
近日,Ilya 在 NeurIPS 2024 上宣布:预训练结束!一石激起千层浪。

作为OpenAI前首席科学家,Ilya的话可能会影响未来几十年AI的发展方向。
然而,预训真的结束了吗?
近日,几位业内大佬公开站出来质疑和反对Ilya。
谷歌老板Logan Kilpatrick对Ilya有这样的内涵:如果你认为预训练已经结束,恐怕是因为你缺乏想象力。
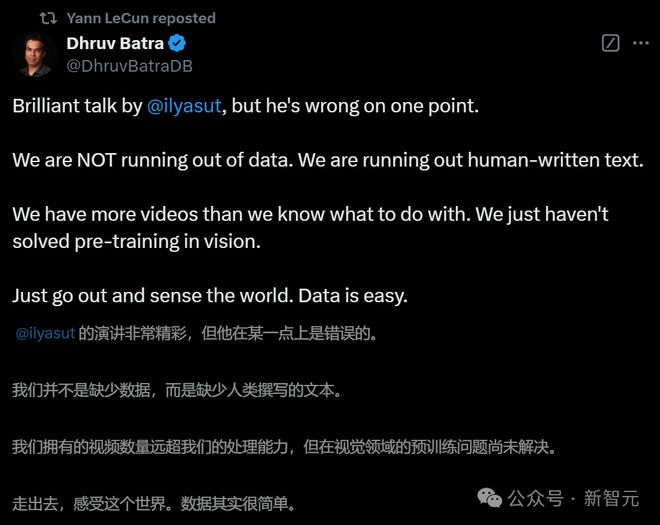
Meta具身智能团队前高级总监Dhruv Batra也站出来联名表示:Ilya错了!
在他看来,人类尚未用尽其数据。
我们刚刚用完了人类编写的文本,但我们拥有的视频数量仍然远远超出了我们的处理能力。只是视觉领域的预训练问题还没有解决。
确实,要知道,互联网上的文字公开数据毕竟只是冰山一角。
除了文本之外,我们还可以预训练音频、视频和图像,甚至可以赋予机器人类进化出的视觉、嗅觉、触觉、平衡和传感器等功能。
而如果模型真的能够学习,那么数据可能确实无处不在。
向左或向右滑动即可查看
有人天马行空:如果预训练能和生物联系起来,那确实永无止境。
缩放法则和预训练是否遇到了障碍?
种种事件表明,我们的发展已经到了一个分水岭。
伊利亚、LeCun甚至奥特曼都感到目前的发展道路已经无法继续下去,我们迫切需要探索新的出路。
早期,Ilya 是暴力扩展的早期倡导者之一,认为通过增加数据和计算能力来“扩展”可以显着提高模型性能。


近日,Epoch AI研究人员的一篇长文直观地论证了这种“矛盾”现象。

从2017年Transformer架构的诞生到GPT-4的发布,SOTA模型的规模一直在增长,但增长速度却变得更小。
到了2023年,这一趋势直接逆转。
估计目前SOTA模型的参数可能比GPT-4的1.8万亿小一个数量级!
但有趣的是,下一代模型的规模可能会再次超过 GPT-4。

如今的SOTA模型最多只有约4000亿个参数。
尽管许多实验室没有公开他们的模型架构,但 Epoch AI 的研究人员仍然发现了线索。
第一个是开源模型的证据。根据Artificial Analysis的模型质量指数,目前最好的开源模型是Mistral Large 2和Llama 3.3,分别拥有1230亿和700亿个参数。
这些密集模型在架构上与 GPT-3 类似,但参数较少。它们的整体基准性能超过了 GPT-4 和 Claude 3 Opus,并且由于参数较少,它们的推理成本和速度也更好。
对于闭源模型,虽然我们通常不知道参数细节,但我们可以根据推理速度和费用来猜测它们的大小。
仅考虑短上下文请求,OpenAI 提供的 2024 年 11 月版本的 GPT-4o 每个用户每秒有 100-150 个输出代币,每百万个输出代币收费 10 美元;而GPT-4 Turbo每秒最高约55个输出代币的费用为每百万个输出代币30美元。
显然,GPT-4o 比 GPT-4 Turbo 更便宜、速度更快,因此它的参数很可能比 GPT-4 小很多。
此外,我们还可以利用推理经济学的理论模型来预测GPT-4在H200上的推理成本。
假设使用 H200 进行推理的机会成本为每小时 3 美元,下图显示了 GPT-4 及其假设的缩小版在不同价格点的生成速度。
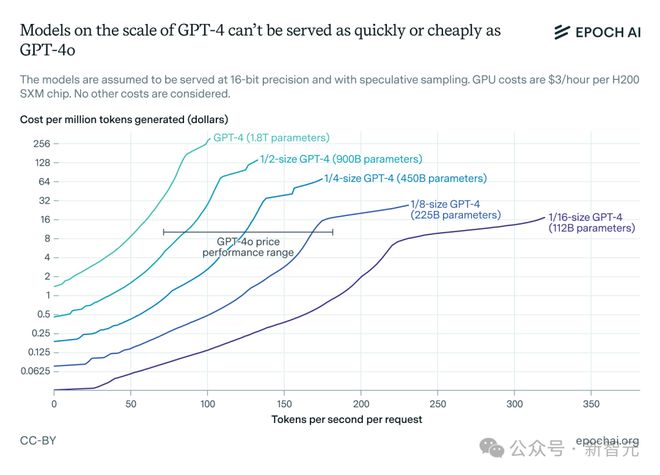
总体而言,为了让模型每秒生成超过 100 个代币并顺利服务,模型需要比 GPT-4 小得多。
根据上图,假设OpenAI的价格加成约为GPU成本的八分之一,则GPT-4o的参数数量可能在2000亿左右,尽管这个估计可能有2倍的误差。
有证据表明 Anthropic 的 Claude 3.5 Sonnet 可能比 GPT-4o 更大。 Sonnet 每秒生成大约 60 个代币,每百万个输出代币收费 15 美元。这个速度已经接近原始 GPT-4 在优化设置下的盈亏平衡点。
不过,考虑到Anthropic API可能会大幅提高价格,Sonnet的参数大小仍然明显小于GPT-4,估计在4000亿左右。
总体来看,目前尖端模型的参数大多在4000亿左右,其中Llama 3.1 405B和Claude 3.5 Sonnet可能是最大的。
尽管闭源模型的参数估计存在较大的不确定性,但我们仍然可以推测,从 GPT-4 和 Claude 3 Opus 到当今最强模型的规模缩减可能接近一个数量级。
为什么会发生这种情况?
针对这一现象,Epoch AI认为主要原因有四个:
1. AI需求爆发,模型必须瘦身。
自ChatGPT和GPT-4发布以来,人工智能产品的需求激增,服务提供商面临着远远超出预期的推理请求。
此前,2020年至2023年3月,模型训练的目标是最小化训练计算量,即在固定能力水平下花费尽可能少的计算资源完成训练。 Kaplan 和 Chinchilla 的缩放定律表明,随着训练计算量的增加,模型大小也应该增加。
由于推理成本占主导地位,传统规则的适用性受到挑战。与缩放模型大小相比,在更多训练数据(token)上训练较小的模型更具成本效益,因为较小的模型在推理阶段的计算要求较低,可以以较低的成本为用户服务。
例如,从Llama 2 70B到Llama 3 70B,虽然模型参数大小没有明显增加,但模型的性能明显提高。
这是因为通过过度训练(在更多数据上训练较小的模型),模型可以在保持较小规模的同时变得更强大。
2、蒸馏让小模型更具可玩性
该实验室还使用“蒸馏”方法使更小的模型变得更强大。
蒸馏是指让小模型模仿已经训练好的大模型的性能。
蒸馏的方法有很多种,一种简单的方法是使用大模型生成高质量的合成数据集来训练小模型,而更复杂的方法需要访问大模型的内部信息(例如隐藏状态和对数概率) )。
Epoch AI 认为 GPT-4o 和 Claude 3.5 Sonnet 很可能是从更大的模型中提炼出来的。
3. 缩放法则的变化
Kaplan Scaling Law(2020)建议模型的参数数量和用于训练的 token 数量(即数据量)应保持较高的比例。简单地说,当你增加训练数据时,你应该相应地增加模型的大小(参数数量)。
Chinchilla Scaling Law (2022) 有利于更多的训练数据和更少的参数。模型不必变得越来越大,关键是训练数据的大小和多样性。
这种转变导致了训练方法的变化:模型变得更小,但训练数据更多。
从 Kaplan 到 Chinchilla 的转变并不是因为推理要求的增加,而是因为我们对如何有效扩展预训练的理解发生了变化。
4. 更快的推理和更小的模型
随着推理方法的改进,模型生成令牌的效率和低延迟变得更加重要。
过去,判断一个模型“足够快”的标准是它的生成速度是否接近人类的阅读速度。
然而,当模型在生成每个输出token之前需要推断多个token时(例如,每个输出token对应10个推理token),提高生成效率就变得更加关键。
这促使 OpenAI 等实验室专注于优化推理过程,以便模型在处理复杂的推理任务时能够更高效地运行,从而促使他们缩小模型的规模。
5.用AI喂AI,成本更低
越来越多的实验室开始使用合成数据作为训练数据的来源,这也是使模型变得更小的原因之一。
合成数据提供了一种新的训练计算缩放的方法,超越了增加模型参数数量和训练数据集大小的传统方法(即超出预训练计算缩放)。
我们可以为未来的训练生成代币,而不是从互联网上抓取它们,就像 AlphaGo 通过与自己对弈来生成训练数据一样。
这样,我们可以在 Chinchilla Scaling Law 下保持 token 与参数的计算最佳比率,但通过在生成数据时为每个 token 投入更多的计算量,在不增加模型大小的情况下增加训练计算量。
奥特曼:参数尺度大赛快结束了吗?
2023年4月,OpenAI发布了GPT-4,这是当时最强的模型,也是第一个参数未公开的模型。
不久之后,CEO Altman就预言了模型参数竞争的终结:围绕模型参数数量的竞争,就像历史上追求更高的处理器频率一样,是一个死胡同。

那么,尖端车型的规模会不会越来越小呢?
简短的回答是——可能不会。但也很难说我们是否应该期望它们在短期内变得比 GPT-4 更大。
从 Kaplan 到 Chinchilla 的转变是一次性的,因此没有理由期望它会继续缩小模型。
GPT-4 发布后的推理需求也可能比未来的推理支出增长得更快。而且合成数据和尺度计算并不是每个实验室都采用的——即使有高质量的训练数据,对于非常小的模型,能够取得的成就可能也非常有限。
此外,硬件的进步可能会导致更大的模型变得更好,因为在相同的预算下,更大的模型通常表现更好。
较小的模型在推理方面可能表现较差,尤其是在长上下文和复杂任务上。
未来的模型(如 GPT-5 或 Claude 4)可能会恢复到或略超过 GPT-4 的大小,并且很难预测此后规模是否会继续缩小。
理论上,当前的硬件足以支持比 GPT-4 大 50 倍的模型和约 100 万亿个参数,可能以每百万输出代币 3,000 美元和每秒 10-20 个代币的速度提供服务。
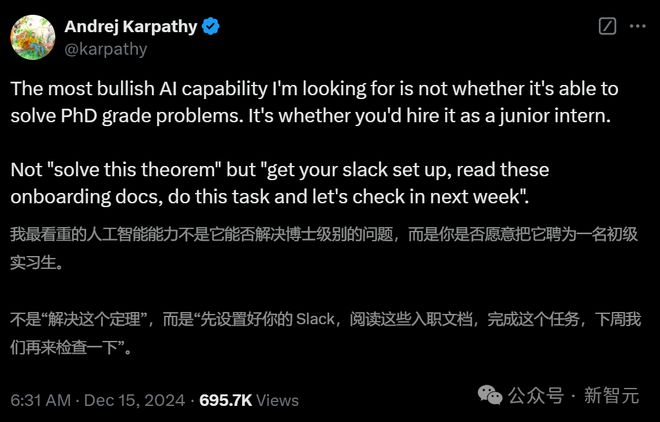
但正如卡帕蒂所说,与如今只能根据提示解决博士级别问题的人工智能相比,真正能够以“实习生”身份加入的人工智能更加实用。
参考:
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/273344.html
