
3 月 21 日有消息称,OpenAI 推出了三款全新的语音模型。其中有两款是语音转文本(STT)模型,分别是 GPT-4o Transcribe 和 GPT-4o Mini Transcribe。还有一款是文本转语音模型 GPT-4o Mini TTS。这三款模型是专门为支持语音智能体而进行设计的,并且目前已向全球的开发者开放。

GPT-4o Transcribe 和 GPT-4o Mini Transcribe 与最初的 Whisper 模型相比,在单词错误率(WER)和语言识别准确性方面有显著提升。它们在包括 FLEURS(Few-shot Learning Evaluation of Universal Representations of Speech)——涵盖 100 多种语言的多语言语音基准测试——在内的基准测试中实现了更低的 WER。在英语、法语等语种中,其错误率远低于包括 gemini-2.0-flash 在内的模型。
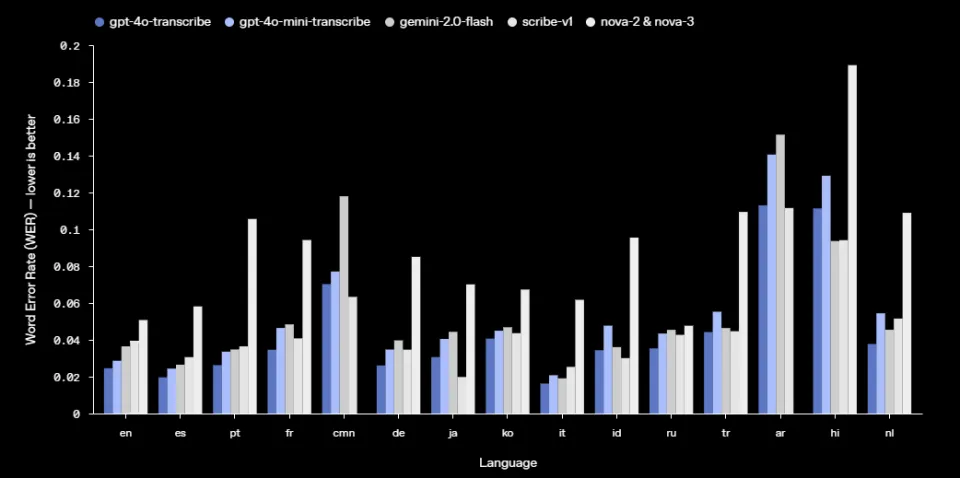
- WER 越低,就表示错误越少,性能也就越好。
OpenAI 提供的数据表明,在英语基准测试里,GPT-4o Transcribe 的错误率低于 3%。
OpenAI 称,这些新的语音转文本模型有能力更好地把握住语音的细微差异,能够减少错误识别的情况,还能提升转录的可靠性。尤其在面对口音、嘈杂环境以及语速变化等复杂场景时,其表现格外出色。当下,相关模型已通过语音转文本 API 进行提供。
前两款模型主要侧重于准确率的提升,而 GPT-4o Mini TTS 模型在可操控性方面表现更优。

OpenAI官方提供了多种不同情景下的Agent参考发音
OpenAI 表示开发者不但能够“指示”模型去说什么,而且还可以指定其说话的方式(以指定的情绪来表达),这样就能为多种应用场景提供更具定制化的体验,这些应用场景涵盖了客户服务以及创意故事叙述等,并且该模型现在已经通过文本转语音 API 进行提供。
需要注意的是,现阶段这些文本转语音模型可使用的音色仅限于 OpenAI 人工预设的语音。OpenAI 表示,会进行监控以确保这些语音始终符合合成语音的预设标准。
OpenAI 称,在过去的几个月当中,该公司一直都在努力提升基于文本的智能体的智能性、功能性以及实用性,并且推出了像 Operator、Deep Research、Computer-Using Agents 以及内置工具的 Responses API 这样的产品。然而,要让智能体真正具备实用性,用户得有能力以更深入、更直观的方式与它互动,而不能仅仅依靠文本进行交流。
这些新的语音模型具备让开发者构建更强大语音智能体的能力,还能让智能体可定制且智能,进而提供更有价值的服务。这些模型在准确性与可靠性方面表现出色,尤其是在处理口音、嘈杂环境以及语速变化等复杂场景时。这些改进提升了转录的可靠性,使得这些模型特别适合用于客户呼叫中心、会议记录转录等应用场景。
相关报道
OpenAI深夜发布3个全新的语音模型,一手实测都在这了
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/275064.html
