
LLM 的推理能力有了显著的提升。然而,这个被称为“超级大脑”的存在也有着它自身的困扰。
有时候回答会绕一个很大的圈子,其推理过程既冗长又复杂。虽然最终能得出正确答案,但是却耗费了不少时间和计算资源。
问它“2 加 3 等于多少”时,它或许会从数字的概念以及加法原理着手,然后滔滔不绝地说上很多,在实际应用中,这对效率的影响是非常大的。
华人研究者来自 Rice 大学,他们提出了“高效推理”的概念,既能保证回答准确,又能以更快、更简洁的方式给出答案。

论文链接:
项目链接:
接下来,深入探讨LLM的高效推理,帮它们告别「过度思考」。
别让模型「想太多」,迈向高效推理
LLM 凭借思维链(CoT)提示这类技术,在复杂的推理任务里表现得很出色。
CoT 就如同给模型安装了“思考引擎”,它能够逐步地进行推导,并且可以将推理过程清晰地呈现出来。
不过,这份出色的表现,需要消耗大量计算资源。
LLM 时常会有“过度思考”的状况发生,它会生成冗长且冗余的推理内容,从而使得延迟增加并且消耗了资源。
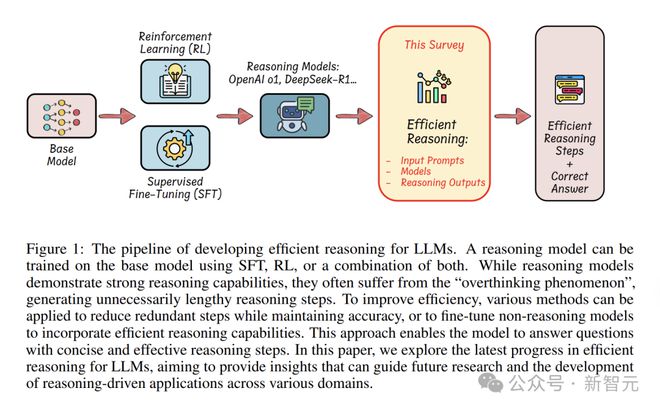
本文关注如何在提升或维持模型性能的同时,对推理过程进行优化,这在计算资源有限的实际场景中是非常重要的。
研究者梳理了应对「过度思考」,实现高效推理的技术手段:
研究者介绍了以下内容:用高效数据来训练推理模型;对小模型的推理能力进行探索;讨论了评估方法以及基准测试。
认识「过度思考」
LLM 产生推理过程时,如果这个过程冗长且不必要,就出现了“过度思考”现象。
在回答“0.9 和 0.11 哪个大”这个简单问题时,DeepSeek-R1 这个模型给出的答案很冗长。同时,QwQ-32B 这个模型给出的答案也很冗长。
它或许会以十进制的原理作为开端,对小数点后的每一位数字进行分析。同时,它还会尝试运用各种方式进行验证,例如将其转化为分数,或者在数轴上进行表示。最后,它才会给出答案。
答案是正确的,然而其推理过程较为冗长且啰嗦,耗费了诸多时间和计算资源。

DeepSeek-R1:我需要判断 0.9 和 0.11 谁更大。这两个数都是小数,且小数点后的位数不同。我先思考每个小数的含义,0.9 意味着十分之九,因为其小数点后第一位是十分位。我再换个方法确认一下,将它们转化为百分数试试……为了保证没错,我在数轴上把它们表示出来。还有其他的验证方法吗?用减法或许可以;或者;我能确定答案是 0.9。
要判断 0.9 和 0.11 谁大。它们属于小数,那就逐位进行比较吧?我得回忆一下小数比较的规则……0.9 的小数点后有 1 位,而 0.11 有 2 位,在写法上是不是需要调整呢……哎呀,不对,我得再检查检查,是不是哪里出错了。换个思路……还有另一种办法……最终得出的答案是 0.9 更大。
从这个例子可以看出“过度思考”的几个特点:其一,在回答简单问题时,两个模型都写了 600 多字;其二,在推理过程中,存在很多重复以及多余的验证方法。
推理内容如果越长,那么处理所需的时间就会越多。模型会不断地对自己的推理过程产生怀疑。
在资源有限的环境里,在像自动驾驶、智能交互助手这类需要实时响应的应用场景中,“过度思考”所导致的效率低下问题会显得格外突出。
开启高效推理
高效推理方法包含以下三类:一是基于模型的有效推理;二是针对结果的优化;三是借助输入提示的有效推理。
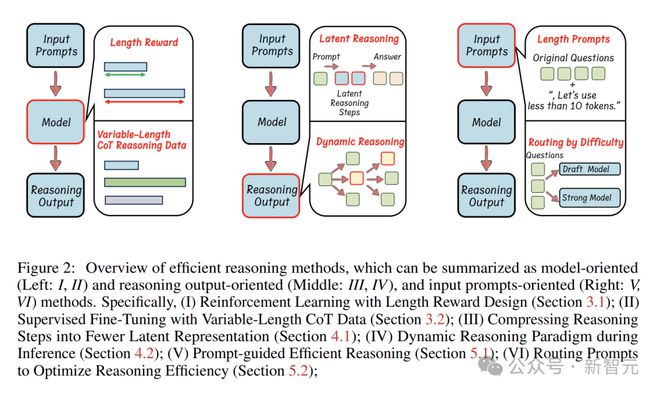
基于模型的有效推理
一种有效的做法是在强化学习(RL)中添加长度奖励,以此来引导它生成简洁的推理。
以前在模型训练时,主要将注意力放在答案的正确性以及格式的规范性上。现在,研究人员为其增添了一个新的“考核指标”,这个指标就是推理长度。
就像老师不仅要求学生答对题,还要求答题过程简洁明了。

奖励函数通常是这样的:
α的作用是调节长度惩罚在奖励函数中的权重,R_length是依据推理响应长度而设置的惩罚项,其计算方式如下:
模型为获取更多奖励,会在确保答案准确的情况下,尽量减少使用 token。

利用可变长度的 CoT 数据进行监督微调,这是一种有效的方法,能够提升推理效率。
这好比给模型提供了不同难度的“练习题”,让它学会应对各种情况;这也好比给模型提供了不同长度的“练习题”,让它学会应对各种情况。
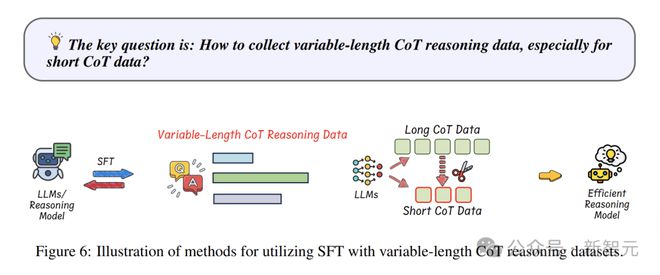
训练数据中既有完整详细的推理链,也有简短、高效的推理路径。
这些示例能让模型学会,在不降低准确性的情况下,采用更简洁高效的推理模式。
在微调模型时,一方面可以运用像 LoRA 这样的标准微调方法,对模型参数进行小范围的调整;另一方面可以采用渐进式微调,使模型逐渐适应新的思考节奏,进而逐步提升推理效率。
优化推理输出,精简思考过程
从推理输出这一角度来看,研究人员尝试运用创新的手段去压缩推理的步骤,以使模型的“思考过程”变得更为精简。
这些方法不改变模型的参数,直接对推理输出的结果进行优化。
潜在推理技术能够将推理步骤压缩成更为精简的表达形式。图中展现了诸多以更高效格式进行编码的潜在推理方法。
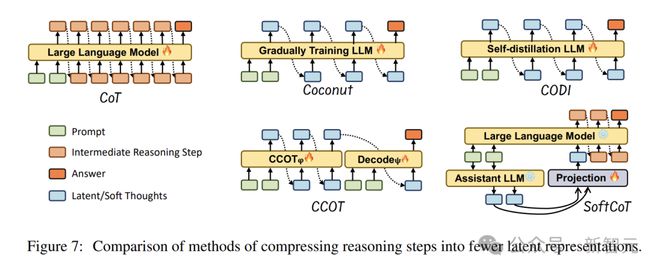
这些方法常常会运用嵌入函数,将冗长的推理内容映射至一个更为紧凑的空间之中,其用公式来表示即为:
E_compact 是经过压缩后的一种推理表示形式,f 是被学习到的变换函数。
在推理过程中,除了利用潜在表示之外,动态调整推理策略也是提高效率的关键。
动态推理会依据每个问题的实际情况,按照需求来生成推理步骤。图中对两种典型的技术进行了介绍。
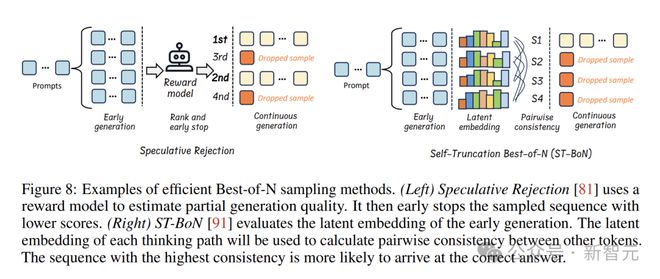
在奖励引导方面,推测拒绝对最佳 N 解码算法进行了优化。在生成多个响应时,依据奖励模型的评估结果,会及时把低质量的输出丢弃掉,以此减少不必要的计算开销。
面对复杂问题时,它会首先大量生成诸多可能的推理路径。接着,它会快速地把那些没有希望的路径排除掉。之后,只留下高质量的路径继续进行推理。这样就大大提高了推理效率。
这两种技术的核心思路在于,依据问题的复杂程度来灵活地调整推理深度,其用公式可表示为:
借助输入提示,巧妙引导思考
从输入提示的角度入手,也能让模型推理变得更高效。
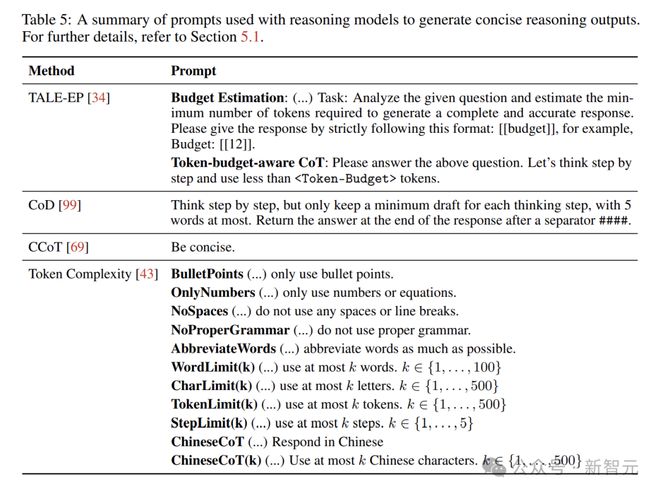
长度约束提示较为简单实用,可直接在提示中要求模型控制推理长度,例如“用不超过 10 个 token 回答下面的问题”。
CoD 方法在逐步推理时,仅保留每个思考步骤的少量草稿,最多五个单词。
在解答数学题时,模型不再将每一步的推导过程详细写出,而是以简洁的几个词来概括关键思路。这样做既能保证准确性,又能大幅减少 token 的使用。
不同的任务难度不同,对推理的要求也不一样。
因此,按照输入提示的属性来进行推理路由,这是一种能够提高效率的策略。
RouteLLM训练了一个查询路由器,这个路由器会依据问题的复杂程度,把查询分配给恰当的模型。
把简单的问题交给速度快但推理能力较弱的模型去处理,将复杂的问题交给能力更强的模型,如此一来,能够充分利用不同模型的优势,进而提升整体的推理效率。
Self-Ref 方法能够使 LLM 依据自身的不确定性分数去判断是否需要路由至更强大的模型。
模型若对自身的答案不太有把握,便会自动去寻求更强大模型的协助,从而减少那些不必要的推理步骤。
其他探索
研究人员除了在上述方向开展工作外,还在数据方面进行了深入探索,在模型方面进行了深入探索,在评估方面也进行了深入探索,目的是进一步提升 LLM 的推理效率。
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/275309.html
