
亨格来自奥菲神庙
量子位|官方帐户QBITAI
成本小于150元,与DeepSeek-R1和OpenAI O1相当的推理模型经过训练?呢
这不是洋葱新闻,而是由AI教母Feifei Li,斯坦福大学,华盛顿大学,艾伦人工智能实验室等发起的最新杰作:S1。
在数学和编程能力评估集中,S1的执行功能与DeepSeek-R1和O1相当。
为了培训这种表现的模型,该团队只使用了16个NVIDIA H100,训练花了26分钟。
根据TechCrunch的说法,此培训过程的云计算成本少于50美元,约为364.61元。 S1模型的一位作者说,培训S1所需的计算资源约为20美元(约合145.844元),您可以租用它。
它是如何完成的? ? ?
S1团队说,只有一个秘密:蒸馏。
简而言之,该团队将阿里巴巴汤伊团队的QWEN2.5-32B教学作为基本模型,最后通过蒸馏出Google DeepMind的推理模型Gemini 2.0 Flash Thinky Thinking Trusive实验版来获得S1模型。
为了培训S1,研究团队创建了一个数据集,其中包括1,000个问题(精心选择),每个问题都有答案,以及Gemini 2.0 Flash Thinky的实验版本的思维过程。
目前,项目论文“ S1:简单的测试时间缩放”已在ARXIV上启动,模型S1也在GitHub上开了开源。研究团队提供了培训数据和代码。
150元费用,26分钟的培训
S1团队正在做这项有趣的工作,因为OpenAI O1展示了测试时间缩放的能力。
也就是说,“在推理阶段,增加计算资源或时间以提高大型模型的性能。”这是在预先训练的缩放定律达到瓶颈之后的新缩放。
但是Openai尚未透露如何实现这一目标。
在重新出现的热潮下,S1团队的目标是找到一种简单的测试时间扩展方法。

在此过程中,研究人员首先构建了一个名为S1K的1,000个样本的数据集。
首先,基于质量,难度和多样性的原理,该数据集收集了来自数学和agieval等许多来源的59,029个问题。

在重复数据删除和降噪后,在质量筛选后,最终将涵盖1,000个精心选择问题的数据集,基于模型性能和推理痕量长度进行筛选的难度以及基于数学学科分类的多样性筛选。
每个问题都伴随一个答案,以及Google的Gemini 2.0 Flash思考实验版的模型思维过程。
这是最终的S1K。

研究人员说,测试时间缩放有两种类型。
第一种类型的顺序缩放,后来的计算取决于焦虑计算(例如推理轨迹较长)。
第二种类型是并行缩放,就像计算独立运行(例如大多数投票任务)一样。
S1团队专注于订单的一部分,因为该团队“直觉”认为它可以进行更好的扩展 - 因为随后的计算可以基于中间结果,从而可以深入推理和迭代性完善。
基于此,S1团队提出了一种新的顺序缩放方法和相应的基准。

在研究过程中,团队提出了一个简单的解码时间干预方法预算强迫,这迫使测试期间要设置的最大和/或最小思维代币数量。
具体而言,研究人员使用了一种非常简单的方法:
直接添加“思维令牌分隔符”和“最终答案”,以迫使思维的上限,以使模型尽早结束思维阶段,并提示其在当前思维过程中提供最佳答案。
为了强制在思考过程中执行令牌数量的下限,团队还禁止该模型生成“思考的令牌分隔符”,并且可以选择在当前推理轨迹中添加“等待”一词在该模型中,鼓励其思考并反思它反思当前的思维结果并指导最佳答案。
以下是预算强迫方法的实际例子:

该团队还提供了预算强迫的基线。
首先是条件长度控制方法,它依赖于在提示中告诉模型生成输出需要多长时间。
团队通过粒度将它们分为令牌条件控制,条件控制和阶级条件控制。
第二个是拒绝采样。
也就是说,在采样过程中,如果某个生成的内容符合预设的计算预算,则将停止计算。
该算法通过其长度捕获响应的后验分布。

S1模型的整个培训过程不到半小时 -
该团队在论文中指出,他们使用QWEN2.532B-INSTRUCT模型使用16个NVIDIA H100s在S1K数据集上执行SFT,培训花费了26分钟。
S1研究小组的Niklas Muennighoff(斯坦福大学的研究人员)告诉TechCrunch,培训S1所需的计算资源现在可以租用约20美元。
新的研究结果:经常抑制思维会导致死周期
在训练模型之后,团队选择了3个推理基准测试以使用S1-32B和OpenAI O1系列,DeepSeek-R1系列,Alibaba Tongyi Qwen2.5系列/QWQ,Kunlun Wanwei Sky Sky系列,Gemini 2.0 Flash Thinking Experiformentiment Experimentiment Experimentiment Experimentimp多种模型。
这3个推论基准如下:
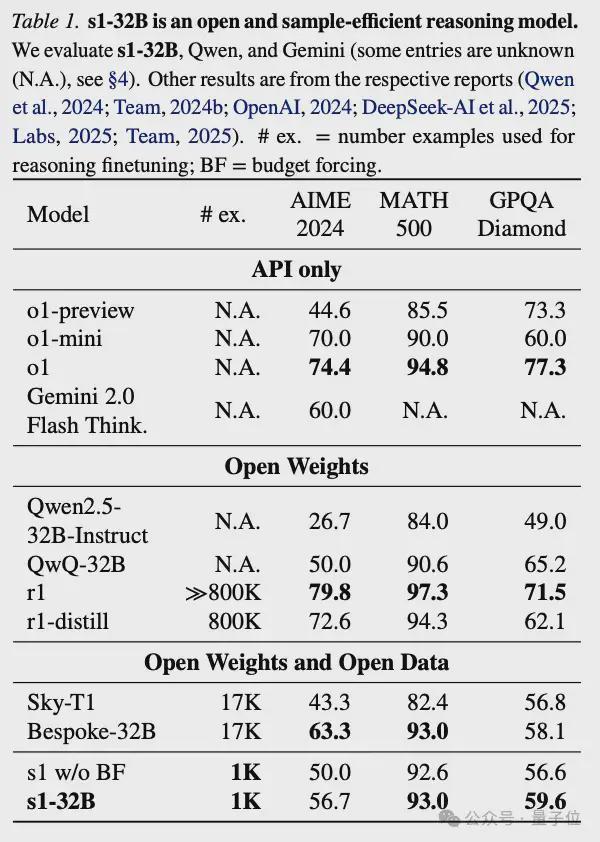
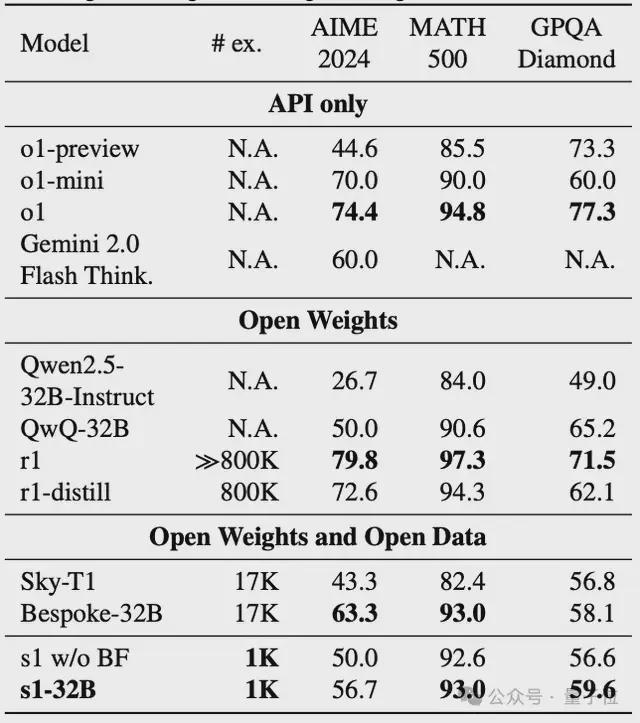
总体而言,用于预算强迫的S1-32B扩大了更多的测试时间计算。
评估数据表明,S1-32B在MATH500上得分93.0,超过O1-Mini,与O1和DeepSeek-R1相当。
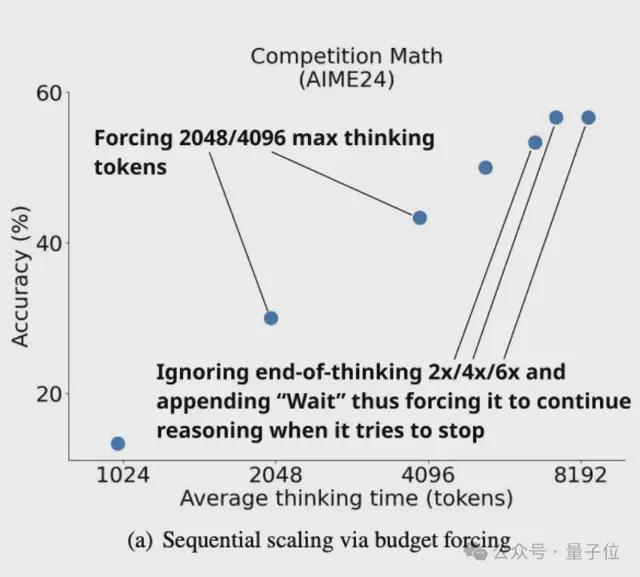
但是,如下图所示,该团队发现,尽管预算强迫和更多的测试时间计算可用于提高S1在AIME24上的性能,但在AIME24上的O1-preview的最大增长27%。
但是,经过6倍的性能提高,曲线最终变平了。
因此,团队在论文中写道:
过于抑制思维端标记定界符会导致模型进入重复循环,而不是继续推理。
如下图所示,在训练S1K上的QWEN2.5-32B教学训练以获取S1-32B之后,并为其提供了简单的预算强迫后,它采用了不同的缩放范式。
具体而言,根据大多数投票,根据基本模型的测试时间计算,受过训练的模型无法赶上S1-32B的性能。
这验证了团队以前的“直觉”,顺序缩放比并行缩放更有效。
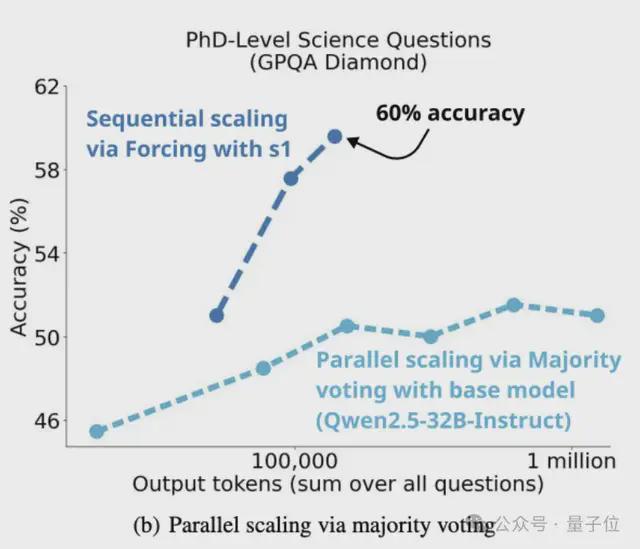
此外,该团队提到S1-32B仅使用1,000个样本进行训练,其在AIME24上的结果接近Gemini 2.0 Thinking,这是“具有最高样本效率的开源数据推理模型”。
研究人员还说,预算强迫在控制,扩展和性能指标方面表现最佳。
其他方法,例如令牌条件控制,步骤条件控制和类条件控制,都有各种问题。
还有一件事
S1模型是对小型模型能力在数学和其他评估集上飙升的小型模型能力的研究,该模型在1,000个精心选择的小样本数据集上通过SFT飙升。
但是,加上DeepSeek-R1背后的故事,该故事最近在整个网络中爆炸了,该网络与O1性能以1/50的成本相当,我们可以看到更多值得探索的模型推理技术。
在模型蒸馏技术的支持下,DeepSeek-R1震惊的硅谷的训练成本。
现在,AI的教母Li Feifei和其他人再次使用“蒸馏”作为低培训成本,并制作了一个32B推理模型,可以与顶级推理模型相匹配。
让我们期待一种更令人兴奋的2025型号技术〜
arxiv:
Github:
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/273979.html
