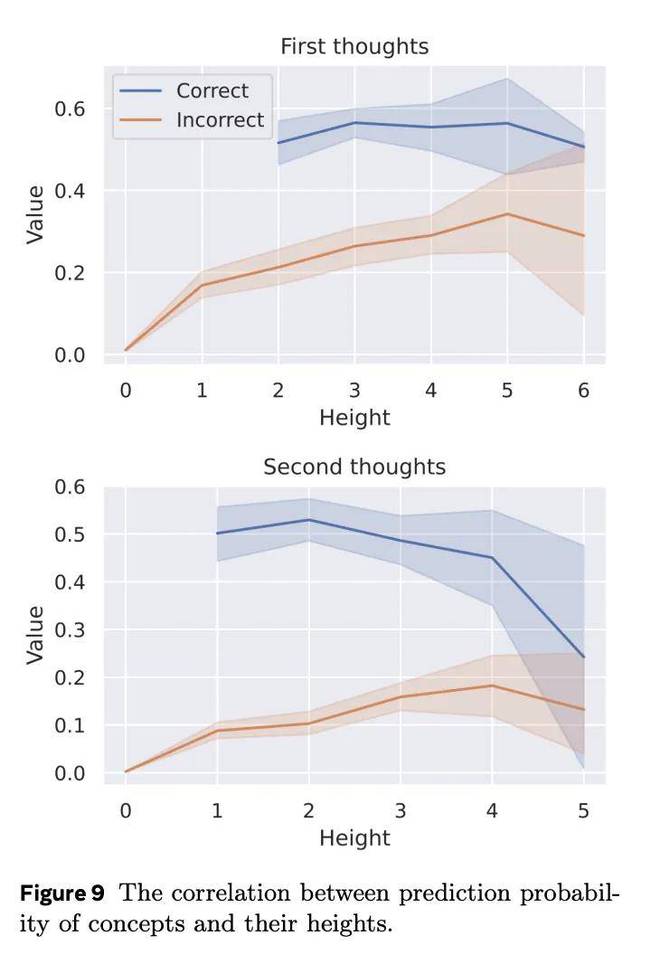
然而,随着节点高度的增加,这种区别变得不那么明显,表明评估难度增加。总之,这些发现凸显了利用潜在空间进行规划的优势。该模型通过延迟决策并在底层推理过程中探索节点,最终将搜索推向树的最终状态,从而更容易区分正确和错误的节点。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/273201.html
