

聪明的东西
由Chen Junda编译
编辑panken
吉文Xi在2月18日报道说,今天下午,DeepSeek团队发布了一篇新论文,推出了改进的稀疏注意机制NSA,可用于超快速的长期培训和推理。 NSA很少以具有成本效益的方式在培训阶段应用稀疏性,并且在训练和推动方案的速度方面取得了重大改善,尤其是在解码阶段,可提高11.6倍。
引人注目的是,DeepSeek创始人兼首席执行官Liang Wenfeng这次出现在联合列表上,在作者排名中排名第二。这意味着,作为项目经理,他参与了一线研究工作。此外,该论文的第一作者Jingyang Yuan在实习期间完成了研究。

根据DeepSeek的说法,NSA具有三个核心组成部分:动态分层稀疏策略,粗粒的令牌压缩和细粒的令牌选择。通过三个主要组成部分的合作,效率不仅提高了,而且还保留了模型的感知能力和全球环境的局部准确性。
这种机制是专门为现代硬件设计的,本地支持模型培训,该培训降低了训练成本的同时加速推理,并且对性能没有重大影响。使用NSA机制的模型可与一般基准,长上下文任务和基于指导的推理中的全部注意力模型相比或表现更好。
在8卡A100计算集群中,NSA的正向传播和后退速度分别比完全注意的速度分别快9倍和6倍。由于记忆访问的减少,与全注意模型相比,在解码长序列时,NSA与全注意模型进行了比较。速度大大提高。

▲在某些测试中NSA的性能(照片来源:DeepSeek)
纸张链接:arxiv.org/abs/2502.11089
1。现有的稀疏注意机制存在明显的缺陷,DeepSeek希望填补空白
长文本建模是下一代语言模型的关键能力,但是传统注意机制的高复杂性限制了其在长序列上的应用。
例如,在解码64k长度的上下文时,注意计算占总延迟的70%至80%。因此,出现了稀疏的注意机制,以选择性计算查询键的钥匙对来减少计算开销。
但是,尽管理论上许多稀疏注意方法可以降低计算复杂性,但这些方法无法显着降低实际推理的延迟。
某些方法仅在自回归解码阶段应用稀疏性,而预填充阶段仍然需要大量计算(例如H2O)。其他人只专注于预填充阶段的稀疏度(例如终结),从而导致某些工作量下的失败。达到全阶段加速。
还有一些稀疏的方法无法适应现代有效的解码体系结构(例如MQA和GQA),从而导致KV高速缓存访问的数量仍然很高,并且无法充分利用稀疏性的优势。
此外,大多数现有的稀疏注意方法仅在推理阶段应用稀疏性,并且缺乏对训练阶段的支持。
NSA的目的是通过加速以推理为导向的硬件功能和设计培训算法来填补这一空白。 DeepSeek推出了NSA解决两个主要问题:
首先,事件后的稀疏度导致性能退化,例如预训练模型的搜索头很容易修剪;
其次,现有的稀疏方法很难应对长期培训的效率要求。现有方法存在诸如不可验证的组件和效率低下的问题,这阻碍了有效的培训和长上下文模型的发展。
2。对软件和硬件协作的深入优化,以及无限近似计算强度的最佳解决方案
NSA的核心思想是通过动态层次的稀疏策略来保留全球环境意识和局部准确性,将粗粒的令牌压缩和细粒度的代币选择结合在一起。
以下是NSA体系结构的概述。在左侧,NSA通过三个平行的注意分支处理输入序列:压缩注意力,选择注意力和窗户注意力滑动。右边是每个分支生成的不同注意力模式的可视化。绿色区域表示需要计算注意力评分的区域,而白色区域表示可以跳过的区域。
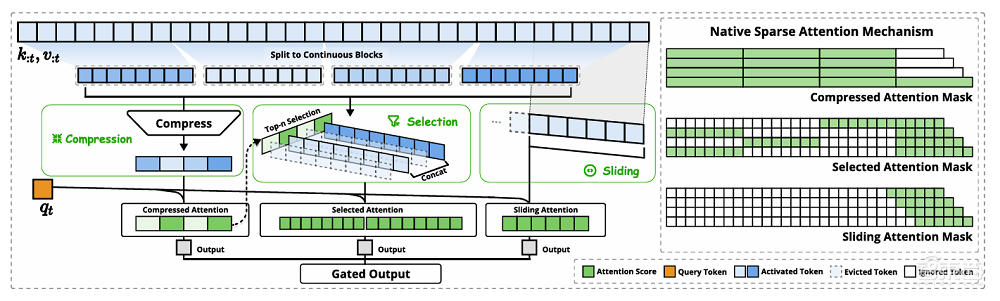
▲NSA体系结构的概述(照片来源:DeepSeek)
压缩注意力通过将键和值汇总为块级表示,从而捕获了粗粒的语义信息。这种压缩表示可以捕获粗粒度的高级语义信息,并减轻注意力计算的负担。
但是,仅使用压缩键和值可能会失去重要的细粒度信息,而DeepSeek通过块选择机制引入了选择性的关注,以保留重要的细粒度信息。
他们为每个块分配重要性得分,根据块的重要性得分选择顶部n个块,然后在这些块中使用标记进行注意计算。此方法在保留关键信息的同时大大减轻了计算负担。
在注意机制中,局部模式通常会迅速适应和主导学习过程,这可能会阻碍模型从压缩和选择令牌中有效学习。通过关注本地上下文信息,以防止模型过度依赖本地模式,可以通过窗口关注来响应此问题。
为了实现有效的稀疏注意计算,NSA还针对现代硬件进行了优化。
具体而言,DeepSeek在Triton上实现了与硬件一致的稀疏注意内核。鉴于多头自我注意力(MHA)是记忆密集型且在解码方面效率低下,因此他们专注于共享KV缓存的架构,例如分组查询注意(GQA)和多Query Guate(MQA),这些架构与与之一致的构造(MQA)当前最先进的LLMS。 。
DeepSeek的主要优化策略是采用不同的查询分组策略,通过以下关键特征实现了几乎最佳的计算强度平衡:
1。以组为中心的数据加载:在每个内部循环中,组中的所有标题及其共享的稀疏KV块索引都加载。
2。共享的KV加载:在内部循环中,KV块连续加载以最大程度地减少内存加载。
3。网格循环调度:由于内部循环长度在不同的查询块中几乎相同,因此将查询/输出环放在Triton的网格调度程序中,以简化和优化内核。
3。超越许多基线模型,加快训练6-9次,最大推理速度提高了11.6倍
为了测试NSA机制在实践培训和推理方案中的性能,DeepSeek使用最先进的LLM常见实践来使用将分组查询注意(GQA)和混合专家(MOE)作为示例模型的骨架结构。该模型中参数的总数为27B,其中3B是活动参数。
基于此模型,DeepSeek使用了NSA,全部关注和其他注意机制,并进行了评估。
在多个一般基准测试中,使用NSA的模型比所有基线模型(包括全部注意力模型)具有更好的总体性能,其中7个指标中有7个指标。
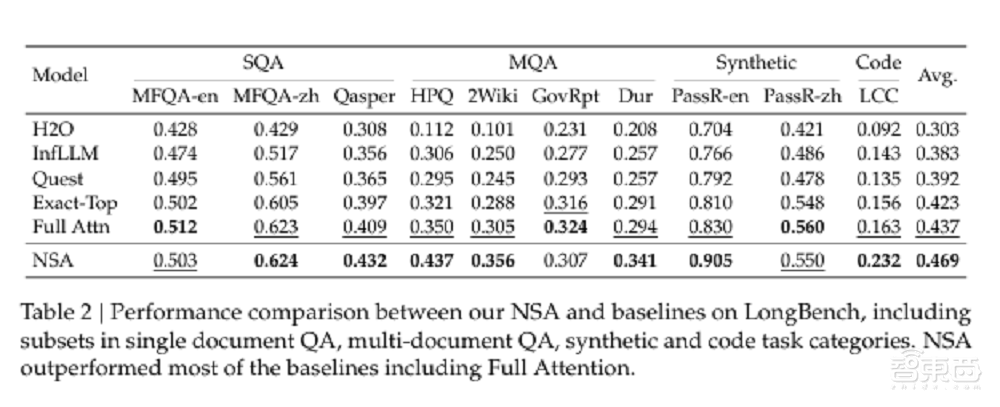
▲使用多个共同基准上的不同注意机制的模型表现(照片来源:DeepSeek)
NSA可能无法完全利用其效率优势在较短的序列上,但其性能仍然很强。值得注意的是,NSA已在推理相关的基准测试方面取得了重大改进,这表明NSA的训练前机制有助于建模开发专门的注意机制,这可以迫使该模型专注于最重要的信息并过滤掉最重要的噪声中的噪音。注意路径可能会提高性能。
在长篇小说任务中,NSA在64k上下文中的“ Haystack”测试中实现了超级回归精度。这要归功于其层次稀疏的注意力设计,从而通过粗粒粒度的压缩令牌扫描有效的全球环境,并通过细粒度的选择标记保留关键信息,从而在全球感知和局部准确性之间保持平衡。

▲测试结果用于在干草堆中寻找针的结果(照片来源:DeepSeek)
在Longbench上,NSA在多跳QA任务和代码理解任务中胜过所有基准,并且还显示了复杂的长文本推理任务中的优势。这些结果表明,NSA的本地稀疏注意机制不仅改善了模型性能,而且还为长期文本任务提供了更好的解决方案。
NSA机制也可以与推理模型相结合,以适应尖端的训练后方法。 DeepSeek使用从DeepSeek-R1蒸馏获得的知识和监督微调(SFT),以使NSA模型能够在32K长度的数学推理任务上获得链接的数学推理能力。
在实验中,在具有挑战性的AIME 24基准上比较了NSA-R(稀疏注意变体)和Full Coation-R(基线模型)。结果表明,在8K和16K上下文设置(分别为0.075和0.054),NSA-R明显优于完全注意力-R,从而在复杂的推理任务中验证了其优势。

▲AIME(照片来源:DeepSeek)的NSA-R(稀疏注意变体)和全部注意力R(基线模型)的性能
DeepSeek还将NSA的计算效率与8-GPU A100系统的全部注意力机制进行了比较。
就训练速度而言,随着上下文长度的增加,NSA的加速效应变得越来越重要。在64K上下文长度时,NSA的正向传播速度提高了9倍,而后繁殖速度增加了6倍。
这种加速度主要是由于NSA的硬件对齐设计:块状内存访问模式通过合并加载来最大化张量的核心利用率,而内核中的细循环调度则消除了冗余的KV传输。
就解码速度而言,注意机制的解码速度主要受KV缓存负载的内存瓶颈的限制。随着解码长度的增加,NSA的潜伏期大大降低,在64K上下文长度下,速度的增加高达11.6倍。随着序列长度的增加,内存访问效率的这种优势变得更加明显。
结论:DeepSeek继续使开源AI感到惊讶
尽管NSA取得了重大结果,但DeepSeek研究团队还指出了一些可能的改进方向。例如,进一步优化了稀疏注意模式的学习过程,并探索更有效的硬件实现。
就像DeepSeek之前发布的所有技术报告一样,本文详细解释了NSA机制,对NSA机制中涉及的技术细节有了明确的解释,并且具有高度运行。这是DeepSeek对开源AI研究的贡献的最新成就。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/274316.html
