
最近,Openai发表了一篇论文,声称O3模型在2024年IOI达到了黄金水平,并在CodeForces上获得了与精英人类的可比分数。
他们是怎么做到的? Openai在本文开头的一句话中总结了它:“将强化学习应用于大型语言模型(LLMS)可以显着提高复杂的编程和推理任务的性能。”

在过去的两天中,本文引起了广泛的讨论,尤其是博客作者马修·伯曼(Matthew Berman)指出的关键点:这种策略不仅适合编程,而且还是AGI及以后的最清晰的途径。

换句话说,本文不仅显示了AI编程中的新成就,而且还为创建世界上最好的AI程序员甚至AGI提供了蓝图。正如Openai在本文中所写的那样:“这些结果表明,扩展一般的强化学习而不是依靠特定领域的技术,可以为在推理领域(例如竞争性编程)中实施SOTA AI提供强大的途径。”
此外,本文还特别提到,中国的DeepSeek-R1和Kimi K1.5通过独立研究表明,使用思维链(COT)学习方法可以显着改善该模型在数学问题解决和编程挑战中的全面性能。这也是一个“食谱”,以前尚未发表O1 - 直到几天前,它才被半覆盖和半覆盖。请参阅Machine Heart的报告“感谢DeepSeek,Chatgpt开始披露O3思维链,但这是不完整的。” (1月20日,DeepSeek和Kimi在同一天发行了推理模型R1和K1.5,这两者都表现出色。)

接下来,让我们看一下本文的核心,然后了解为什么马修·伯曼(Matthew Berman)说,扩展一般强化学习是“通往AGI及以后的最清晰的途径”。
OpenAI从三种型号开始,即O1,O1-IOI和O3。
Openai O1:
竞争性编程任务的绩效改进
O1是一种通过强化学习训练的大型语言模型,旨在解决复杂的推理任务。
在回答问题之前,O1将形成一个内部思维链,并使用强化学习来改善思维链过程,帮助模型识别和纠正错误,将复杂的任务分解为可管理的部分,并探索方法何时何时通过替代解决方案路径。这些上下文推理能力可显着提高O1在各种任务上的总体表现。
Kimi研究人员Flood Sung还谈到了推断模型Kimi K1.5的研发过程,并发现了类似的发现。他指出:“长时间思维链的有效性已在基米内部进行了验证。使用非常小的型号,训练模型来执行数十个。操作的加法,减法,乘法和划分,综合了细粒度的计算过程进入很长的COT数据和SFT,您可以获得很好的结果。
此外,O1还可以调用外部工具来验证代码。
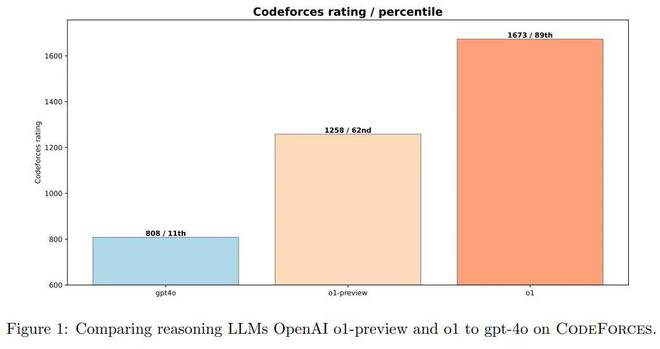
在CodeForces基准测试上的不同模型的性能。
OpenAI将O1与非推理大语言模型(GPT-4O)和较早的推理模型(O1-preview)进行比较。
图1表明,O1-preiview和O1都比GPT-4O好得多,GPT-4O强调了在复杂的推理任务中增强学习的有效性。
O1-preview模型在CodeForces上得分为1258分,与GPT-4O的808点相比,这是一个重大改进。进一步的训练将O1得分提高到1673年,为AI在竞争性编程中的表现树立了新的里程碑。
Openai O1-ioi:
增加的增强学习和测试可以导致重大改进
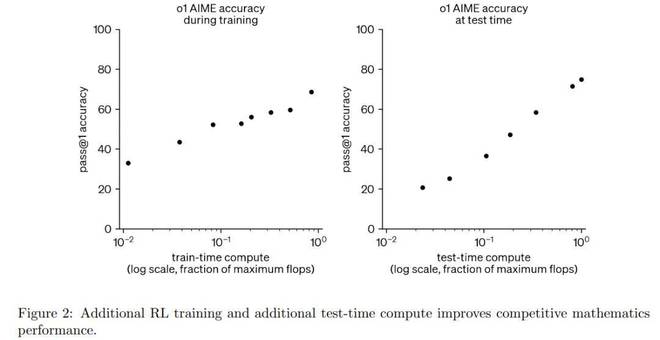
在开发和评估OpenAI O1的过程中,他们发现在测试过程中增加RL计算和推理计算的量可以不断提高模型性能。
如图2所示,当扩展RL训练和扩展测试时,推理可以显着提高模型性能。基于这些见解,OpenAI创建了O1-IOI系统。
他们从以下方面实现了这一目标。
第一步是扩大OpenAI O1的强化学习阶段,重点是编码任务。细节如下:
在高水平上,OpenAI将每个IOI问题分解为子任务中的每个子任务中的每个子任务中的10,000个解决方案,然后使用群集和重新排列的方法从这些解决方案中决定要提交什么。
图3显示,O1-IOI的CodeForces得分达到1807年,其中93%以上的竞争对手 - 证明了可以实现对编码任务的其他RL培训的重大改进。
这些结果证实,域特异性的RL微调与高级选择启发式方法相结合可以显着改善编程结果。
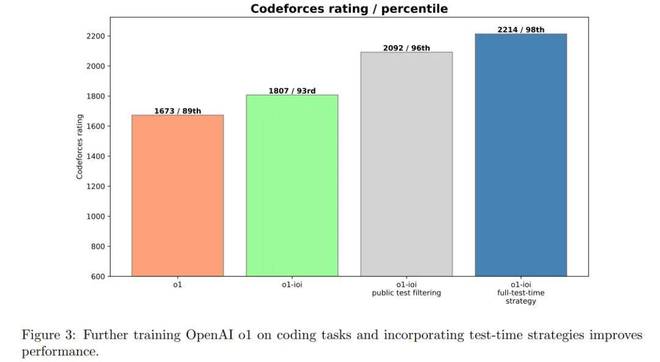
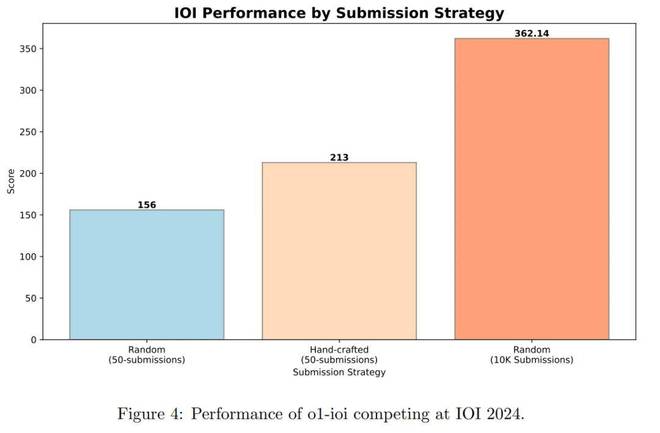
图4显示了IOI竞争结果。在竞争期间,该系统为每个问题生成了10,000个候选解决方案,并使用测试时间选择策略过滤了50项提交。最后,该模型得分213分,排名前49%。
Openai O3:
没有人类的出色的强化学习
基于从O1和O1-IOI获得的见解,OpenAI还探讨了基于强化学习(RL)而不是人为设计的测试时间策略的结果。
即使是Openai试图探索进一步的RL培训,该模型是否可以独立开发和执行自己的测试时间推理策略。
为此,OpenAI使用O3的早期检查点来评估其在竞争性编程任务上的性能。
如图5所示,进一步的增强学习(RL)训练可显着提高O1和完整的O1-IOI系统的性能。 O3可以解决更广泛的复杂算法问题,并具有更高的可靠性,从而使其能力更接近CodeForces的顶级人类程序员。
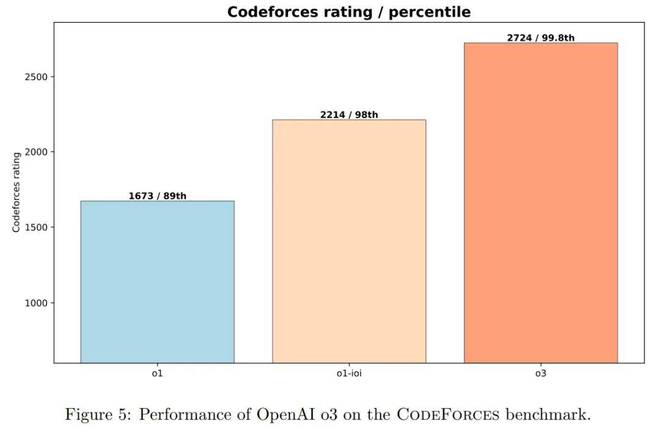
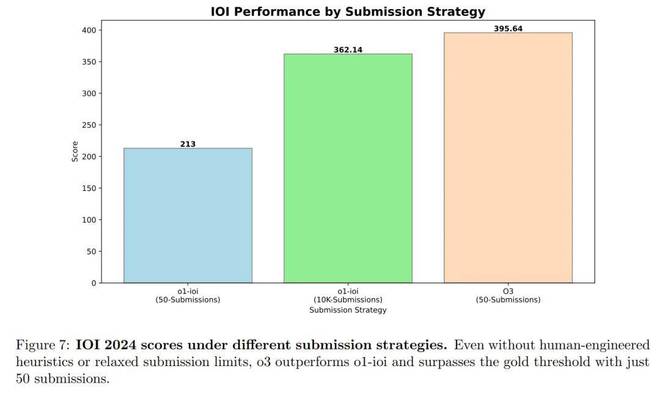
图7显示了IOI 2024上模型的最终分数。2024竞赛的总分限制为600分,金牌得分线约为360分。
这是关键结果:
O1-IOI在50项提交的限制下得分213点,而在10,000次提交的限制下增加到362.14点,略高于黄金分数。
O3在50次提交的限制下得分395.64分,超过了黄金分数。
这些结果表明,O3在不依赖于IOI设计的测试时间策略的情况下优于O1-III。相反,O3技术(例如生成蛮力解决方案以验证输出)足以替换O1-IOI所需的手动设计的聚类和选择过程。
总体而言,IOI 2024的结果证实,仅通过大规模的强化学习培训就可以实现最先进的编程和推理性能。通过独立的学习来生成,评估和优化解决方案,O3不依赖于域特异性的启发式方法或基于群集的方法,就超越了O1-IOI。
此外,如图5所示,在Codeforces上,O3的得分达到了2724分,并且进入了世界上的前200名。
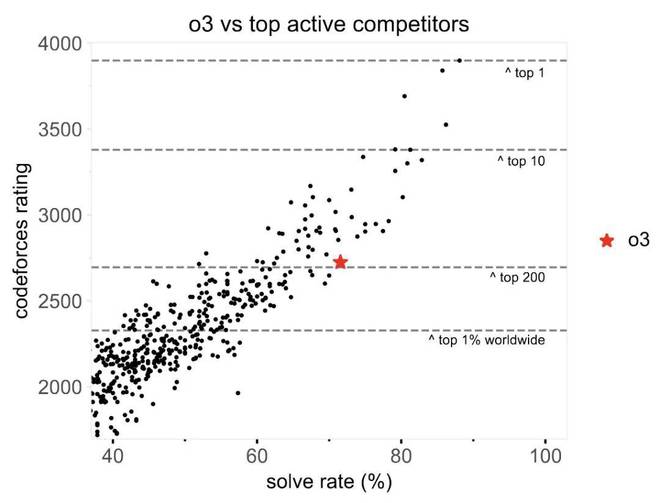
本文的作者之一艾哈迈德·埃尔·奇什基(Ahmed El-Kishky)在其中分享了一个有趣的发现。他说,他们发现在检查思维链时,该模型独立开发了自己的测试时间策略:该模型首先编写了一个简单的蛮力解决方案,然后用它来验证一种更复杂的优化方法。

软件工程评估
Openai还对模型进行了软件工程评估。他们在两个数据集上测试了该模型:hackerrank astra数据集和已验证的SWE基础。
图8显示了模型的思维链推理的效果:与GPT-4O相比,PASS@1平均1和6.03点的O1-preview模型提高了9.98%。
通过增强学习进一步进行微调后,O1的性能得到了提高,其通过@1达到63.92%,平均得分为75.80% - 与O1-Preview相比,PASS@1提高了3.03%。
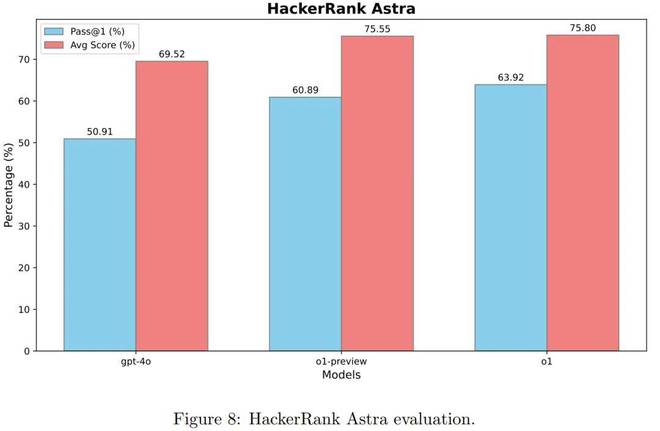
图9显示,与SWE Bench上的GPT-4O相比,O1预览版的提高了8.1%,突出了模型推理能力的显着改善。
O1在培训期间应用其他强化学习计算,进一步提高了8.6%的绩效。
值得注意的是,与O1相比,O3使用的计算资源要多得多,在O1上取得了显着提高22.8%。
一般强化是否学习实施AGI的最清晰途径?
基于本文,马修·伯曼(Matthew Berman)通过一系列推文证明了一个论点:一般强化学习是实现AGI的最清晰途径。让我们看一下他的论点。
首先,在本文中,OpenAI研究表明,“强化学习 +测试计算”是构建超级智能AI的关键。 OpenAI首席执行官Sam Altman还表示,OpenAI的模型已从175升至50次竞争编程任务,预计到今年年底将达到第一名。

@TSarnick的视频
视频链接:
同时,上文还指出,该模型最初依赖于人类设计的推理策略,但是在此阶段,最大的进步并没有发生,而是在完全将人类从过程中完全消除后。
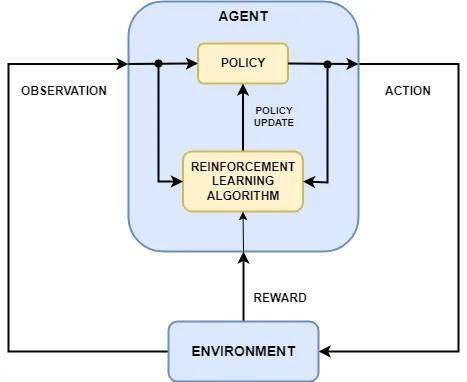
伯曼还带来了DeepSeek-R1的巨大成就。

他指出,DeepSeek -R1的突破来自“具有可验证的奖励的增强学习”,这实际上是Alphago使用的方法 - 允许该模型在试验和错误中学习,然后无限地扩展智能。
没有人类的指导,Alphago已成为世界上最强大的GO球员。它的方法是继续与自己玩耍,直到掌握游戏为止。

Kimi研究人员Flood Sung还谈到了这一点,指出:“无论模型中有什么错误,只要不重复进行,并且最终,如果正确完成模型,它将被视为一个很好的探索否则,值得惩罚。在强化培训过程中,这与DeepSeek的发现非常相似,也为启动K1.5视觉思维模型奠定了基础。”
现在,OpenAI在编程领域也使用了类似的策略,将来可以在更多领域中使用。
这是什么意思?伯曼认为,这意味着每个具有可验证奖励的领域(包括数学,编程,科学)可以通过自我游戏方法来掌握。
洪水唱歌也表达了类似的期望:“ O3在领先,还有很多路要走。给AI一个可衡量的目标,让它自行探索它。例如,让AI撰写100,000多个公共帐户文章,例如当AI发布一个复制Tiktok的应用程序,让我们期待下一个进度!”
到那时,人工智能将不再受到人类层面的限制。这可能是Agi出生的时候。
实际上,特斯拉已经在完全自主的驾驶任务上验证了这一点。过去,他们的方法是依靠“人类规则 + AI”的混合模型。但是,在他们转到端到端的AI方法之后,他们的性能取得了重大改进。伯曼说:“人工智能只需要更多的计算,而不是更多的人类干预。”
视频链接:
正如山姆·奥特曼(Sam Altman)之前所说,AGI是规模扩展的问题。
实际上,许多研究人员已经在编程和数学等领域之外使用了强化学习。

当然,并不是每个人都同意Berman和Altman。例如,有人指出竞争性编程和实际编程之间的区别 - 实际编程通常涉及更多问题,包括可扩展性,安全性,弹性和投资回报率。 。

有些人也驳斥了:
你读过本文吗?您如何看待“通过可验证的奖励加强学习”的未来潜力?您认为这可以实施AGI吗?
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/274346.html
