
OpenThinker-32B推理模型发布:仅用1/8数据与DeepSeek-R1打成平手,性能碾压李飞飞团队s1和s
32B推理模型仅使用1/8的数据,与相同大小的DeepSeek-R1绑定!
刚才,来自斯坦福大学,加州大学伯克利分校,华盛顿大学和其他机构的机构共同发布了SOTA级推理模型-Openthinker-32B,还开放了114K培训数据。


项目主页:
拥抱脸:
数据集:
该团队发现,使用带有DeepSeek-R1验证(基于R1蒸馏)的大规模高质量数据集可以训练SOTA的推理模型。
具体方法是扩展数据,推理过程验证和模型量表扩展。
从此获得的Openthinker-32b导致了多个基准测试,例如数学,代码和科学。 Openthinker-32B的性能直接粉碎了Li Feifei团队的S1和S1.1型号,并且接近R1-Distill-32B。
值得一提的是,与使用800K数据(包括600K推理样本)的R1 distill相比,Openthinker-32B仅使用114K数据可以实现几乎相同的出色结果。

结果由开源评估框架Resthemy计算。
此外,Openthinker-32还披露了所有模型权重,数据集,数据生成代码和培训代码!
数据策划
研究人员使用了与以前训练的Openthinker-7b模型相同的Openthights-114K数据集来训练Openthinker-32B。
他们使用DeepSeek-R1模型来收集精心选择的推理过程和解决方案,以解决173,000个问题。然后将这些原始数据公开发布为Openthoughts-173K数据集。
整个过程的最后一步是,如果推理过程未能通过验证,则过滤相应的数据示例。
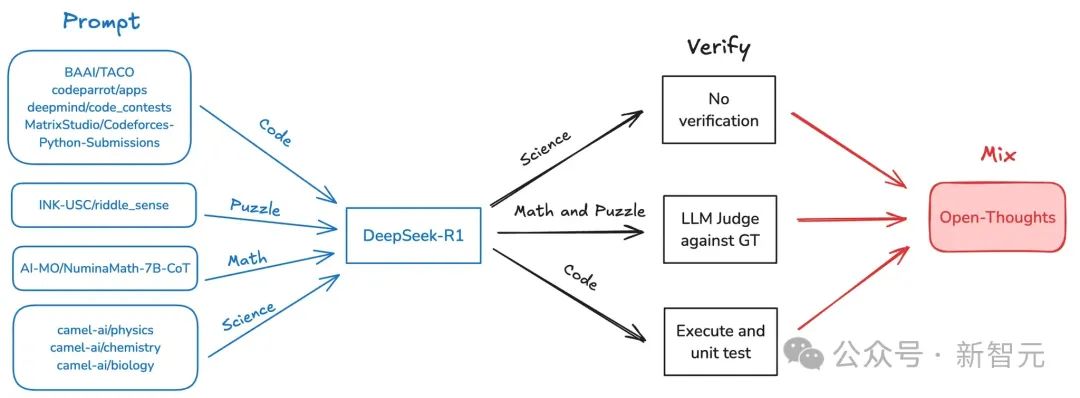
以下图像在视觉上显示了整个过程。
研究团队首先输入源数据或问题提示。这些内容可能来自不同的领域和平台,例如Baai/Taco,DeepMind,Python提交等,涉及多个方面,例如代码,难题,科学和数学。
然后,这些不同的输入将进入核心处理模块-DeepSeek -R1,在该模块中分析和处理数据。这些问题将分为三个方面:科学问题,数学,难题和代码。
一些结果不需要验证,可能是简单的分析或直接输出。对于需要深入验证的某些内容,大语言模型(LLM)用于将其与GT(地面真相)进行比较。如果是代码,请执行代码并执行单元测试,以确保代码的正确性和有效性。
最后,我们可以将结果结合在一起,以产生开放思维和更全面的解决方案。
研究团队更新了最终的Openthights-114k数据集,并添加了一种称为“元数据”的配置,该配置包含一些用于数据集构建的其他列:
此额外的元数据将使该数据集更容易在新方案中使用,例如数据过滤,域切换,验证检查和用于推理过程的更改模板。
此额外的元数据将使数据集更易于使用,并且只需一行代码即可完成,例如过滤,更改域,检查验证和更改推理跟踪模板。
1 load_dataset(“开放式思想/openthights-114k”,“元数据”,split =“ train”)
研究小组表示,他们期待看到社区使用这些问题和标准答案,以对Openthinker模型进行有关强化学习(RL)的研究。 DeepScaler证明,这种方法在小规模上特别有效。
核实
为了获得最终的Openthights-1114k数据集,研究团队验证了答案并消除了错误的答案。
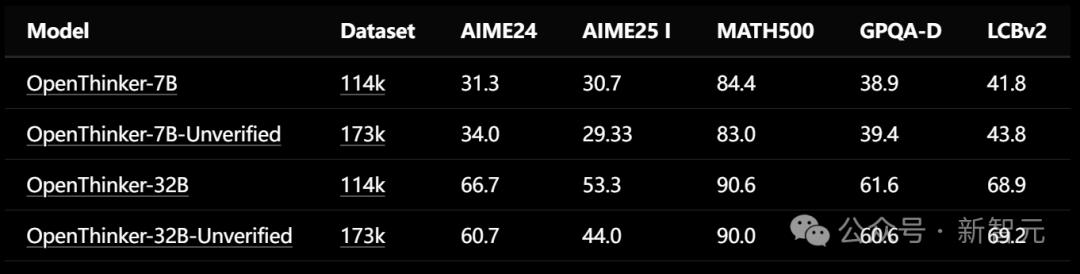
如下表所示,保留那些无法通过验证的推理过程可能会损害性能,尽管与其他32B推理模型相比,未验证的模型仍然表现良好。
验证的作用是保持R1注释的质量,同时扩大培训及时设置的多样性和规模。另一方面,未验证的数据可以更容易扩展,因此值得进一步探索。
对于代码问题,我们通过比较现有测试用例以完成推理过程的验证来验证解决方案尝试。
受代码执行期间挑战的启发,我们在策展人中实现了一个代码执行框架,允许用户大规模执行代码,并安全地执行代码,并验证预期的输出。
对于数学问题,研究团队使用LLM(大型语言模型)审查来验证它将同时获得标准答案和DeepSeek-R1的解决方案尝试。
已经发现,在数据生成过程中,使用LLM判断器而不是更严格的解析引擎(数学验证)进行验证可以获得更高的有效数据速率,并以更好的性能训练下游模型。

火车
研究小组使用Llama-Factory在Openthoughts-114k数据集上进行三轮微调,上下文长度为16K。完整的培训配置可以在GitHub中找到。
Openthinker-32B在AWS Sagemaker群集上训练了90小时,总共使用了2,880 H100小时。
同时,使用96 4XA100节点(每GPU 64GB)在Leonardo SuperCutiter上进行了30小时的Openthinker-32B无用的训练,并使用了11,520 A100小时。
评价
研究小组使用开源评估库评估(Alchemy)来评估所有模型。
对于AIME24和AIME25,他们通过平均五个运行的结果来计算准确性。评估配置使用0.7的温度参数,将模型响应限制为32,768代币,而无需添加任何其他系统或用户提示单词,而无需使用任何特殊的解码策略(例如预算强制性)。
在启动Opthought项目时,他们设定了一个目标,可以创建一个可以实现DeepSeek-R1-Distill-Qwen-32b的开放数据模型。
现在,这个差距几乎消失了。
最后,研究团队对社区在过去几周建立开放数据推理模型方面所取得的快速进步感到兴奋,并期待继续根据彼此的见解继续前进。
Openthinker-32B的开源证明,数据,验证和模型量表之间的协同作用是提高推理能力的关键。
这项成就不仅促进了开源推理模型的发展,而且还为整个AI社区提供了宝贵的资源和灵感。
参考:
本文来自编辑:编辑HNYZ的微信公共帐户“ Xinzhiyuan”,并于36KR授权出版。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/274186.html
