
AI2研究学院推荐了DeepSeek团队的最新杰作,并与DeepSeek粉丝一起研究了!他们提出的新Codei/O方法通过代码提取了LLM推理模式,并在逻辑和数学等推理任务上有了显着改进。
如今,DeepSeek团队成员的每一步都吸引了圈子的广泛关注。
最近,AI2巨头Nathan Lambert推荐了DeepSeek,Shanghai Jiaotong University和香港科学技术大学的研究人员推出的新杰作Codei/O!

兰伯特说,很高兴看到DeepSeek团队成员撰写的更多论文,而不仅仅是有趣的技术报告。 (顺便说一句,我还开玩笑说我真的很想念他们)
本文的主题是使用Codei/O方法使用代码输入/输出来提取LLM的推理模式。
值得注意的是,本文是Junlong Li在DeepSeek实习期间完成的一项研究。
发布后,网民立即开始仔细研究。毕竟,DeepSeek现在是研究人员心目中的山羊团队。

有人得出结论,除了主要论文外,DeepSeek作者还发表了许多论文,例如Prover 1.0,ESFT,Fire-Flyer-Flyer Ai-HPC,Dreamcraft 3D等。尽管它们都是实习生的作品,但它们非常非常鼓舞人心。

01 LLM推理缺陷,被代码打破
推理是LLM的核心能力。先前的研究集中在改善诸如数学或代码之类的狭窄领域,但LLM在许多推理任务中仍然面临挑战。
原因是训练数据稀疏且分散。
在这方面,研究团队提出了一种新方法-Codei/O!
Codei/O通过将代码转换为输入/输出预测格式,系统地提取代码上下文中包含的多个推理模式。
研究团队建议将原始代码文件转换为可执行函数并设计了更直接的任务:给定一个函数及其相应的文本查询,该模型需要以自然的cot推断形式预测给定输入的执行输出给定输出的语言或可行输入。
这种方法可以从特定于代码的语法中释放核心推理过程,同时保留逻辑严格。通过从不同来源收集和转换功能,生成的数据包含各种基本推理技能,例如逻辑过程编排,状态空间探索,递归分解和决策。
实验结果表明,Codei/O在符号推理,科学推理,逻辑推理,数学和数值推理以及常识推理等任务中实现了一致的绩效改进。
下面的图1总结了Codei/O的培训数据构建过程。该过程首先收集原始代码文件,并以组装完整的培训数据集结束。
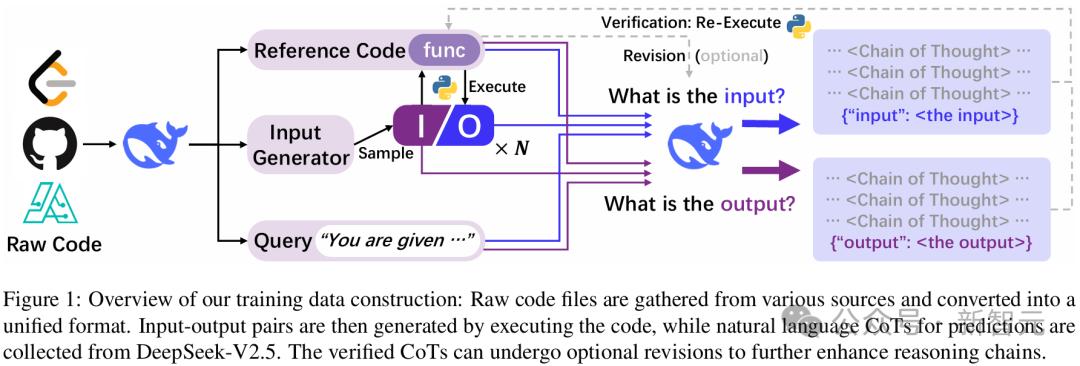
02分解代码/O架构以收集原始代码文件
Codei/O的有效性在于选择多种原始代码来源以涵盖广泛的推理模式。
主要代码源包括:
CODEMIX:大量原始Python代码文件从内部代码预训练语料库中检索到,被过滤以删除太简单或太复杂的文件。
PYEDU-R(推理):Python-EDU的一个子集,重点是复杂的推理任务,例如STEM,系统建模或逻辑难题,并排除了以纯算法为中心的文件。
其他高质量的代码文件:来自各种知名的小型资源,包括综合算法存储库,具有挑战性的数学问题和众所周知的在线编码平台。
合并这些来源后,总共生成了约810.5k代码文件。

构造的LeetCode-O基准测试的一个示例
转换为统一格式
收集的原始代码文件通常是混乱的,包含冗余内容,并且难以独立执行。
原始代码文件使用DeepSeek-V2.5进行了预处理,并将其精制成统一的格式,强调了主要的逻辑功能,以使其可执行以收集输入输出对。
研究团队清理并重构代码,将核心逻辑函数提取到功能中,排除不必要的元素,然后添加一个主切入点函数以总结代码的整体逻辑。
该功能可以调用其他功能或导入外部库,并且必须具有非空参数(输入)以及返回有意义的输出。所有输入和输出都需要序列化以进行进一步处理。
在此过程中,需要明确定义主入口点功能的输入和输出,包括数据类型,约束(例如,输出范围)或更复杂的要求(例如,字典中的键)。
然后创建一个独立的,基于规则的Python输入生成器函数,而不是直接生成测试用例。该发电机返回遵循主入口点功能要求的非平地输入。在约束下应用随机性以实现可扩展的数据生成。
最后,基于主入口点函数将生成一个简洁的问题语句,作为描述代码预期功能的查询。

如何将原始代码文件转换为所需的相同格式的示例
收集输入和输出对
将所收集的原始代码文件转换为统一格式后,使用输入发生器为每个功能采样多个输入,并通过执行代码来获得相应的输出。
为了确保输出是确定性的,所有包含随机性的函数都会跳过。在执行这些代码期间,研究团队还对运行时和输入/输出对象的复杂性施加了一系列限制。
滤除了不可证实的代码后,超过运行时限制的样本以及超过所需复杂性的输入输出对,获得了从454.9k的原始代码文件得出的350万个实例。输入和输出预测实例的分布大致平衡,分别为50%。
构建输入和输出预测样本
收集输入输出对和转换功能后,需要将它们组合成可训练的格式。
研究小组采用了一个监督的微调过程,每个培训样本都需要及时和回应。由于目标是输入输出预测任务,因此研究团队使用了设计的模板来组合函数,查询,参考代码以及特定的输入或输出,以构建提示。
理想情况下,响应应该是一种自然语言COT,用于推理如何获得正确的输出或可行输入。
研究团队主要通过两种方式构建所需的COT响应。
直接提示(codei/o)
与DeepSeek-V2.5合成所有必需的响应,因为它具有一流的性能,但成本极低。此处生成的数据集称为Codei/O。
下图2显示了Codei/O数据集中输入和输出预测的两个示例,在这两种情况下,模型都需要以自然语言链(COT)的形式给出推理过程。

充分使用代码(Codei/O ++)
对于预测错误的响应,反馈将作为第二轮输入消息附加,并且需要DeepSeek-V2.5才能再生其他响应。连接所有四个组件:第一轮响应 +第一轮反馈 +第二轮响应 +第二轮反馈。研究人员将收集的数据集称为Codei/O ++。

Codei/O ++的完整培训样本
03一个框架弥合了代码推理和自然语言之间的差距
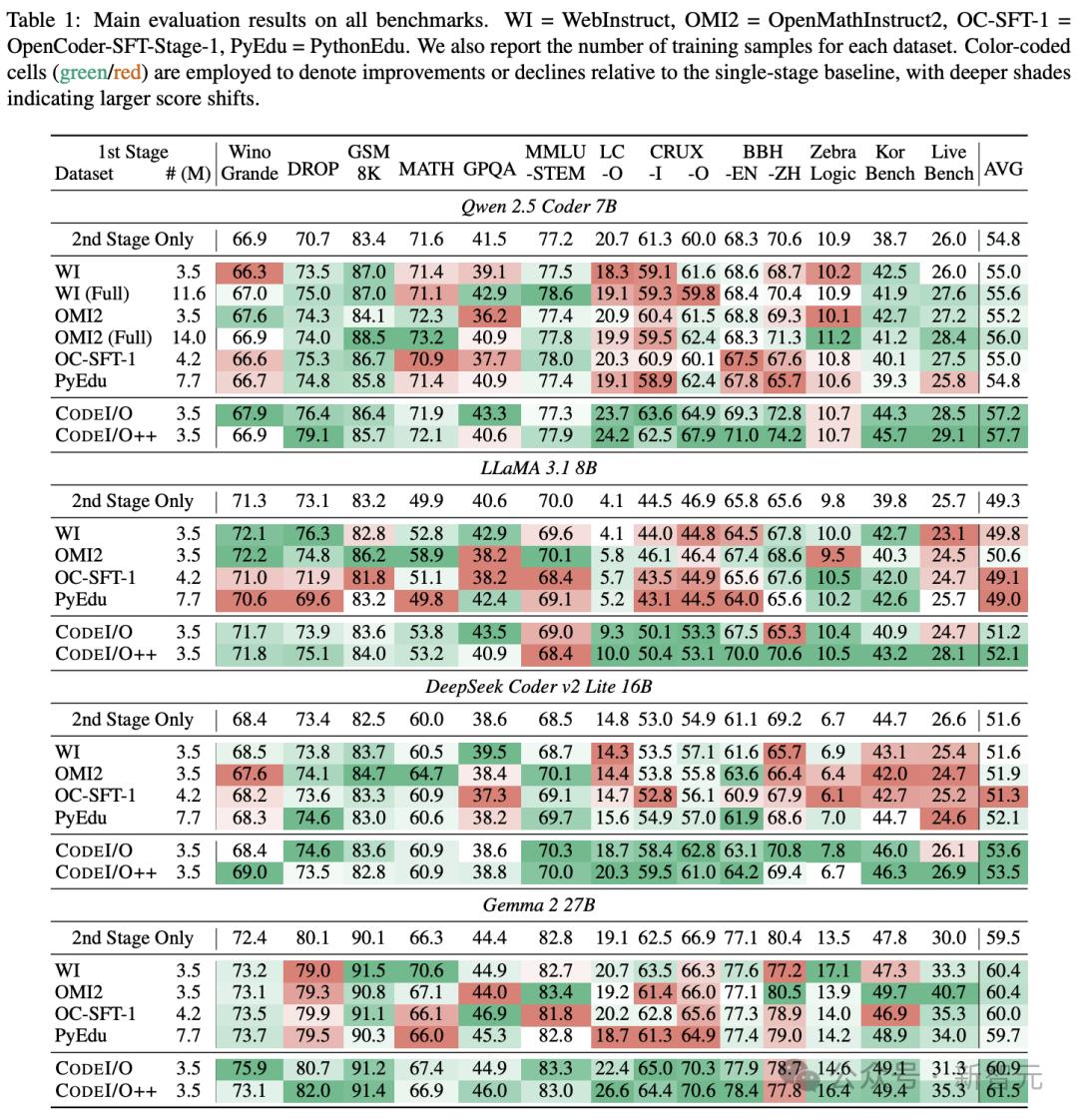
如下表1所示,QWEN 2.5 7B编码器,DeepSeek V2 Lite编码器,Llama 3.1 8B和Gemma 2 27B模型的评估结果主要显示。
Codei/O在所有基准测试中都提高了其性能,该基准的表现优于单阶段基线模型和其他数据集(甚至更大的数据集)。
但是,诸如OpenMathInstruct2之类的竞争数据集在特定于数学的任务上表现良好,但是其他任务上有回归(混合绿色和红色单元格)。
Codei/O显示了连续改进的趋势(绿细胞)。
尽管它仅使用以代码为中心的数据,但它提高了代码推理功能,同时还可以增强所有其他任务的性能。
研究人员还观察到,与单级基准相比,使用原始代码文件(Pythonedu)进行培训只能带来微小的改进,有时甚至是负面影响。
与Codei/O相比,该性能的表现明显不足,这表明从结构不佳的数据中学习是次优的。
这进一步强调了绩效的改进,不仅在数据大小上,而且更重要的是在精心设计的培训任务上。
这些任务包括广义思维链中的各种和结构化的推理模式。
此外,Codei/O ++系统地超过了Codei/O,改善了平均分数而不会影响单个任务的执行。
这重点介绍了基于执行反馈的多轮修订,可以提高数据质量并增强跨域推理能力。
最重要的是,Codei/O和Codei/O ++在模型规模和体系结构中都表现出通用的有效性。
这进一步验证了实验的训练方法(预测代码输入和输出),从而使模型在各种推理任务中都可以很好地执行,而无需牺牲专业的基准性能。
为了进一步研究新方法的不同关键方面的影响,研究人员进行了多组分析实验。
使用QWEN 2.5编码器7B模型进行所有实验,并在对第二阶段的一般说明进行微调后获得了报告的结果。
消融实验
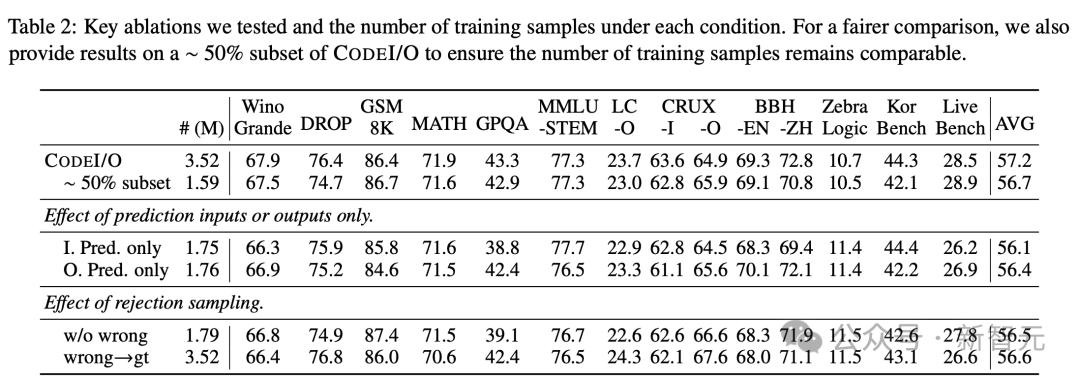
研究小组首先对数据构建过程进行了两项关键的消融研究,结果如下表2所示。
输入/输出预测
作者通过单独的培训研究输入和输出预测。
结果表明,整体得分相似,但是输入预测在Korbench上表现良好,并略微影响了GPQA的性能。尽管输出预测在符号推理任务(例如BBH)上显示出更大的优势。 CruxeVal -I和-o分别偏向输入和输出预测。
拒绝采样
他们还探索了使用拒绝抽样来过滤不正确响应的方法,从而导致50%的培训数据被删除。但是,这会导致一般的绩效下降,表明数据多样性可能会丢失。
作者还尝试通过执行代码来替换所有不正确的答案(不包括思考链)。
这种方法确实带来了旨在衡量输出预测准确性的基准的改进,例如LeetCode-O和CruxeVal-O,但以其他方式降低了分数,从而导致平均性能的退化。
当将这两种方法与大约50%的Codei/O的培训进行比较时,样本量可比时,它们仍然没有任何优势。
因此,为了维持绩效平衡,研究人员在没有任何修改的情况下保留了所有不正确的响应。
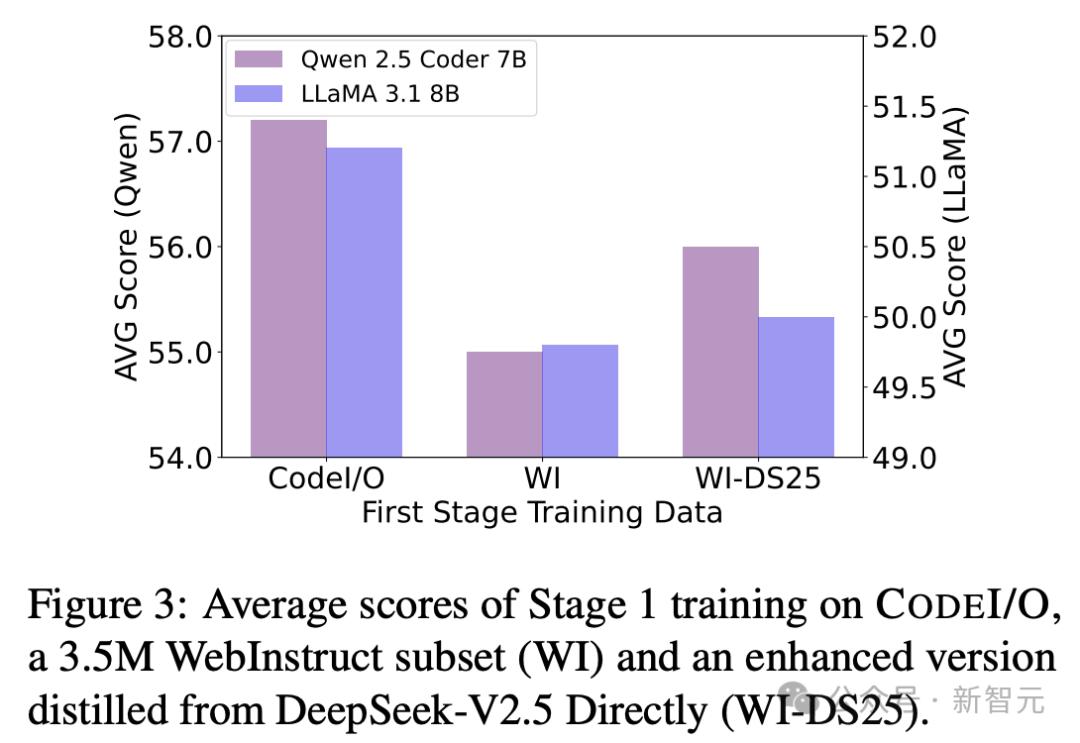
不同合成模型的影响
为了研究不同综合模型的效果,作者使用DeepSeek-V2.5再生对350万个Webintruct数据集的响应,并创建一个称为WebinStruct-DS25的更新数据集。
如图3所示,尽管Webinstruct-DS25的性能要比QWEN 2.5 2.5编码器7b和Llama 3.1 8B上的原始数据集更好,但它仍然没有Codei/o。
这突出了代码中各种推理模式的价值以及任务选择在培训中的重要性。
总体而言,该比较表明,预测代码的输入和输出可以提高推理功能,而不仅仅是从高级模型中蒸馏出知识。
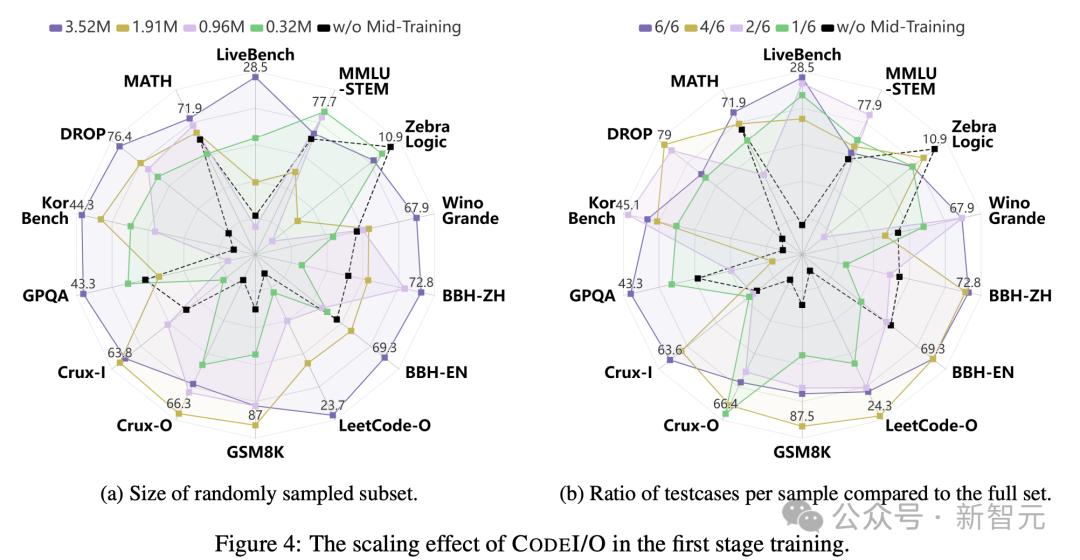
Codei/O的缩放效果
研究人员还评估了不同培训数据量的Codei/O的性能。
通过随机抽样训练示例,图4A揭示了一个明显的趋势:增加训练样本的数量通常会导致每个基准测试的性能提高。
具体而言,在大多数基准测试中,使用最小数据的性能相对较弱,因为该模型缺乏足够的训练来有效地概括。
相比之下,在完整的数据集中接受培训时,Codei/O实现了最全面,最强大的性能。
由中等数据产生的结果在这两个极端之间存在,随着训练样本的增加而逐渐改善。这突出了Codei/O在提高推理功能方面的可扩展性和有效性。
此外,他们通过固定和使用所有唯一的原始代码示例来在输入输出对维度上缩放数据,但会更改每个样本的输入输出预测实例的数量。
图4b显示了相对于完整集的I/O对的比率。
尽管缩放效应并不像训练样本那样明显,但仍可以观察到显着的好处,尤其是从1/6增加到6/6时。
这表明某些推理模型需要多个测试用例才能完全捕获和学习其复杂的逻辑流。
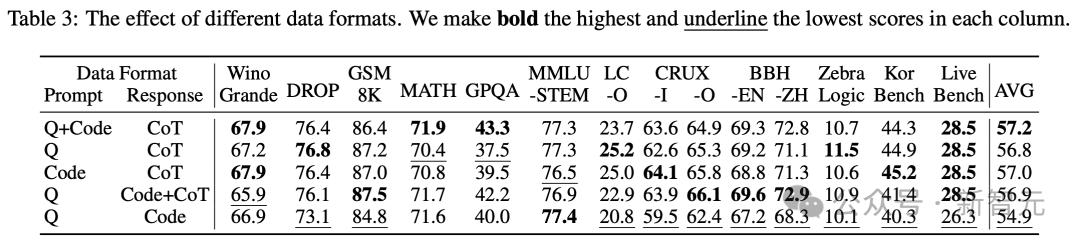
不同的数据格式
本节主要研究如何在培训样本中最好地安排查询,参考代码和思维链(COTS)。
如表3所示,将查询和参考代码放在提示中,并且在响应中的思维链可以达到每个基准中最高的平均得分和最平衡的性能。
结果以其他格式表明,在将查询放置在提示中并且将参考代码放置在响应中的情况下,最糟糕的结果出现了最糟糕的结果。
这类似于标准代码生成任务,但培训样本更少。
这突出了思维链和测试用例对学习可转移推理能力的重要性。
多次迭代
根据Codei/O(无修订)和Codei/O ++(单轮修订),研究人员将修订扩展到了第二轮,通过对第一轮修订后仍然不正确的实例进行预测来评估进一步的改进。
在下面的图7中,可视化每轮响应类型的分布。
结果表明,最初的响应是在第一轮中预测的,大约有10%的错误响应在第一轮修订中纠正了。
但是,第二轮产生了校正的显着降低,并通过检查案例作者发现该模型通常在不添加新有用信息的情况下重复相同的错误COT。
在整合了多次修订之后,他们观察到图5的持续改进,从第0轮到第1轮,但是从第1轮到第2轮的收益很小 - 对Llama 3.1 8b的略有改进,但QWEN 2.5编码器7B看到了性能下降。 。
因此,在主要实验中,研究人员呆在一轮修订中,即Codei/O ++。

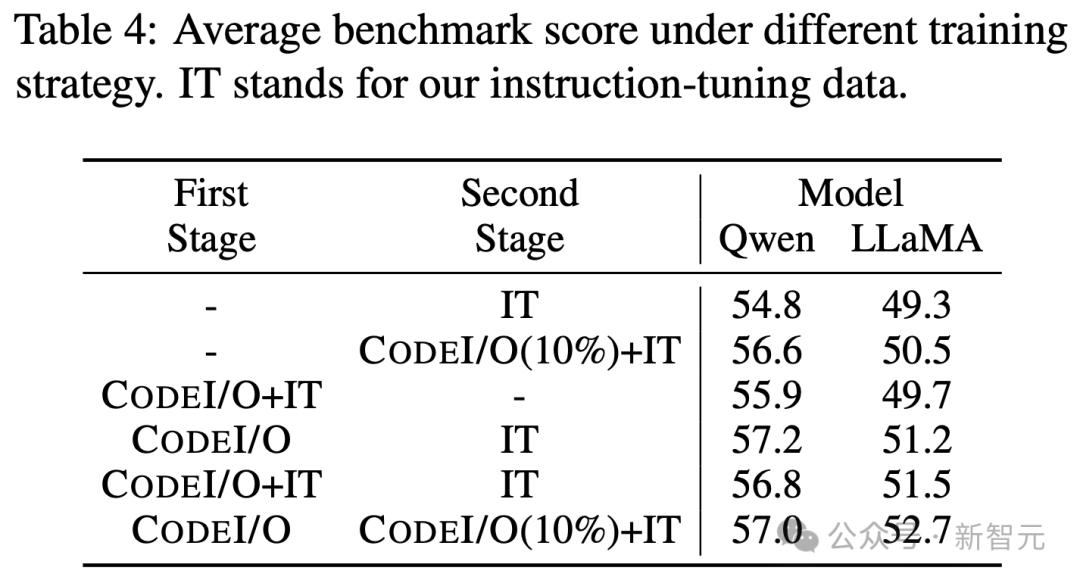
需要进行两阶段训练
最后,研究人员强调了使用Codei/O数据通过测试单阶段混合训练和两阶段训练的两阶段培训的需要,并具有不同的数据组合。
如表4所示,所有两个阶段的变体的表现都比单阶段训练更好。
同时,在不同模型之间,在两个阶段训练期间混合数据的效果各不相同。
对于QWEN 2.5编码器7B,最好的结果是完全分开Codei/O和指令微调数据,而Llama 3.1 8b在第一阶段和第二阶段的混合数据中都可以表现更好。
04论文的作者
Junlong Li

Junlong Li是一名三年级的硕士学生,他是计算机科学专业的学生,并在Hai Zhao教授的领导下学习。
此前,他在2022年获得了IEEE飞行员课程的计算机科学学士学位。
他曾在亚洲微软研究所(MSRA)的NLC小组担任研究实习生,在Lei Cui博士的指导下,他参与了与文档AI相关的几个研究主题,包括网页理解和文档图像。基本模型。
从2023年5月到2024年2月,他与Gair的Pengfei Liu教授紧密合作,专注于LLMS评估和对齐等问题。
目前,他在Junxian He教授的指导下从事相关研究。
Daya Guo

Daya Guo在Sun Yat-Sen University和Microsoft Asia研究所的联合培训下攻读博士学位,并由Jian Yin教授和Ming Zhou博士共同执导。目前在DeepSeek担任研究员。
从2014年到2018年,他获得了Sun Yat-Sen University的计算机科学学士学位。从2017年到2023年,他曾在Microsoft Research Asia担任研究实习生。
他的研究重点是自然语言处理和代码智能,旨在使计算机能够智能地处理,理解和生成自然语言和编程语言。长期的研究目标是促进AGI的发展,从而彻底改变了计算机与人类互动的方式,并增强了他们处理复杂任务的能力。
目前,他的研究指示包括:(1)大语言模型; (2)代码智能。
runxin xu

Runxin Xu是DeepSeek的研究科学家。他深入参与了DeepSeek系列模型的开发,包括DeepSeek-R1,DeepSeek V1/V2/V3,DeepSeek Math,DeepSeek Codor,DeepSeek Moe等。
此前,他获得了北京大学信息科学技术学院的硕士学位,该学院由Baobao Chang博士和Zhifang Sui博士执导,并在上海Jiaotong University完成了本科学习。
他的研究兴趣主要集中在AGI上,并致力于通过可扩展有效的方法不断地推进AI智能的界限。
Yu Wu(Wu Mata)

Yu Wu目前是一名DeepSeek技术人员,负责领导LLM Alignment团队。
他深入参与了DeepSeek系列模型的开发,包括DeepSeek V1,V2,V3,R1,DeepSeek编码器和DeepSeek Math。
在此之前,他曾担任微软研究所(MSRA)自然语言计算集团的高级研究员。
他获得了北京航空和宇航学大学的学士学位和博士学位,并在Ming Zhou和Zhoujun Li教授的领导下学习。
他在研究生涯中取得了许多成就,包括在ACL,EMNLP,Neurips,AAAI,IJCAI和ICML等高级会议和期刊上发表80多篇论文。
他还发布了几种有影响力的开源模型,包括Wavlm,Vall-E,DeepSeek编码器,DeepSeek V3和DeepSeek R1。
Junxian He(Ho Junxian)

Junxian他目前是香港科学技术大学计算机科学与工程系的助理教授(任期教师)。
他于2022年获得了卡内基·梅隆大学语言技术学院的博士学位,由Graham Neubig和Taylor Berg-Kirkpatrick共同执导。他还于2017年获得上海北大大学的电子工程学士学位。
此前,Junxian还曾在Facebook AI研究所(2019)和Salesforce Research Institute(2020)工作了一段时间。
参考:
本文来自作者:Xin Zhiyuan的微信公共帐户“ Xin Zhiyuan”,由36KR发表并授权。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/274315.html
