
本文提出了一种新的噪声失真算法,该算法使用来自光流的结构化噪声来替代传统的随机噪声,并成功地实现了对视频运动的强大控制。
在视频扩散一代领域,如何在不牺牲图片质量的情况下准确地操纵视频中的运动细节一直是研究人员追求的目标。
Neflix和Stony Brook University等机构的研究人员通过结构化的潜在噪声采样来创新地控制运动。
实现方法非常简单,只需预处理训练视频并产生结构化噪声即可。此过程不涉及扩散模型的设计,并且不需要更改其架构和培训过程。
研究提出了一种全新的噪声失真算法,该算法超级快,可以实时运行。它使用衍生自光流场的扭曲噪声来替换随机的正时高斯噪声,同时保持空间高斯性。
由于具有有效的算法,基本的视频扩散模型可以用扭曲的噪声以很小的成本进行微调。
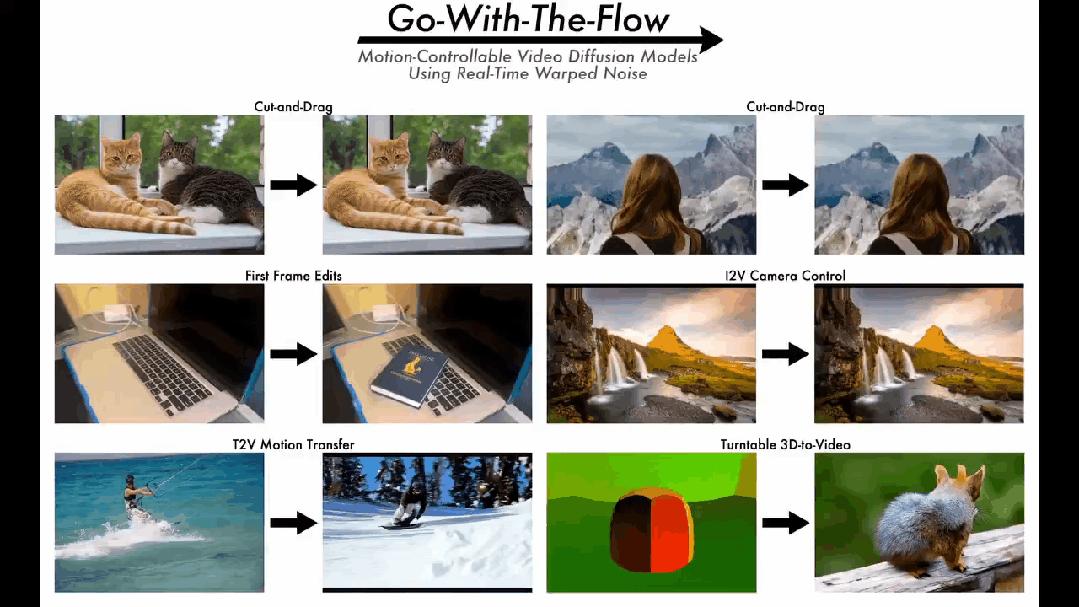
这为用户提供了全面的运动控制解决方案,该解决方案可用于诸如本地对象运动控制,全局摄像机运动控制和运动迁移等方案。
此外,该算法考虑了扭曲噪声的时间一致性和空间高斯性,这不仅可以确保图片帧的每个帧的像素质量,而且可以有效地控制运动。

纸链接:
这项研究的贡献如下:
创新的视频扩散模型解决方案:提出一种简单而新颖的方法,将运动控制转换为可以直接用于潜在空间采样的流场。它不仅可以与任何视频扩散基本模型一起使用,还可以与其他控制方法一起使用。
有效的噪声变形算法:开发了有效的噪声变形算法,它不仅可以保持空间高斯性,还可以跟踪跨帧的时间运动流动。这使得用可控运动的视频扩散模型微调视频扩散模型,并且更方便地操作是最小的。
实验和用户研究已充分验证了该方法在各种运动控制应用中的优势。
这些应用程序涵盖了本地对象运动控制,运动传递到新场景,基于参考的全局摄像机运动控制等等。
它在像素质量,可控性,时间连贯性和用户主观偏好方面表现出色。

与流相关
当前的视频扩散模型具有局限性,研究人员提出了一种创新且简单的方法,将运动控制作为结构化组件纳入视频扩散模型潜在空间的无序状态。
具体的实现方法是将潜在噪声的时间分布关联。
从二维高斯噪声膜开始,然后将其与根据按时间顺序从训练视频样本中提取的光流场计算出的扭曲噪声膜连接。下图清楚地显示了此方法的过程。
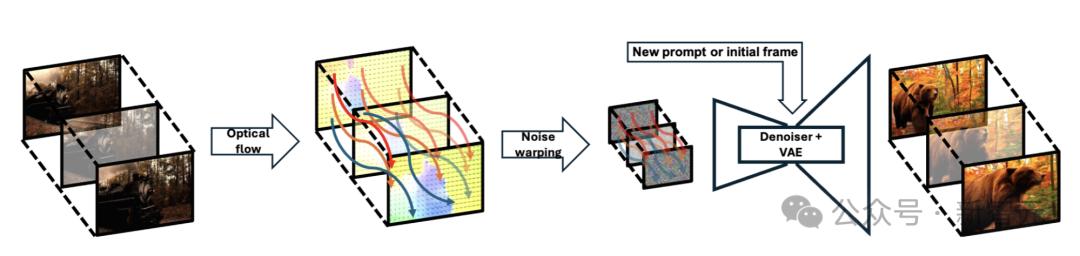
本文提出了一种创新的噪声失真算法,该算法运行非常快,可以实时运行。
传统方法从初始帧开始在每个帧上都需要一系列复杂的失真操作,而本文中的算法通过迭代连续帧之间的失真噪声来实现目标。
具体而言,研究人员可以准确跟踪像素水平上的噪声和光流密度,并根据前向和向后光流量计算图像的膨胀和收缩变化,以确定噪声的失真方法。
同时,结合Hiwyn提出的条件白噪声采样方法,它确保算法在操作过程中始终保持高斯性。

在视频扩散推理阶段,本文提出的方法具有明显的优势,并且可以根据不同的运动类型自动调整噪声变形,为各种运动控制应用提供了一站式解决方案。
本地对象运动控制:当用户想要控制本地对象的运动时,他或她只需要发出阻止信号即可灵活地更改对象轮廓范围内的噪声元素,从而使本地对象根据需要移动。
全局摄像机运动控制:为了控制全局摄像机运动,参考视频中的光流数据是多重的,输入噪声被扭曲,以便可以在不同的文本说明或初始帧条件下重新生成视频。
任意运动传输:执行任意运动传输时,运动表达方法不再限于常见的光学流,还包括光流,深度变形和3D渲染引擎产生的其他形式。
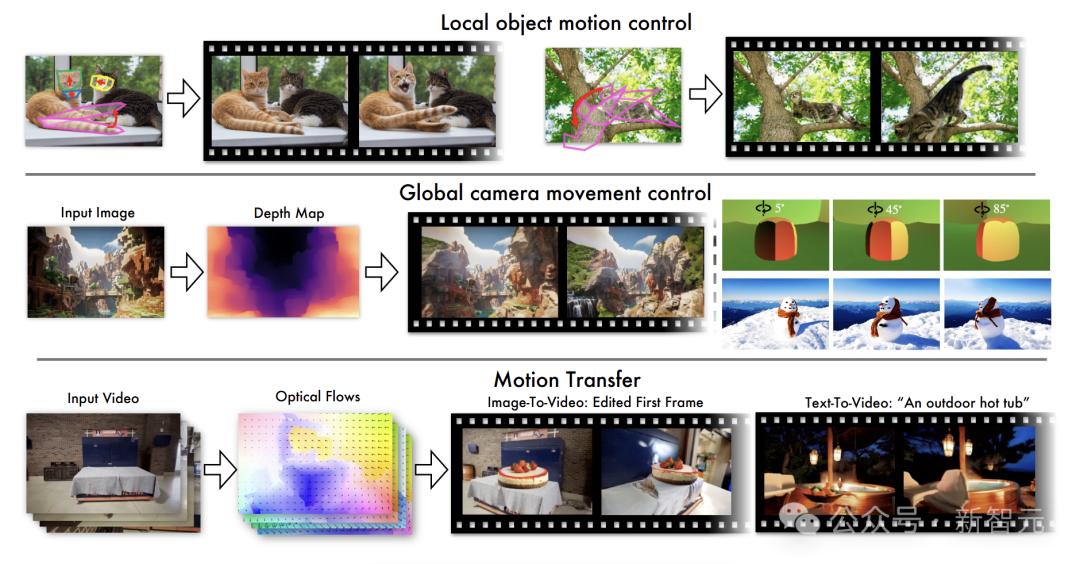
流量流主要由两个部分组成:噪声失真算法和视频扩散微调。
当运行噪声失真算法时,它不会干扰扩散模型的训练过程。研究团队使用该算法来生成噪声模式,然后使用这些模式来训练扩散模型。
这项研究中的运动控制完全基于噪声初始化,并且没有将其他参数添加到视频扩散模型中,这不仅简化了模型结构,而且还提高了工作效率。
Hiwyn提出了将噪声失真应用于图像扩散模型的想法。受此启发,研究团队发现了扭曲噪声的新用途,这是将其用作视频生成模型的运动控制条件。
研究团队使用了由大量视频和扭曲的噪声对组成的数据集来微调视频扩散模型。经过此类处理后,在推理阶段可以很好地控制视频中的运动。
噪声失真算法
为了促进大规模的噪声失真操作,研究团队开发了快速的噪声失真算法。
该算法通过框架处理噪声,只需要将噪声存储在上一个帧中(大小为H×W×C),并且每个像素的光流密度矩阵(大小为H×W)。这里的密度值可以反映特定的区域噪声压缩程度。
运行HIWYN算法时,需要耗时的多边形栅格化和每个像素的升压。
新算法直接基于帧之间图片扩展和收缩的光流跟踪直接使用像素级操作,这些操作易于实施并行处理,从而大大提高了效率。
与Hiwyn算法一样,新算法可以确保噪声的高卢斯语。
下一帧噪声失真
噪声失真算法通过迭代方法计算噪声,而特定帧的噪声计算仅取决于上一个帧的状态。
假设每个视频的大小为H×W,请使用
代表具有高度H和宽度W的二维矩阵。
上一个帧的噪声Q和流密度是已知的
,都知道正向流量F和反向流f':
,基于这些条件,算法可以计算噪声q'和下一帧的流量密度

,Q'(或p')与以前的框架的Q(或p)通过流相关。
本文中的算法结合了两种动态机制:扩展和收缩。
当视频中的区域扩大或对象向相机移动时,将触发扩展机构。在这种情况下,当前帧中的一个噪声像素将对应于下一个帧中的一个或多个噪声像素,即扩展名。
在收缩期间,研究人员将拉格朗日流体动力学和想象的噪声像素作为粒子沿前进光流f移动的想法。
这些颗粒移动后,空白区域通常会留在图片中。对于正向光流F不覆盖的区域,使用反向光流f'来拉回噪声像素,然后毛坯填充在扩展过程中计算的噪声。
此外,为了长期保持噪声分布的正确性,研究团队使用密度值记录特定区域中噪声像素的聚集数量。
在收缩的情况下,当这些噪声像素与附近的其他颗粒混合时,较高的密度颗粒将具有更大的重量。
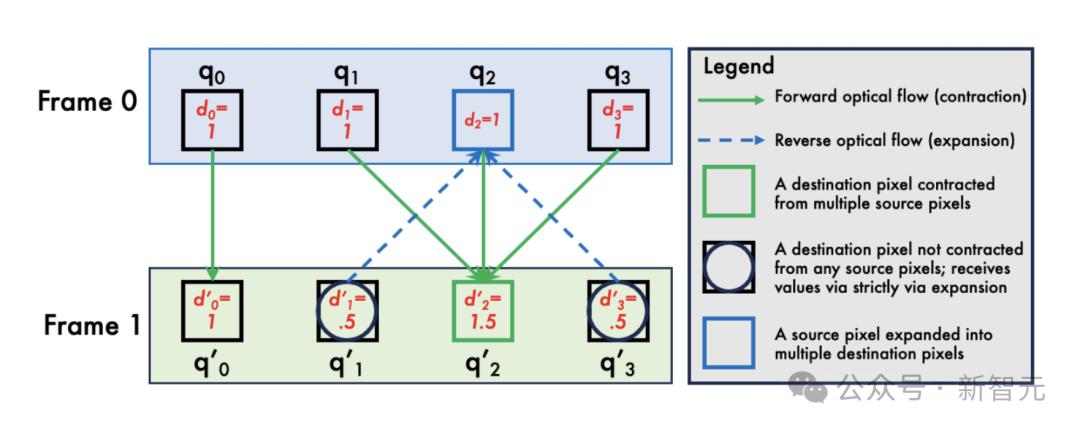
为了同时处理扩展和收缩,研究人员构建了二进制图G。图表中的边缘表明噪声和密度如何从上一个帧传递到下一个帧。
当全面考虑图中的每一侧的功能并生成下一个帧噪声Q时,根据光流密度缩放噪声,以确保可以保留原始帧的分布特性。
同时计算膨胀和收缩以避免彼此干扰可以确保最终输出结果符合完美的高斯分布。
实验结果
为了验证该计划的有效性,研究团队进行了大量实验和用户研究。结果表明,该方案在保持运动一致性和在同一情况下呈现不同的运动效果方面表现良好。
从实验数据和用户反馈中可以看出,该解决方案在像素图像质量,运动控制精度,符合文本说明,视频时间一致性和用户偏好方面具有显着优势。
Moran的I指数用于测量空间相关性,KS测试评估了正态性。选择多个参考以进行比较,包括固定的独立采样噪声,插值方法和其他噪声失真算法。
可以看出,本文提出的方法在Moran的I索引和KS测试中表现良好,表明没有空间自相关并符合正态分布。虽然双线性,双弯曲和最近的邻居插值方法无法维持高斯性,并且存在空间自相关和偏离正态分布。
本文中的方法可有效地维持空间高斯性,并且在噪声产生效率和实际应用方面具有强大的可行性。
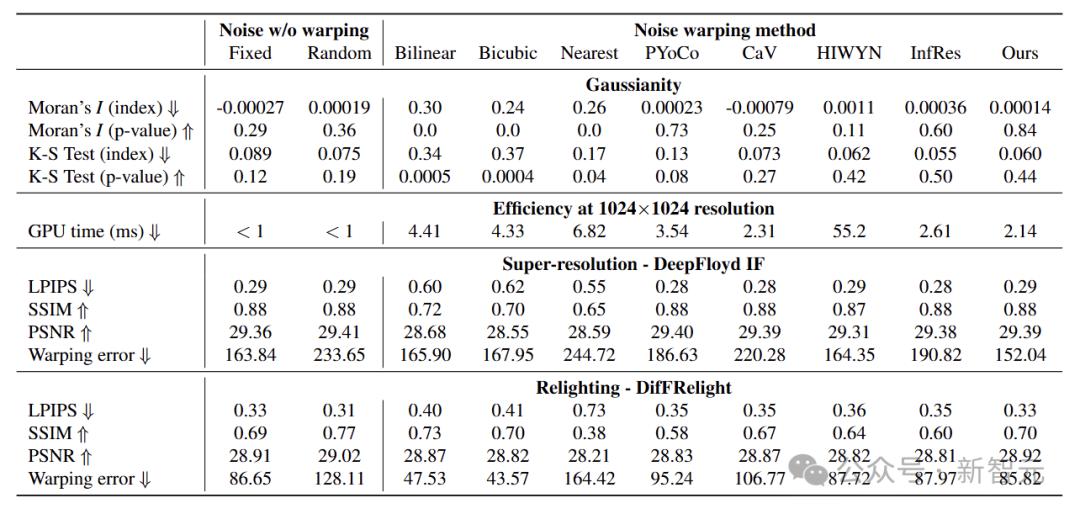
实验结果表明,本文中的方法非常有效,运行速度比平行输入更快,并且比Hiwyn快26倍,这是由于算法的线性时间复杂性。
该算法的效率比实时速度快的数量级,这表明在微调视频扩散模型时,动态应用噪声失真是可行的。
为了验证噪声失真算法的有效性,通过评估输出视频的质量和时间一致性,将不同方法扭曲的噪声输入到验证的图像扩散模型中,以进行超分辨率和肖像重新刷新。

结果表明,就时间一致性而言,本文中的算法比基线方法更好,并且在处理前景,背景和边缘时具有更好的稳定性。
评估差异视频重新任务中的噪声失真方法。推理时,研究人员将图片从特定区域删除,并根据指定的照明条件对其进行处理。本文中的方法在图像和时间指标上的性能更好,可以有效地改善图像扩散模型。


接下来,关注视频扩散中的本地对象运动控制。为了评估模型控制功能,将其与三种基线方法进行比较:SG-I2V,MotionClone和DraganyThing。
现有方法在处理复杂的本地动作时有局限性。 SG-I2V会误判运动并导致场景翻译。拖曳缺乏一致性,容易造成失真,而动态克隆很难捕获微妙的动态。
本文中的模型在处理复杂运动并保持对象保真度和三维一致性时表现出色。在本文的运动一致性,视觉保真度和整体现实主义方面,大量的研究和评估证实了该方法在本文中的显着优势。
本文中的方法还支持运动迁移和摄像机运动控制。
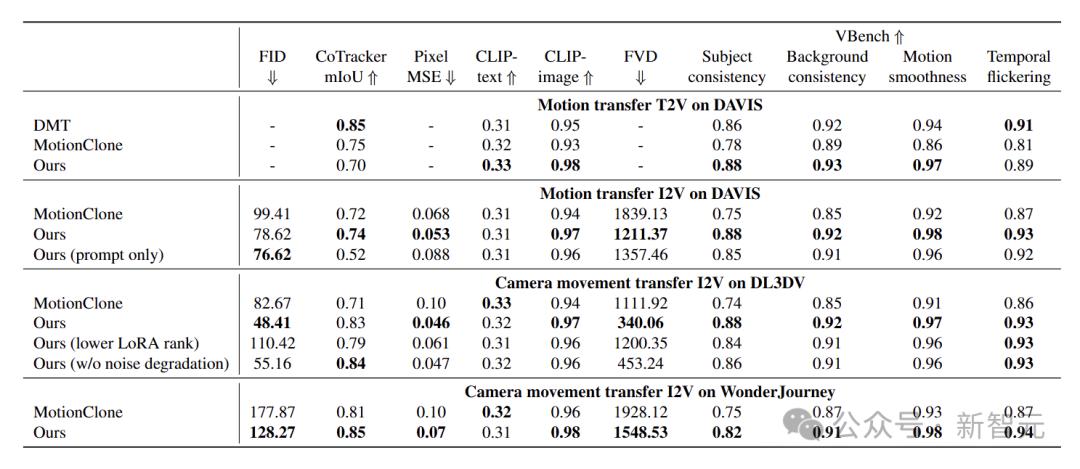
在戴维斯数据集的对象运动迁移中,运动保真度和视频质量更好,并且生成的视频和真实视频将恢复。
在DL3DV和Wonderjourney数据集以及相机运动控制上的深度失真实验中出色。
在视频第一帧编辑功能方面,它可以无缝整合新对象并保留原始运动,这明显好于基线方法。
这项研究提出了一个新颖的,比实时噪声失真算法更快,该算法可以自然地将运动控制到视频扩散噪声采样过程中。
研究人员使用这种噪声失真技术来预处理视频数据来进行视频扩散进行微调,从而提供了通用且用户友好的范式,可用于各种可动机控制的视频生成场景。

参考:
本文来自作者:Xin Zhiyuan的微信公共帐户“ Xin Zhiyuan”,由36KR发表并授权。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/273911.html
