
OpenAI Muon优化算法再突破:算力需求直降48%,月之暗面团队推进Muon Scaling Law,适用于1.5B Llama模型
算力需求比 AdamW 降低了 48%,OpenAI 的技术人员提出了训练优化算法 Muon,而月之暗面团队对其又进行了进一步的推进。
团队发现了 Muon 方法的 Scaling Law 这一情况,接着对其进行了改进,并且证明了 Muon 对于更大的模型也是同样适用的。
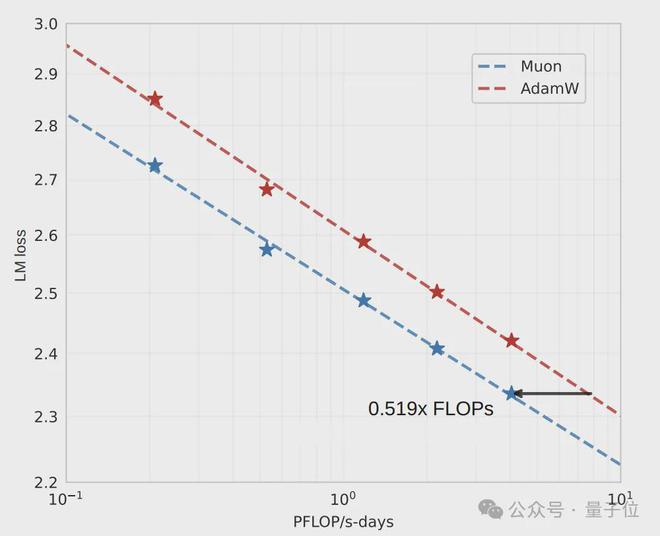
不同的 Llama 架构模型参数量最高可达 1.5B。在这些模型上,改进后的 Muon 的算力需求只是 AdamW 的 52%。
团队训练出了一个 16B 的 MoE 模型,这个模型是基于 DeepSeek 架构的,并且与改进后的优化算法一同被开源了。
Muon 技术博客发布时主要针对较小的模型和数据集。作者留下了三个尚未解决的问题:
消息传出后,当时 Muon 的那些作者都很激动。其中主要作者 Keller Jordan 称这是 Muon 规模化的首个成功报告,并向团队送上了祝贺。
另一名贡献者,当时在负责 Muon 规模化实验的 Hyperbolic Labs 担任联创兼 CTO 的 Yuchen Jin 也表明,月暗团队的这项成果,属于 Muon 的一次胜利。

将AdamW特点引入Muon
在介绍月暗团队的工作之前,得先知晓 Muon 是怎样的一种技术。
这是一种用于神经网络隐藏层的参数优化器,其类型为 2D 。主要的作者是 Keller Jordan,他来自 OpenAI 的深度学习团队。
这项成果是在去年 12 月 8 日发表的。Keller 是在去年 12 月加入 OpenAI 的。
Muon 的核心思想在于通过进行正交化梯度来更新矩阵。这样做的目的是避免参数更新陷入局部极小值的情况。通过这种方式,模型能够学习到更为多样化的特征表示。
Muon 在 94%的精度下,把 CIFAR - 10 在 A100 上的训练时间从 3.3 秒缩短到了 2.6 秒。

当时 Muon 团队仅证明了其在小型模型以及数据集中的可行性。然而,对于较大的模型是否能够适用,这是一个未知的情况。
现在经过月暗团队的改进,Muon被证明在面对更大的模型和数据集时也能够适用。 现在月暗团队对 Muon 进行了改进,其结果是 Muon 对于更大的模型和数据集同样适用。 经月暗团队改进后,Muon 被证实对于更大的模型和数据集是同样适用的。 月暗团队改进之后,Muon 被证明对更大的模型和数据集也适用。 现在由于月暗团队的改进,Muon 被证明对于更大的模型和数据集同样具备适用性。
团队针对模型本身,吸收了 AdamW 里的一些特点,并将其移植到了 Muon 当中,这具体包含两个方面。
一是将权重衰减机制引入进来,在权重的更新公式里添加了一项,该项带有衰减系数。
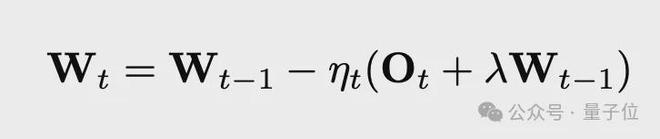
作者发现直接将 Muon 应用到大规模训练时,会出现模型权重和层输出的幅度持续增长的情况,这种情况最终会超出 bf16 的高精度表示范围,从而损害模型性能,这就是这样做的原因。
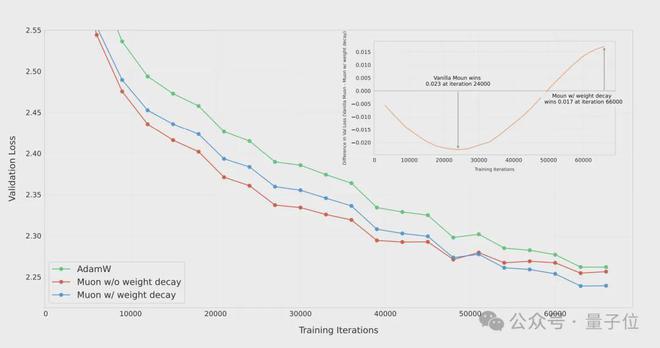
在训练一个 8 亿参数模型达到 100B tokens 时(这个规模约是计算预算的 5 倍最优状态),团队把 AdamW 与无权重衰减的 Muon 以及带权重衰减的 Muon 进行了对比。
结果表明,在过拟合阶段,带权重衰减的 Muon 取得了最好的效果,这验证了权重衰减是有必要的。
第二项改进在于对 Muon 的参数更新尺度进行了调整。这样做使得不同形状矩阵的参数更新幅度能够保持一致,并且与 AdamW 的更新幅度相匹配。
Muon 的一个特点在于,对于矩阵参数形状为[A,B]时,它的理论更新幅度是 sqrt(1/max(A,B))。
这使得不同形状矩阵参数的更新幅度存在很大差异。例如,对于像 MLP 这样的宽矩阵,其更新幅度会过小;而当把每个 head 看作独立矩阵时,更新幅度又会过大。
这个幅度与 AdamW 不一致,这给超参数的设置带来了困难。
作者为了使不同矩阵参数的更新幅度相匹配且与 AdamW 保持一致,尝试了若干改进方案,最终决定直接依据形状来对每个参数的学习率进行调整。
其中一个常数是 0.2,这个常数是通过实验确定的,它用于使 Muon 的更新尺度与 AdamW 相契合。

要将 Muon 用于更大规模的训练,除了对 Muon 本身进行改进之外,还需要把它扩展到分布式训练环境中。
Muon 需要完整的梯度矩阵来计算正交化的更新量。现有的分布式训练框架,像 ZeRO-1、Megatron-LM 等,都假设优化器状态可以独立地按元素切分到不同设备上。因此,这些分布式训练框架无法直接支持 Muon。
论文作者为了解决这个问题,提出了分布式 Muon 的并行化策略。
它在ZeRO-1的基础上引入了两个额外的操作:
这种实现方式能够在最小化内存占用的同时,也能最小化通信开销,并且还能最大限度地保留原始 Muon 算法的数学性质。

证明Muon扩展可行性
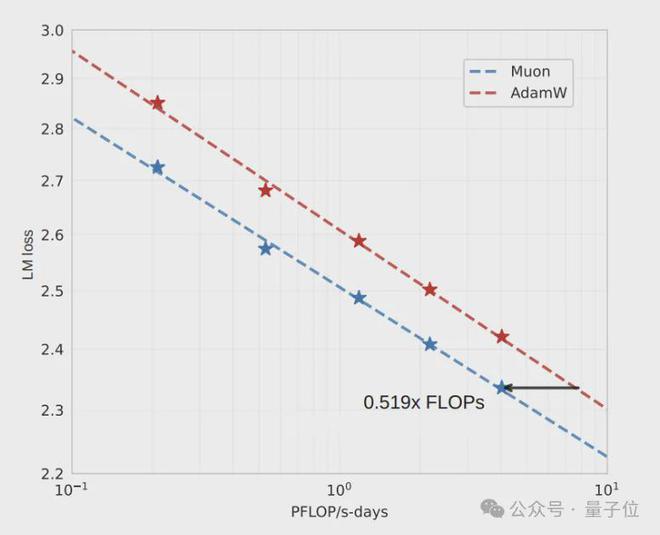
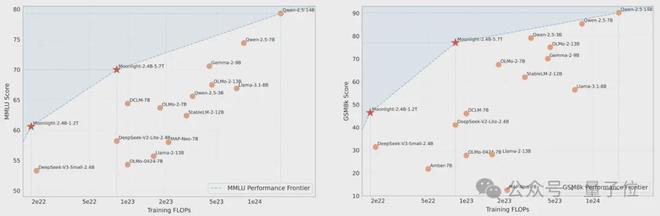
作者基于上述的 Muon 进行了改进,并且取得了一些成果。作者在 Llama 架构的一系列稠密模型上,分别进行了 Muon 的实验以及 AdamW 的实验,然后对这两者进行了模型缩放对比。
结果表明,在计算预算最优时,Muon 的样本效率比 AdamW 高。Muon 的样本效率是 AdamW 的 1.92 倍。也就是说,训练达到相当性能时,所需的 FLOPS 只需 AdamW 的 52%。
这一发现证实了Muon在大规模训练中的效率优势
作者以 DeepSeek-V3-Small 架构为基础,接着用改进的 Muon 对 Moonlight 模型进行了训练。
Moonlight 是一个 MoE 模型。它有 15.29B 的总参数。同时它还有 2.24B 激活参数。并且它的训练 token 量为 5.7T。
Moonlight 在各类任务上取得了明显更好的性能。这些任务包括英语理解与推理方面的 MMLU、TriviaQA、BBH,代码生成方面的 HumanEval、MBPP,数学推理方面的 GSM8K、MATH、CMATH,以及中文理解方面的 C-Eval、CMMLU。并且与相同规模和数据量的模型相比,Moonlight 在这些任务上都有出色表现。
Moonlight 展现出了极强的竞争力,即便与那些使用更大数据集来进行训练的稠密模型相比也是如此。
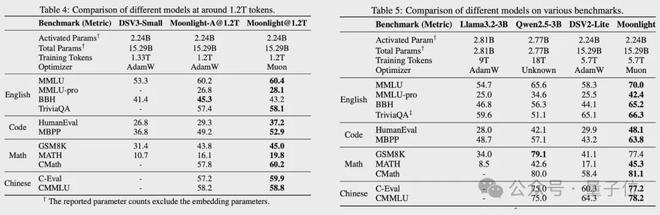
对比多个知名语言模型后可以发现,Moonlight 在性能 - 训练预算平面上推动了帕累托前沿。
帕累托前沿是经济学和管理学中的一个概念。它描述的是在多目标决策问题中,所有可能的最优解的集合。这些解在多个目标之间取得了最佳平衡。在帕累托前沿上的每一个点,都意味着一个目标的改善必然会以牺牲另一个目标为代价。所以,它代表了在多个目标之间实现的最佳权衡。
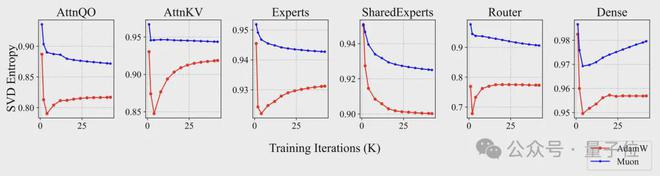
作者为了进一步分析 Muon 更新矩阵参数的内在机制,将 Muon 和 AdamW 训练得到的模型在不同训练阶段的参数矩阵奇异值谱进行了对比。
发现 Muon 优化的矩阵在各层的各类参数方面,始终比 AdamW 具有更高的奇异值熵。这从经验层面验证了 Muon 通过正交化来学习更加多样化表示的这种直觉。
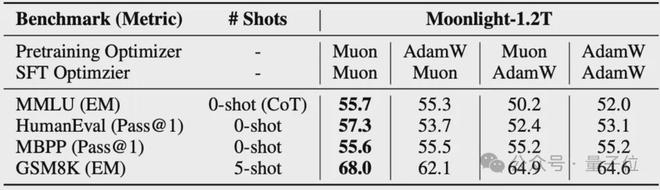
作者首先在 Moonlight 模型的基础上进行了探索。接着探索了 Muon 在指导微调阶段的效果。结果显示,在预训练阶段使用 Muon 以及在微调阶段也使用 Muon 的效果是最好的。
技术报告:
Code:
Moonlight模型:
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/274449.html
