
Grok3 消耗的算力是 DeepSeek V3 的 263 倍,就这?
作者 | 张勇毅
2 月 18 日是北京时间。马斯克和 xAI 团队在直播里。他们正式发布了 Grok 的最新版本 Grok3。
本次发布会之前,种种相关信息被抛出,马斯克本人也进行 24/7 不间断的预热炒作,这使得全球对 Grok3 的期待值被提升到了空前的高度。一周前,马斯克在直播中评论 DeepSeek R1 时,充满信心地表示“xAI 即将推出更优秀的 AI 模型”。
从现场展示的数据能看出,Grok3 在数学、科学以及编程的基准测试方面,已经把目前所有的主流模型都超越了。马斯克还宣称,Grok 3 未来会被用于 SpaceX 火星任务的计算,并且预测“在三年内将会取得诺贝尔奖级别那样的突破”。
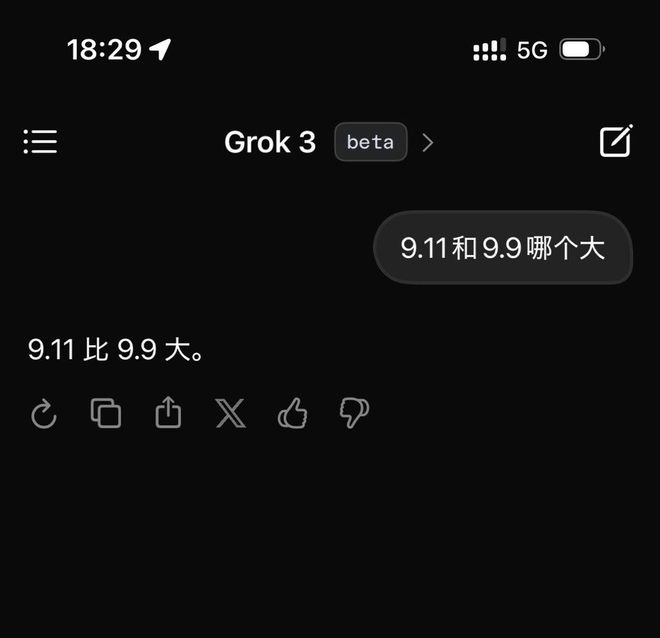
但这些目前都仅仅是马斯克所说的话。我在发布之后,对最新的 Beta 版 Grok3 进行了测试,并且提出了那个常常被用来刁难大模型的问题:“9.11 和 9.9 哪个更大?”
很遗憾,在没有任何定语和标注的情况下,被号称目前最聪明的 Grok3,依旧不能正确回答这个问题。
Grok3 未能准确地理解这个问题所表达的含义。图片的来源是极客公园。
这个测试发出后,在很短时间内迅速引起了很多朋友的关注。无独有偶,海外也有很多类似问题的测试,像“比萨斜塔上两个球哪个先落下”这类基础物理/数学问题,人们发现 Grok3 仍然无法应对。所以它被戏称为“天才不愿意回答简单问题”。
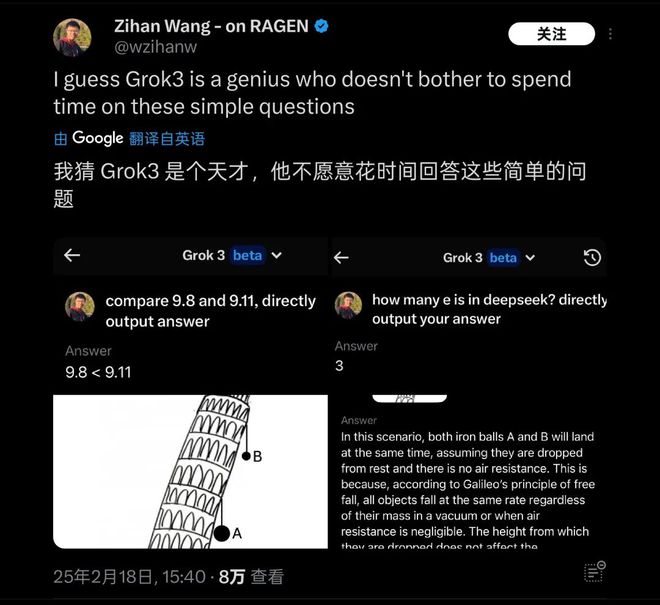
Grok3 在实际测试中,在许多常识问题方面出现了“翻车”情况。图片来源为 X。
网友自发测试了一些基础知识,Grok3 在这些方面出现了翻车。在 xAI 发布会直播中,马斯克演示用 Grok3 去分析他号称经常玩的 Path of Exile 2(流放之路 2)对应的职业与升华效果,然而实际上 Grok3 给出的对应答案大部分都是错误的。直播中的马斯克并没有看出这个明显的问题。
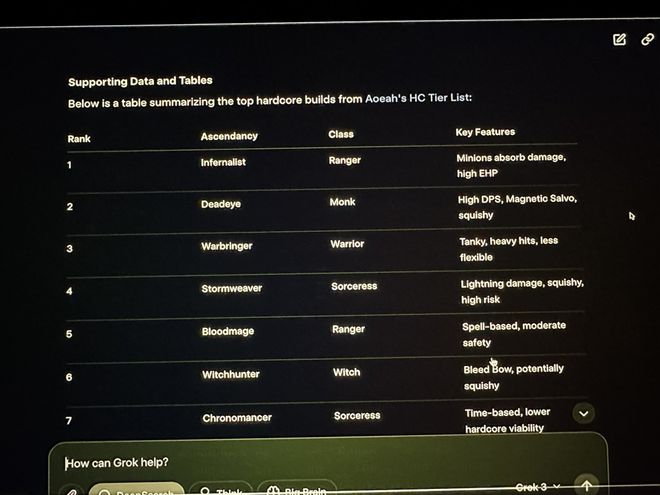
Grok3 在直播中出现了给出大量错误数据的情况。图片来源是 X。
这个失误成为了海外网友嘲讽马斯克打游戏“找代练”的证据,并且是实锤的证据。同时,这个失误也为 Grok3 在实际应用中的可靠性打上了一个大大的问号。
对于这样的“天才”,不管其实际能力到底是怎样的。要是未来将其用于火星探索任务这样极为复杂的应用场景,那么它的可靠性就得打上一个大大的问号。
目前,众多模型能力测试者,他们有的在几周前获得了 Grok3 的测试资格,有的则是在昨天刚刚用上了几个小时。对于 Grok3 当前的表现,他们都指向了一个相同的结论。
Grok3 是很不错的。然而,它并不比 R1 要好,也不比 o1-Pro 更好。

Grok3 很不错,然而它并不比 R1 更优,也不比 o1-Pro 更好。 | 图片来源:X
Grok3 在发布的官方 PPT 里,在大模型竞技场 Chatbot Arena 中达到了“遥遥领先”的状态。然而,这其实运用了一些小小的作图技巧,即榜单的纵轴只列出了 1400 - 1300 分段的排名,从而使原本 1%的测试结果差距在这个 PPT 展示中变得极为明显。
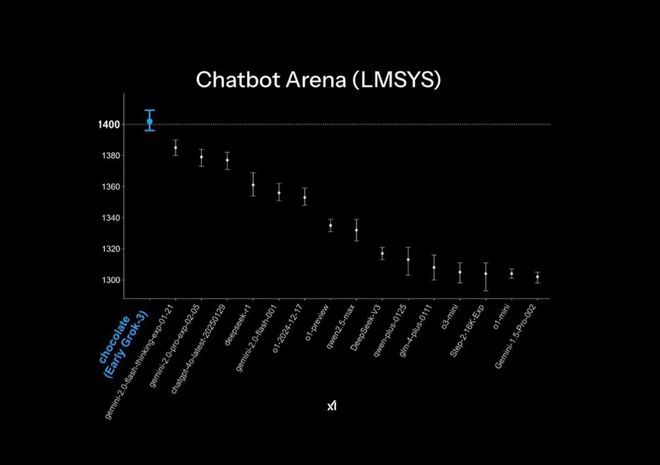
官方发布 PPT 中的「遥遥领先」效果 | 图片来源:X
实际的模型跑分结果显示,Grok3 与 DeepSeek R1 以及 GPT4.0 相比,差距仅在 1%到 2%以内。这在不少用户的实际测试中,给人一种“并无明显差别”的感觉。
实际上的 Grok3,其性能比后来者仅仅高出 1%到 2%。图片来源为 X。
此外,在分数方面,Grok3 超过了目前公开测试的所有模型。然而,这一点并没有被很多人认可:毕竟 xAI 在 Grok2 时代就曾在这个榜单中“刷分”,并且随着榜单对回答长度风格进行降权处理,其分数大幅降低。因此,它经常被业内人士诟病为“高分低能”。
榜单存在“刷分”现象,配图设计有“小技巧”,这些都体现出 xAI 以及马斯克本人对模型能力“遥遥领先”这件事的执着。
马斯克为了这些差距付出了高昂的代价:在发布会里,他用近乎炫耀的语气说,用了 20 万张 H100(他直播中表示使用“超过 10 万”张)来训练 Grok3,总训练小时数达到了两亿小时。这部分人觉得这是对 GPU 行业的又一重大利好,并且认为 DeepSeek 给行业带来的震动是“愚蠢”的。
不少人认为堆砌算力将会是模型训练的未来 | 图片来源:X
有网友对比了用 2000 张 H800 训练两个月所得到的 DeepSeek V3。他们计算出 Grok3 实际的训练算力消耗是 V3 的 263 倍。同时,DeeSeek V3 在大模型竞技场榜单上与得分 1402 分的 Grok3 的差距,还不到 100 分。
这些数据出炉之后,就有许多人迅速意识到,在 Grok3 登上“世界最强”的背后,蕴含着这样一种逻辑:模型越大,性能就越强,并且已经呈现出了明显的边际效应。
即使是被称为“高分低能”的 Grok2,它的背后也有 X(Twitter)平台内大量的高质量第一方数据作为支撑以便使用。而在 Grok3 的训练过程中,xAI 自然也会遭遇到 OpenAI 当前正在遭遇的“天花板”,即优质训练数据的匮乏,这使得模型能力的边际效应迅速显现出来。
最早意识到这些事实并且理解最深刻的人肯定是 Grok3 的开发团队与马斯克。所以马斯克在社交媒体上不断表示,当前用户体验到的版本“还仅仅只是测试版”,“完整版将在未来几个月推出”。马斯克本人还化身成 Grok3 产品经理,建议用户直接在评论区反馈使用时遇到的各种问题。

他大概是地球上粉丝数量最多的产品经理 | 图片来源:X
在不到一天的时间里,Grok3 的表现给后来者敲响了警钟。后来者曾寄希望于依靠“大力飞砖”来训练出能力更强的大模型。根据微软公开的信息推测,OpenAI GPT4 的参数体积为 1.8 万亿参数,与 GPT3 相比已经提升了超过 10 倍。并且传闻中的 GPT4.5 的参数体积还会更大。
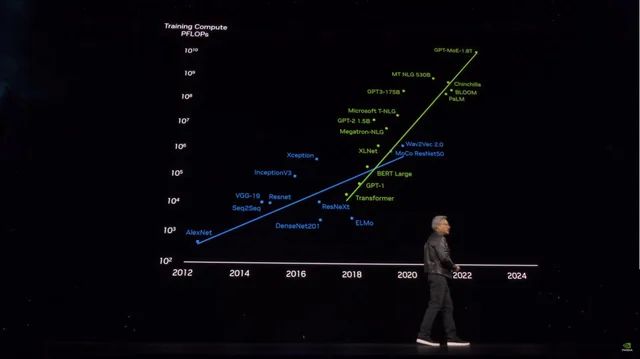
模型参数体积飞涨的同时训练成本也在飙升 | 图片来源:X
有 Grok3 存在。GPT4.5 以及其他那些想要继续投入大量资金,通过增加参数体积来获取更好模型性能的选手,都必须要考虑到那个已经离得很近的天花板,并且思考该如何突破它。
此时此刻,OpenAI 的前首席科学家 Ilya Sutskever 在去年 12 月表达了这样的观点:“我们所熟悉的预训练将会结束”。这一观点又被人们重新记起,并且人们试图从其中找到大模型训练的真正出路。

Ilya 的观点,已经为行业敲响了警钟 | 图片来源:X
彼时,Ilya 准确地预见到了新数据即将接近枯竭的情况,同时也预见到了模型难以再通过获取数据来提升性能的状况。他将这种情况形容为化石燃料的消耗,还表示“正如石油是有限资源一样,互联网中由人类生成的内容也是有限的”。
Sutskever 预测,预训练模型之后的下一代模型会有“真正的自主性”,并且将具备“类似人脑”的推理能力。
如今预训练模型主要依赖内容匹配(基于此前学习的内容),而未来的 AI 系统则不同,它能够以类似人脑“思维”的方式,逐步学习并建立起解决问题的方法论。
人类要基本精通某一学科,仅靠基本专业书籍就能做到。而 AI 大模型需学习数以百万计的数据才能达到最基础的入门效果。甚至当问法改变后,这些基础问题它也无法正确理解,模型在真正的智能方面并未提升。文章开头提及的那些基础问题,Grok3 仍无法正确回答,这就是该现象的直观体现。
但除了“力大飞砖”之外,如果 Grok3 真的能够向行业揭示“预训练模型即将走到尽头”这一事实,那么它对行业而言仍然具有重要的启发意义。
或许,在 Grok3 的狂潮渐渐退去之后,我们能够看到,会有更多像李飞飞那样“在特定数据集的基础上用 50 美元微调出高性能模型”的案例出现。并且在这些探索过程中,最终能够找到真正通往 AGI 的道路。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/274375.html
