
大模型又卷起来了。
3 月 28 日,阿里发布了其大模型的重磅升级,即能看图、读视频且会解数学题的视觉推理模型 QVQ-Max;字节也发布了各自大模型的重磅升级,其中豆包开启测试,能边想边搜的新版“深度思考”。
图/ Qwen
同一天,两大国产大模型都开启了新一轮大模型更新。这或许并非是一种巧合。本周,各家主流大模型都进行了一轮更新的发布。
DeepSeek 发布了 V3-0324 这个新版本,其推理、写作、编码能力得到了提升;Google 推出了 Gemini-2.5-Pro,在各个方面的能力都有提升,并且在 LMArena 榜单上取得了 40 分的绝对领先优势;OpenAI 升级了 GPT-4o 的图像生成功能,使其可控性和质量有了大幅进化。
各家基础模型又卷了起来。
图像生成以及视觉推理方面,多模态还有超长上下文方面,这一轮的更新如同一场全方位能力升级的排位赛。它不仅在卷功能和质量,还在卷“智能体时代”中谁能够提供更优良的基础模型。
五大模型集体上新,到底在卷什么?
1、阿里 QVQ-Max:视觉推理能力全开。
图/ 阿里
阿里的视觉推理模型,其野心和意图十分明显。去年 12 月,阿里 Qwen 团队推出了 QVQ-72B-Preview 视觉推理模型。今年 1 月,为雷鸟创新打造了用于雷鸟 V3 AI 眼镜的定制模型。
QVQ-Max 进行了一次全面的升级。它不但能够“看懂”图表和照片,还能够对视频内容进行理解。并且能够结合这些信息进行分析和推理,从而给出解决方案。例如,它可以“看”出一组几何图形之间的角度关系,也能够预测视频中下一秒可能发生的行为,在多模态基准测试中表现良好。
简单来说,QVQ-Max 解析图片的能力很强。它能快速识别出复杂图表和日常生活随手拍照片中的关键元素。同时,它还能进一步分析这些信息,并结合背景知识得出结论。

图/ Qwen
另外值得一提,QVQ-Max 目前已上线 Qwen Chat。我简单上手体验了一下,发现它对于照片的分析明显强于 Qwen2.5-Max,甚至能够根据“左上角 logo 是中国银行”的提醒在照片中找到对应的内容。
2、豆包新版「深度思考」,主打一个推理进阶。
几乎在同一时刻,字节的豆包进行了测试并上线了新版的“深度思考”能力。这种能力能够在思维链条展开的过程中,动态地发起搜索,从而实现“边想边搜”。在实际的体验里,豆包会在思考的过程中去搜索资料,并且不断通过搜索来补充信息,然后再进行思考。
简单来说,用户提问若涉及时间、地点方面的内容,或者上下文有变化,亦或是需要整合跨知识链的信息,那么豆包就不会“一次性搜一堆”了,而是会在推理过程中多次触发搜索节点,持续修正并丰富自身的思维路径。

了解 QVQ-Max 的思考过程,图/豆包
我尝试让豆包深入了解 QVQ-Max 模型,它进行了两次搜索。第一次搜索找到 16 篇参考资料,由于部分信息缺失,又进行了第二次搜索,第二次搜索找到 8 篇参考资料。
与 DeepSeek-R1 以及 GPT 系列之前的工具调度能力相比较而言,豆包这次的升级虽然不是具有开创性的,但却明显地弥补了之前在面对复杂问题求解时所存在的不足。
3、DeepSeek-V3 小版本升级,每一点都强了点。

图/ DeepSeek
DeepSeek-V3 于 0324 发布了最新的小版本升级。此次升级依旧延续了“小体积+大能力”的路线。主要是借鉴了 DeepSeek-R1 在模型训练中使用的强化学习技术。并且针对推理、写作、编程能力进行了进一步的优化。
新版模型在前端开发能力方面,能够生成带有更现代设计感的网页结构,并且在代码生成、转换以及编辑能力上也更加稳定;在写作方面,显著提升了中文中长篇文本的逻辑性和通顺度,更适宜进行小说、剧本等内容的创作。
4、Gemini 2.5 Pro:谷歌最强通用模型来了。
Google 本周推出的 Gemini 2.5 Pro 与 DeepSeek-V3 相比,是一次真正的“大升级”。它在编码能力、数学能力、视觉推理能力以及搜索调度能力等方面都有了全面的增强。简言之,它正朝着将“大语言模型”推向“高可信度、多轮决策型智能体”的方向发展。
Gemini 2.5 Pro 是 Google 的首个「全能型智能体底座」模型,它在对话能力方面表现极为出色,能够在对话能力上技压群雄。在机制相对比较合理的大模型竞技场 ChatBot Arena 中,它坐到了第一的位置,并且与其他一众顶级大模型相比,如 Grok-3、GPT-4.5、DeepSeek-R1 等,它都大幅领先。
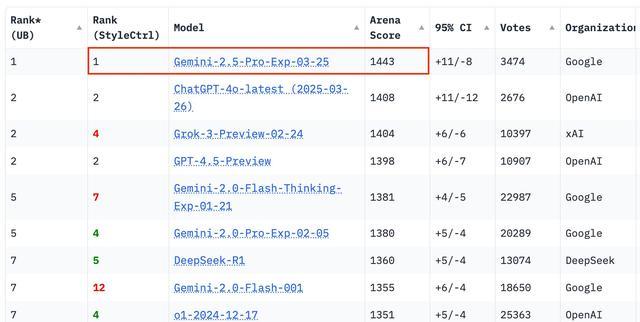
图/ Chatbot Arena
编码方面,Agentic Coding(智能体编码)的表现不如 Claude-3.7-Sonnet。然而,在 SWE-Bench Verified 编程测试中,它却遥遥领先,尤其在创建复杂 web 应用程序和代理工具链方面表现出色。图像生成领域,Gemini 2.5 Pro 取得了巨大的进展。在 GPT-4o 提升图像生成能力之前,它就已经让很多人感到惊艳。
5、GPT-4o 原生图片生成,效果震撼全球网友。
单从热度方面来看,GPT-4o(0326)的更新毫无疑问是这一轮集体升级里最大的赢家。本周,OpenAI 给 GPT-4o 推出了新一轮的升级。这次升级不仅提升了解决复杂技术以及编码问题的能力,其中最出圈的或许还是原生的图像生成功能。
上线之后,有无数网友在对新版本的图像生成功能进行尝试。其中,让 GPT-4o 用“吉卜力风格”重画这一行为,更是将我的社交媒体时间线填满了。按照 OpenAI CEO 山姆·奥尔特曼(Sam Altman)的说法,GPT-4o 进行更新之后,文生图的需求急剧增加,甚至导致了 GPU 处于超负荷状态。

GPT 4o 根据照片生成,原始照片为哔哩哔哩在AWE2025的展台
此次更新与之前相比,显著提升了对复杂指令的理解能力,同时也提升了图文混排渲染的可控性。尤其在生成图像中的文字内容方面,准确率有了大幅提升。更重要的是,新版 GPT-4o 能够在多轮对话过程中连续修改图像风格与构图元素,还可以逐步调优,视觉一致性更强,用户交互体验也提升了一个层次。
智能体时代逼近,大模型不约而同拼内功
此前几个月大模型的更新节奏稍显零散。这次集体升级几乎同步到来,它清晰地释放出一个信号,即大模型正在全方位补齐能力,并且在为智能体的爆发做准备。
过去一年,大模型行业的主旋律为“多模态”与“高性能”。然而,在这一轮更新过后能够察觉到,各大厂开始一同聚焦于以下三个方向:其一,具备更强的推理链条;其二,生成更高质量的内容;其三,拥有更接近智能体形态的系统调度能力。
推理能力极为重要。QVQ-Max 强化了视觉推理,从而开启了多模态理解的深层能力;豆包借助“边想边搜”,弥补了在处理复杂问题方面的不足;DeepSeek 和 Gemini 通过 RLHF(强化学习),强化了多轮决策和长期规划的能力。
这些动作都有一个目标,那就是让大模型不只是“答题机器”,还能够真正参与到复杂任务中以及进行流程执行。

图/ Google
与此同时,内容生成的质量普遍有了提升。在 GPT-4o 升级图像生成功能的背后,实际上是文本到图像再到排版这一全流程的可控性得到了提升;DeepSeek V3 的新版也在着重强调从代码到长文本,内容生成质量有所提高。
图像生成方面,今天的模型更强调结构正确;代码生成方面,今天的模型更强调结构正确;小说生成方面,今天的模型更强调结构正确。同时,无论是图像生成、代码生成还是小说生成,今天的模型都更强调风格统一和过程透明,简言之就是在夯实大模型的基础能力。
大模型在推理和基础能力之外,正在快速补齐智能体所需的基础能力,例如工具调用。豆包具有“动态搜索”的工具调用能力,Gemini 能在 SWE-Bench 中构建多步骤程序,这些本质上都是在为“模型能自主执行任务”做准备。
从这轮更新来看,大模型的“智能体化”正成为下一场大竞赛的起始点。同时,基础能力的全方位补齐,使得这场竞赛越来越像是一场“拼内功”的长期战役。
确信的是,ChatBot 并非大模型的终点。AI 代理或者说 AI 智能体才是大模型真正无处不在的入口。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/275186.html
