

如果人工智能如同一块蛋糕,那么无监督学习构成了蛋糕的主要部分,监督学习犹如蛋糕上的糖霜,强化学习(RL)就像是顶上的那颗樱桃。
作者 | 贾阳
强化学习重新焕发出了性感的特质。
3 月 5 日,2025 年的图灵奖被颁发给了强化学习的两位理论奠基者。一位是安德鲁·巴托(Andrew Barto),另一位是理查德·萨顿(Richard Sutton)。

这次颁奖,像是一个信号在不断放大。这个信号揭示了一个转折,这个转折越来越明确,是 AI 研究范式的转折。这个转折就是引入 RL,使得 AI 研究从“快思考”(快答出预训练的回复)推进到“慢思考”(在推理时深思熟虑)。
在过去的这一年里,RL 从处于一种沉沦的状态,重新回到了 AI 研究的闪光灯聚焦之处。2024 年的下半年,OpenAI 率先公布了它基于 LLM,通过 RL 达成“深度思考”的成果,即 o1,并且设定了新的终点线。今年初,DeepSeek 迅速驱散了赛道上的迷雾,将自己的方案完全开源。它在 LLM 中加入了“纯 RL”,使得 R1 的推理能力能够比肩甚至超过 o1。关于 RL 能够帮助通往 AGI 的共识,迅速凝聚起来。
一些RL领域的研究者几乎要喜极而泣了。


AlphaGo曾以令人惊艳的“神之一手”战胜了人类围棋的顶尖高手李世石,这使世人首次大规模地感受到了 AI 的智力带来的惊喜与惊吓。RL 是 AlphaGo 训练的理论基础。
RL 的研究者们认为,机器的学习情况,可以和人类进行类比。就如同多巴胺能够激励神经元一样,机器也能够通过与环境的反馈互动,不断地改进和提升自身的能力。人类的时间经验是有限的,然而机器却不会受到这些限制,在 RL 领域中,机器具有超人的潜力。
这曾经一度是人们对通往AGI的最主流想象。
但在 2020 年之后,有更多的人被“LLMs 和缩放定律就是你所需要的”这一观点吸引走了。大语言模型以及不断壮大的预训练数据集,把 AI 的智能推进到了新的阶段,同时也使不走“大力出奇迹”路线的 RL 相对处于边缘地位。
LLM 能够展现出看似更具通用性的智能。RL 则只能在奖惩明确的特定环境里进行训练,从而培养出“专科”智能,它仅仅能够“玩游戏”,却无法应对复杂的现实环境。
在一些论坛的 AI 板块讨论里,从业者们清晰地察觉到,RL 的“市场关注份额”在减少,有人在抱怨“找不到 RL 工作”(I can’t find an RL job)。一些关于“RL 是否走进死胡同”的争论更是十分有趣。RL 的支持者和 LLM 的支持者激烈地进行争论,探讨谁能更好地模仿人类的自然认知模式,以及谁更有前途。
大语言模型的 scaling law 开始遇到阻碍,接着科技树上展开了一场新的较量。
这是一部人类智慧交替闪耀的故事。在通往 AGI 的道路上,起初一片黑暗。有人采用刀耕的方式,有人运用火种,还有人凭借哲思,他们都曾取得成就,也都曾遭遇瓶颈。而当新的障碍出现时,这些方法的新组合将人类带到了新的起点。
AlphaGo
2016 年 3 月的首尔,这里正在发生深度学习历史上极具开创性的时刻之一。AlphaGo 击败了欧洲围棋冠军 Fan Hui 之后,正式向全球围棋冠军李世石发起挑战。这被全球媒体看作是人类智识尊严与人工智能的对决。
AlphaGo 以 4:1 的绝对优势战胜了 14 次围棋世界冠军得主李世石,结果十分惊悚,人类遭遇了轰轰烈烈的落败。
在第二局的第 37 手时,AlphaGo 走出了一招,这招让所有人都感到十分困惑。它落在了第五线,而不是传统上最优选的第三线。解说室里的人都懵了,一位评论员表示不知道这招到底是好还是坏,另一位则说“这是一个错误”。
第 37 手出现的概率为万分之一。AlphaGo 的研究员认为,没有人类会如此下这一手,但这一手依然是正确的,因为它通过内省过程得出了这一结论。同样在观战的 Fan Hui 评价这手棋是“神之一手”。
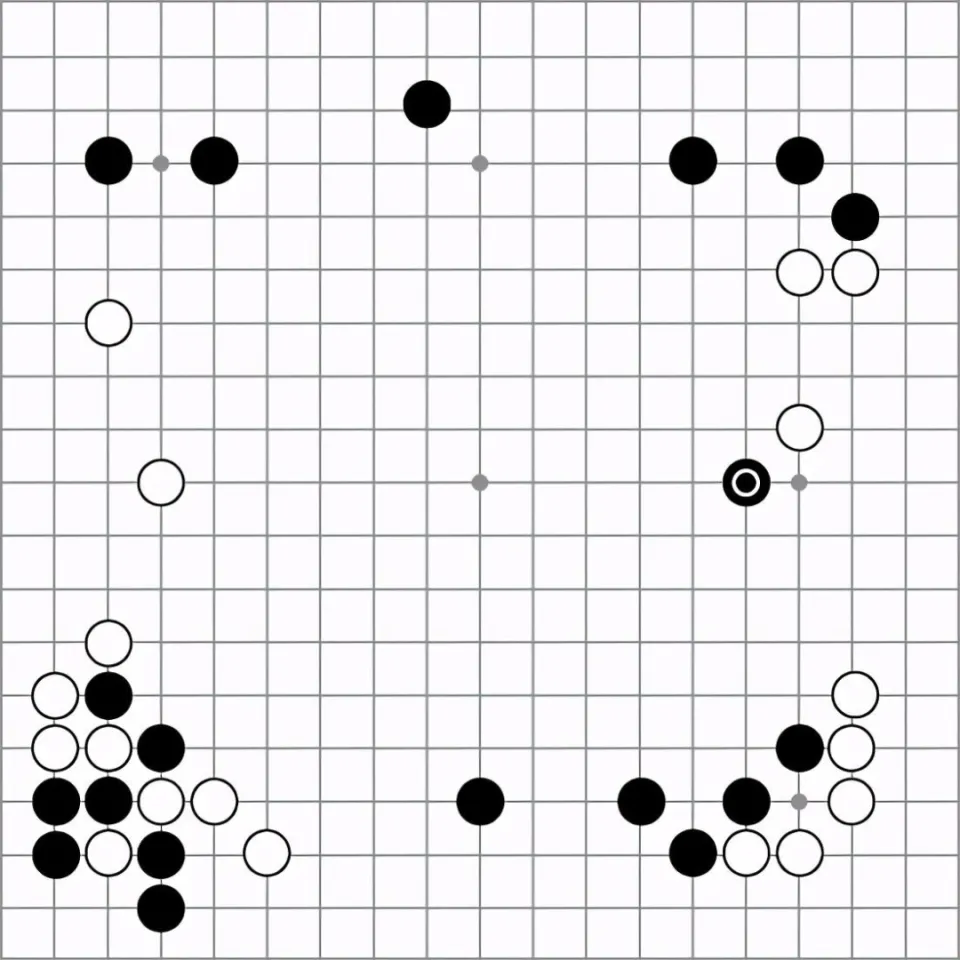
右侧新落的黑子,为AlphaGo的传奇第37手
AlphaGo 战胜了李世石,这使得 AI 在公众的认知中一下子爆发了。AI 迎来了前所未有的希望和期待,甚至让大众第一次真正开始恐惧“AI 比人更聪明”。RL 具有巨大的潜力,其恐怖程度如同这般。
谷歌的核心高管全部来到了首尔,他们要见证这个“代表谷歌互联网业务未来”的 AI 技术。此次比赛对于谷歌而言是极为重要的。
谷歌是 2010 年代那一轮历史性的 AI 人才争夺战中的积极下注方。辛顿(Geoffrey Hinton)凭借仅 4 颗 GPU 以及更优的神经网络算法,将谷歌使用 16000 颗 CPU 的“谷歌猫”超越,这令业界震惊。谷歌花费 4400 万美元买下辛顿三人的纯智力公司。谷歌还投入 4 亿英镑将英国初创公司 DeepMind 收归旗下。
DeepMind 当时向谷歌展示的 RL 路线,与谷歌当时在神经网络做图像识别、音频理解等方面的研究方向不同。然而,创始人哈萨比斯(Demis Hassabis)汇聚了当时极为优秀的一批人才,这是十分珍贵的,哈萨比斯和许多同事都可算作辛顿的学生。更重要的是,哈萨比斯凭借“围棋”以及“打造与人脑类似的通用人工智能”这两点,成功地说服了彼得·蒂尔(Peter Thiel)投了 140 万英镑。同时,这也让谷歌相信了 RL 使 DeepMind 构建了一个系统,而这个系统是在通用人工智能方面的首次真正尝试。
DeepMind 向谷歌证明自己的第一步是攻克古老的围棋。哈萨比斯是个学霸且爱玩游戏,他从事 AI 研究,将两个爱好完美融合,把 AI 投入到游戏中,通过反复试错,直至它的游戏水平比人类更出色。
AlphaGo 拥有两个神经网络。其中一个神经网络负责策略方面的工作,它会输出下一步落子的概率;另一个神经网络则是价值网络,其作用是输出落子的胜率。AlphaGo 首先学习了 3000 万步围棋专家的下法。接着,它一场接着一场地与自身进行对抗,通过分析哪些下法更为有利,从而实现了飞速的进步。
DeepMind 在后续的版本 AlphaGo Zero 里,将 RL 推进到了极致。它不再给予海量对弈棋局的初始数据,只是告知基本规则,然后让其自我对弈数百万次,从而发现获胜策略。AlphaGo Zero 经过 3 天的训练,便获得了比击败李世石的那个版本更强大的能力,与后者对弈时的胜率是 100 比 0。
AlphaGo Zero 比 AlphaGo 强大很多,原因在于其 RL 占比提高了。给它取名为 Zero,这暗示着它是真正从无开始,完全通过自身学习而成才的。
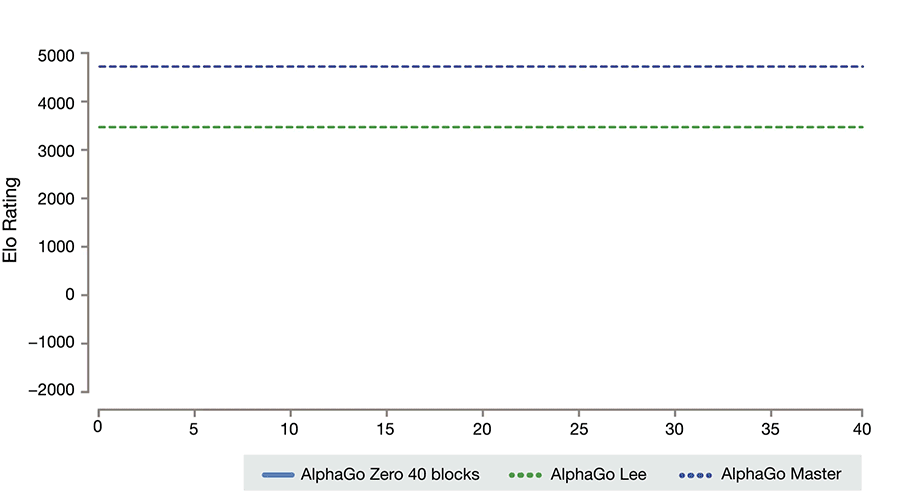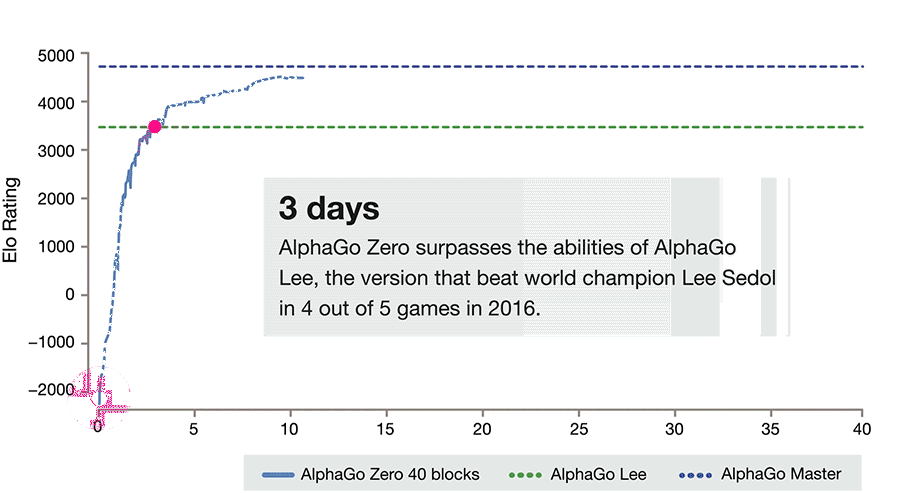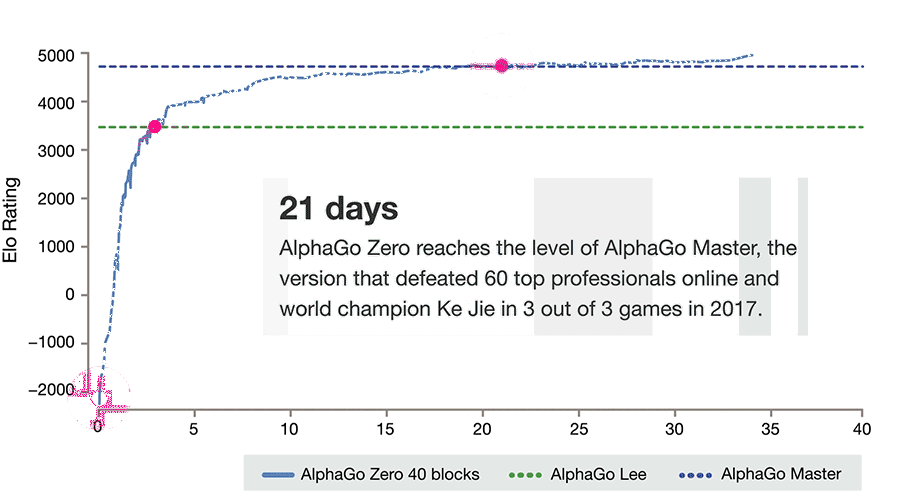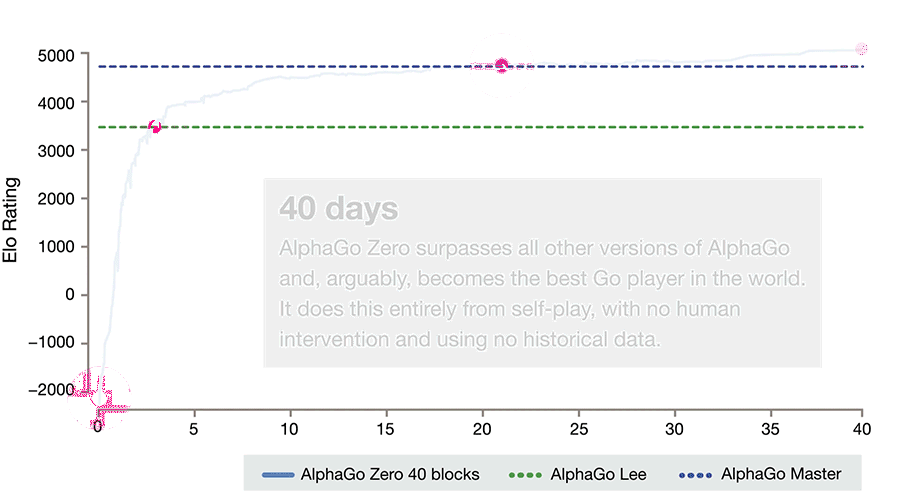
DeepMind 的论文《Mastering the game of go without human knowledge》在一时之间非常火爆。这篇论文表明,即便处于最具挑战性的领域,仅仅运用 RL 的方法也是完全可以做到的。也就是说,没有人类的实例或指导,也没有基本规则之外的知识,依然有可能训练出达到超人性能的结果。
AlphaGo Zero 更为简洁且优美。AlphaGo 的初始版本需 176 个 GPU 与 1202 个 CPU,而 AlphaGo Zero 仅需一台机器和 4 个 TPU。
AlphaGo Zero 把 RL 的路线推到了业界热情的最高处。2018 年 12 月,AlphaGo Zero 登上了《科学》杂志的封面。《科学》杂志作出了这样的评价,即单一算法能够解决多个复杂问题,这是创建通用机器学习系统、解决实际问题的重要一步。
DeepMind 商业计划书的第一行所提及的是通用人工智能。彼时取得的巨大成功,使得哈萨比斯更加坚定地确认了 DeepMind 的使命,他认为这是开发通用算法过程中的一大进步。
DeepMind 持续对如何提升 AlphaGo 进行研究,并将其能力迁移至其他领域。AlphaGo Zero 具有更强的通用性,它不仅在围棋领域表现出色,还能轻松在国际象棋、日本将棋领域达到顶尖水平。AlphaFold 在预测蛋白质结构方面取得了显著成就,哈萨比斯也因之获得了诺贝尔化学奖。AlphaStar 具备玩《星际争霸 II》的能力。
业界对这一探索方向寄予很大希望。RL 相关的论文数量急剧增加。在机器人行业、自动驾驶行业以及储能行业,RL 是一种极为合适的训练学习路径,并且行业研究在不断深入。
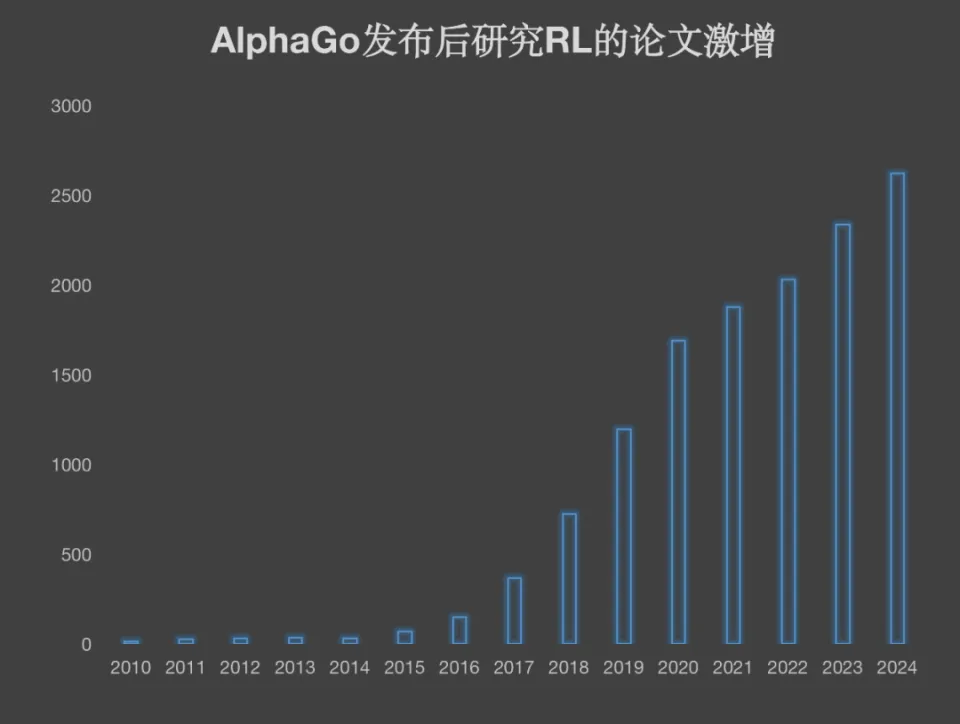
仅统计了arXiv,制图20社
“死胡同”
辛顿对哈萨比斯的个人聪明程度评价颇高,说“他的实力不仅体现在智力方面,还体现在他对胜利有着极端且坚定不移的渴望上”。辛顿曾在英国担任过哈萨比斯短暂的导师。在 2014 年谷歌收购 DeepMind 之际,他还特地克服了腰椎间盘病痛导致无法乘坐民航飞机的困难,前往伦敦提供了关键的科学顾问服务。
但这位连接主义的大拿,对哈萨比斯认定的RL路线并不认可。
2018 年,辛顿以及杨乐昆(Yann LeCun)、约书亚·本吉奥(Yoshua Bengio)凭借神经网络深度学习荣获图灵奖。在其获奖后的演讲里,辛顿开玩笑般地表示要将 RL 从机器学习方法中排除出去,原因是“被称作强化学习的第三种方法并非十分有效”。RL 要完成真实世界中的实际任务,需要大量的数据以及过多的处理能力。
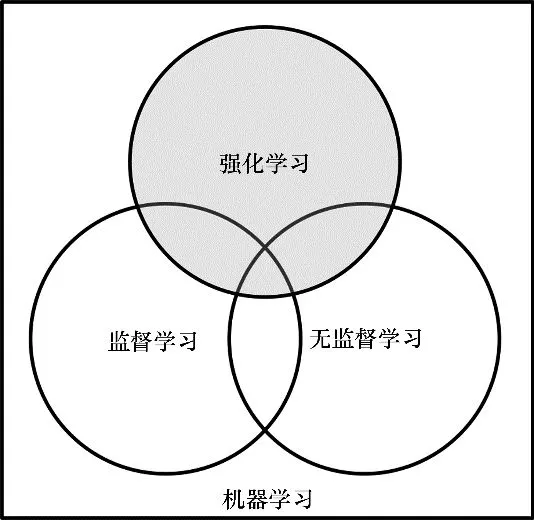
要理解他们之间的分歧,我们需要了解一些背景框架。
在 AI 的漫长探索历程中,研究者们都在努力以人类认知世界的那种本质方式,来构建机器智能的框架,也就是进行模仿。所以,AI 的理论演进,始终与人类心理学、脑科学、神经科学、哲学以及语言学的发展相互交织、纠缠在一起。由于对本质有着不同的认知,这使得 AI 研究者分化成了主要的三大流派。
符号主义认为人的认知单元为符号,并且主张通过公理逻辑以及符号操作来模拟人类的智能。该流派曾一度最先获得实践应用,也是最风靡的流派。IBM 的“深蓝”打败国际象棋世界冠军这件事,本质上属于符号主义的成果。
连接主义源自仿生学,它主张通过模拟人脑神经元的连接方式来达成人工智能。如今在 AI 领域,有几位宗师级的大牛,其中辛顿和杨乐昆是扛鼎者,神经网络是模仿人脑的成果,并且是现在最主流的理论派别。
行为主义关注行为与刺激的关系,能让机器通过与环境交互去学习并改进自身行为,而这正是 RL 所属的流派。
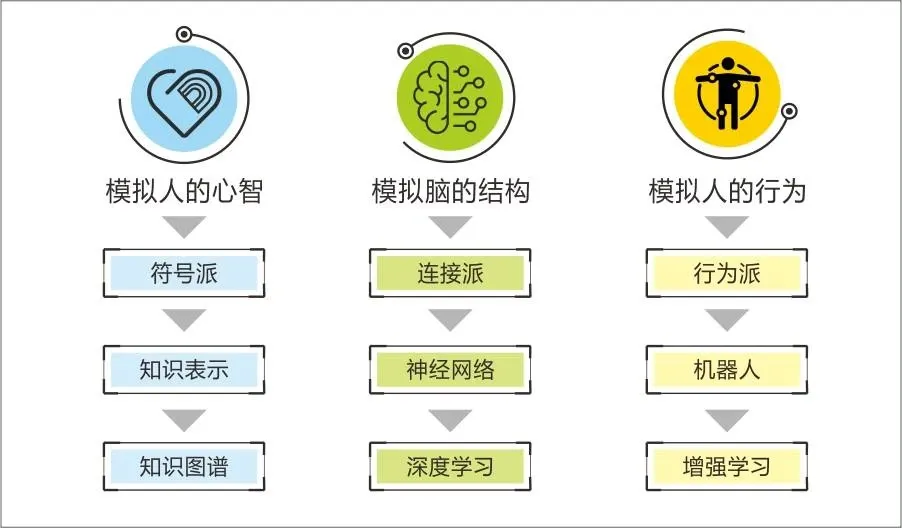
图片来源于网络
事实上,RL 的发展历程充满曲折。它经历了多次漫长的寒冬,也经历了多次漫长的等待。
1950 年最早的时候,艾伦·图灵提出了 RL 的初步设想,这是一种借助奖励和惩罚来进行的机器学习方法。
几十年后的 1980 年代,在这个想法的基础之上,处于 AI 的寒冬之中,巴托与萨顿在麻省理工默默进行了工作。他们搭建了 RL 的理论框架和算法体系,其中最核心的贡献是时间差分学习算法,此算法解决了奖励预测的问题,也解决了 agent 如何获得长期收益的问题。
40 年后,巴托和萨顿凭借对强化学习的研究,获得了图灵奖的迟来奖励。
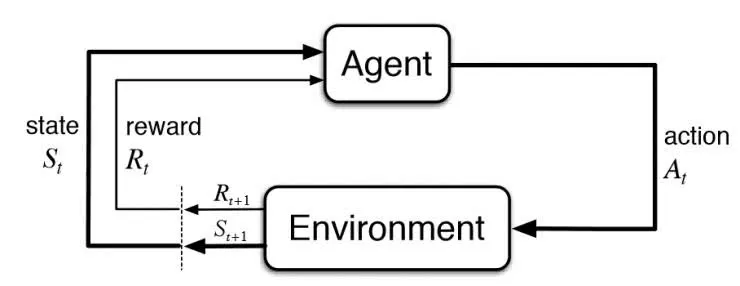
RL 的进展受到算法、算力、数据这三大方面的限制。DeepMind 能够凭借 RL 创造出让世界震惊的 AlphaGo,其中一个重要的缘由是,它将辛顿等连接主义学者所取得的“神经网络”这一成果运用了过来。AlphaGo 是由两个 13 层的深度神经网络所组成的。
神经网络被引入并且泛化能力也被引入,这从根本上对 RL 进行了改变。传统的 RL 是依赖于表格的方法,像 Q-learning 以及动态编程的,一般情况下需要将所有可能的状态和动作组合都列举出来,在计算方面是难以实现的。然而神经网络能够学习数据当中的模式和特征,还可以对新的状态进行有效的预测。所以 DeepMind 后来把自己的研究称作“深度强化学习”。
它能够应对更多的不确定环境。
但是 RL 经过神经网络加强之后,依然是 RL。Mu 的应用主要集中在有限的游戏环境当中。
AGI 要求 AI 能够应对各种各样的任务,而不是仅仅在某一个单一的任务里做到最好。
2021 年,AlphaGo 系列的负责人是 David Silver。他与 RL 奠基人萨顿携手,发表了另一篇文章,名为《Reward is Enough》。这篇文章与神经网络领域的划时代论文《Attention is all you need》在修辞方面有异曲同工之妙。
Silver 等人觉得,在“奖励最大化”这一简单而强大的原则之下,具有出色智能的 agent 能够“适者生存”,从而习得知识、学会学习、具备感知能力、拥有社交智能、掌握语言、具备泛化能力以及模仿能力。概括来说,RL 会推动 AGI 的实现。这就如同把自然界的进化论迁移到了 AI 领域。
这一理论遭遇了业界众多的质疑和批评。因为在某种程度上,它显得非常“空洞”。并且论文中所提到的泛化,在实践中依然难以取得突破进展。
强化学习是死胡同这类的讨论在 AI 社区越发频繁。围棋等游戏本身适合强化学习。然而在开放性环境里,奖励目标或者环境出现细微变化,就会致使整个系统完全失败,亦或是需要重新进行训练。监督学习的效果较为稳定,而强化学习根本就不稳定。人类设定的奖励,经过强化学习的黑盒子处理后,可能会引向无法预料的离谱行为。
去年,从 DeepMind 离职并开始创业的科学家 Misha Laskin 认为,RL 的进展仅仅停留在超人类且极度狭窄的智能体层面,然而却缺乏明确的路径去拓展其通用性。他提出疑问:“如果在单一任务上都需要实现六亿步的训练,那么究竟从哪里能够获取足够的数据来覆盖所有的任务呢?”
Google DeepMind 的研究员 Kimi Kong 近期于真格基金播客里表示,自 2019 年之后,在算法层面上,RL 就没有取得更多的显著进步了。
这种迷茫和低落在整个 RL 社区都有体现。尤其是 GPT 发布之后,LLM 所展现出的泛化能力,使得 RL 逐渐失去了资本和产业的关注。在一些人看来,RL 甚至被赶回了象牙塔。
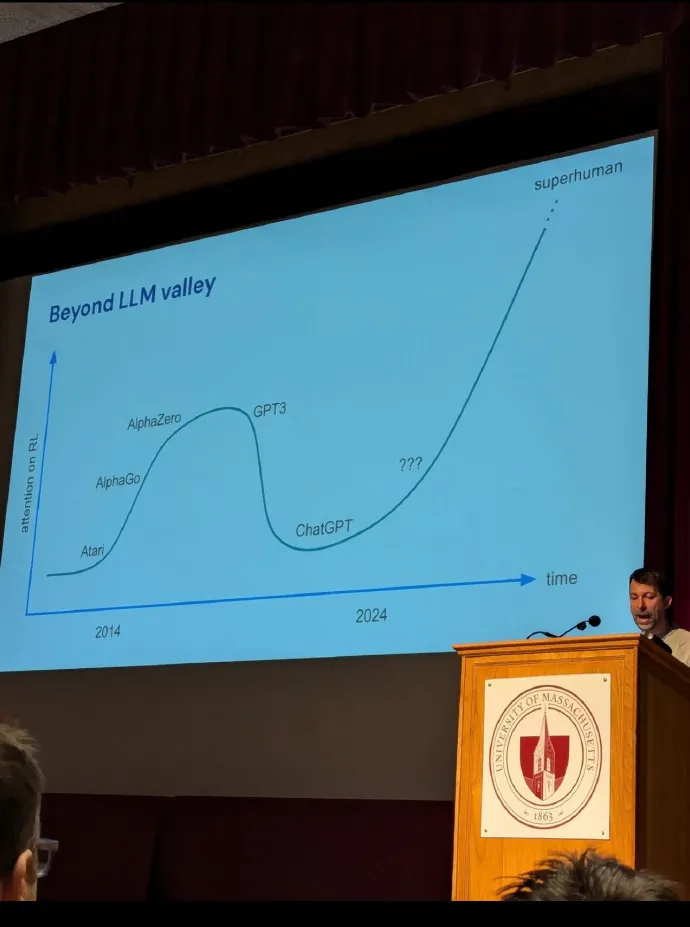
2024 年 8 月,有一场 DeepMind 的学校讲座。在 LLM 浪潮兴起的情况下,RL 受到的关注度跌入了低谷,然而 DeepMind 依然坚信 RL。
蛋糕上的樱桃
大语言模型如日中天,但它的头顶也飘着几朵乌云。
在 2024 年底的 AI 峰会 NeurIPS 上,OpenAI 的联合创始人以及前首席科学家 Ilya Sutskever 进行了宣称。他宣称预训练时代即将终结,也就是我们所熟知的预训练时代将结束。这一宣称彻底点破了已经笼罩在行业头顶的那种因 scaling law 碰壁而产生的焦虑。
AI 的训练数据正逐渐减少。并且,扩大训练数据的量级来提升智能的边际效应也在逐渐降低。

此外,LLM 本身不擅长数学和物理。因为 LLM 本质上是以语言模式为基础的,而科学原理以及人类的决策从根本上来说是较为抽象的,是超出了语言或像素的表达范畴的。
怎么办呢?
OpenAI 率先提出了方案。o1 模型是在去年年中发布的,它并非只是一味地扩大预训练规模,而是通过将 RL 与 CoT(思维链)技术相结合,实现了深度推理,从而将大模型的智能推向了一个新的高度。同时,一个新的范式也随之出现,即 AI 研究开始从“快思考”(快速给出预训练的答案)转变为“慢思考”(深思熟虑地推理)。
RL 的优点在这个时候充分展现出来。其一,RL 在特定的环境中,所需要的数据量比 LLM 要少很多。其二,RL 擅长在环境里自己去探索,能够动态地学习,还可以进行连续的决策。
RL 研究者、Pokee AI 的创始人 Zheqing Zhu 在演讲中提到,从 90 年代开始,RL 领域出现了一个趋势,那就是“反向的 scaling law”。AlphaGo 需要 3000 万对局,而到了 AlphaGo Zero 以及 MuZero 时,对局数量减少到 500 万以下,效率呈现出指数级的提升。
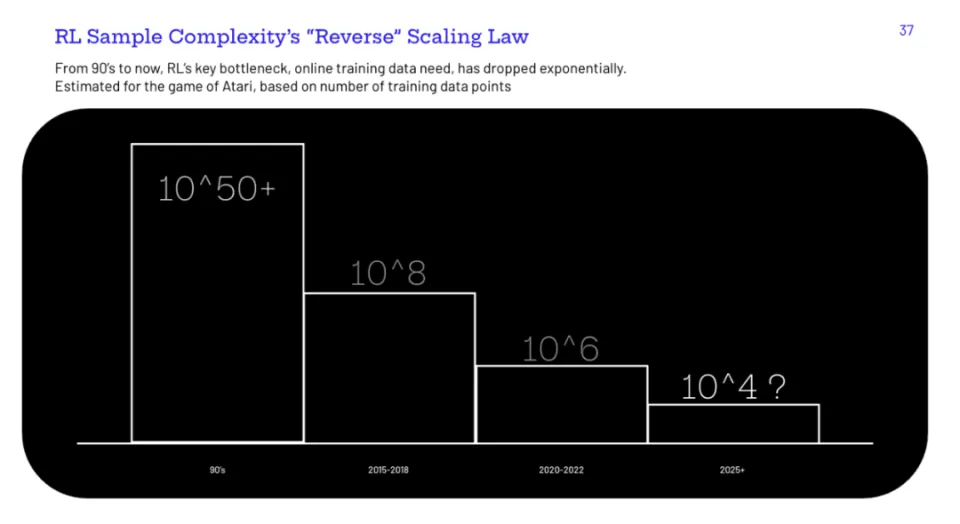
图片来自 @ZheqingZhu
有意思的是,OpenAI 实现了工程突破,同时谷歌提供了理论来源,就如同上次 GPT 点燃了 Transformer 的烽火一样。
在一个月前 o1 发布之前,DeepMind 的论文《Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters》与 o1 的模型原理几乎是一样的,该论文提出增加测试时的计算量比扩展模型参数更为有效。
谷歌在 2024 年初发布了一篇名为《Chain of Thought Empowers Transformers to Solve Inherently Serial Problems》的文章。该文章提出了类似的观点,即传统的 Transformer 模型擅长并行计算,而通过使用 CoT 能够突破其串行逻辑推理的限制。
但为何不是谷歌获得成果呢?这是另一个问题。或许与大厂的工作考核、组织模式、业务牵制等有关。谷歌的员工很可能也为此感到不满。
去年,DeepMind 的两位核心研究员,分别是 Misha Laskin 和 Ioannis Antonoglou。他们为了能够更快地追赶 AGI 的时间窗口,选择了离职。之后,他们创办了 Reflection AI 这家公司。其创业的方向正是基于 RL+LLMs 的通用 Agent。
很明显,整个大模型业界都迈入了新的、彼此心照不宣且硝烟弥漫的竞赛阶段。大家都看到了终点在哪里,然而后来者当中谁能够率先抵达呢?
答案是,来自纯中国本土团队的DeepSeek。
这里不再详细说明 DeepSeek 在其他方面的创新情况。若有兴趣,可以点开前文,了解从 DeepSeek 到字节,以及中国人所带来的真正价值。现在我们只关注它是如何实现“深度思考”的。
此前 OpenAI 展示了 o1 的推理能力,然而它有意将推理的详细过程隐藏起来,目的是防止其他模型复制它的数据。所以深度思考能力依然是一个黑盒,其他团队只能从一开始就进行研究。破解的难点一方面在于数据和基础模型,另一方面在于 RL 环境通常并不完美,并且难以准确地指定奖励函数。如果奖励机制存在噪声,那么就很容易出现 reward hacking 的情况,而在这种情况下,能力并没有真正得到提升。
LLM 们此前在进行 RLHF 时,这种现象较为普遍,并且还出现了越对模型进行训练,模型越变得笨拙的情况。
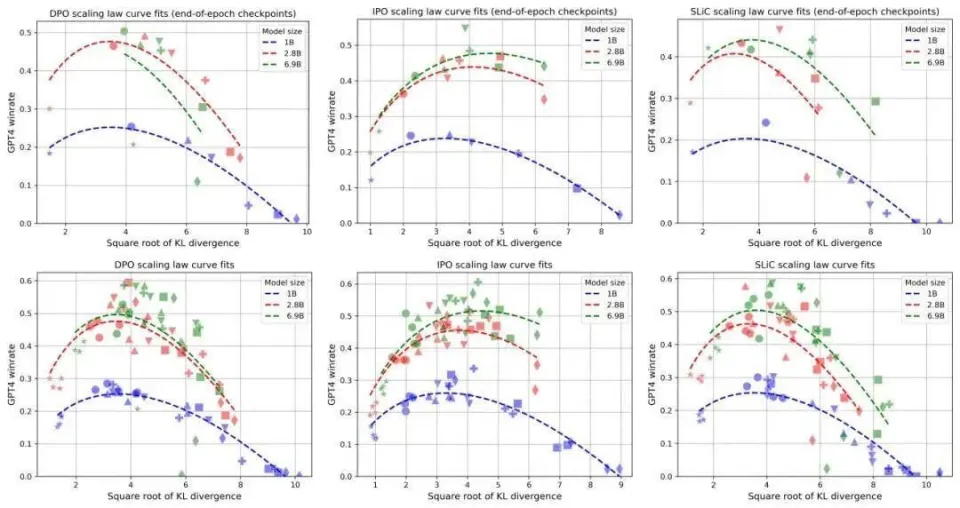
(不同的目标函数都存在过度优化,模型性能先升后降)
RLHF依赖于人类的反馈,它并非是一个明确且简洁的规则。RLHF 的很多部分,其目的是实现 alignment(对齐),是为了更像人,而非更智能。正因为这个原因,OpenAI 的联合创始人 Andrej Karpathy 认为,RLHF 并不是真正的 RL(强化学习),而只是人类偏好的代理,并非真正的奖励函数。
DeepSeek-R1-Zero将黑盒的秘密向所有人进行了公开。它提出了一种模型,这种模型能够完全跳过人类监督的微调,仅仅通过强化学习就获得了有效学习和泛化的能力。它的奖励函数十分不可思议地简单,只包含两部分。一部分是针对数学问题的“准确性奖励”,另一部分是规定思考过程要置于“”和“”标签之间的“格式奖励”。
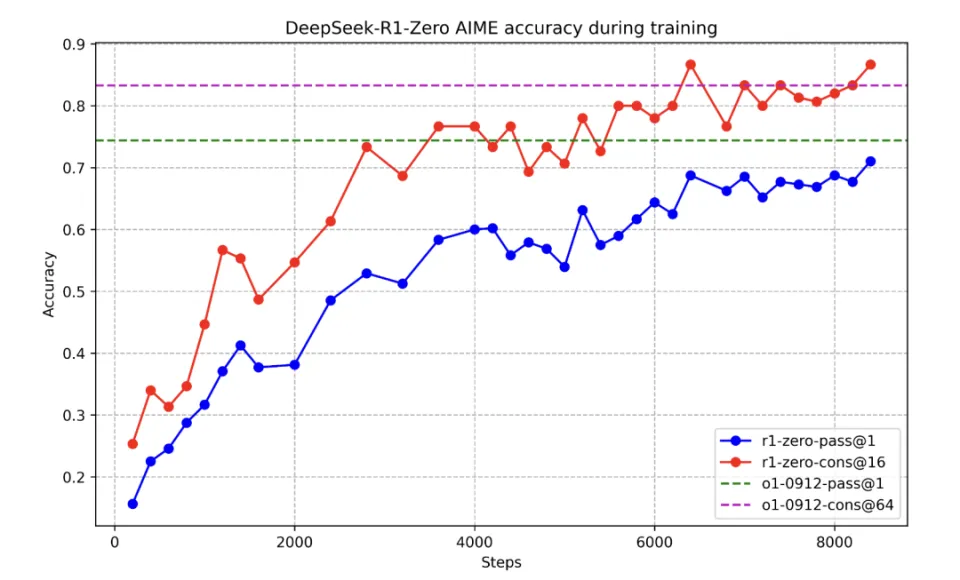
R1-Zero 在 AIME 2024 基准测试中,随着 RL 训练不断推进,其性能的稳定性得到增强,同时一致性也得到增强。
这种极简的奖励机制,回头去看,和 AlphaGo 极为相似。几年前被称作“空洞”的“Reward is Enough”观点,似乎有了一些得到验证的迹象:DeepSeek 制定出了合适的策略,找到了恰当的奖励函数,接着 R1-Zero 便获得了理性思考的能力,“顿悟时刻”也就出现了。
拥有通用知识的 LLM 插上了擅长抽象逻辑、自主推理决策的 RL 翅膀,两者相互补充,AI 的智能程度得到了显著提高,这简直是目前最为完美的解决方案。
还记得 2016 年杨乐昆提出的那个著名的蛋糕梗吗?他说如果智能像一块蛋糕,那么无监督学习就是蛋糕的主要部分,监督学习如同糖霜,强化学习(RL)就像是顶上的那颗樱桃。
他的本意是要强调无监督学习的重要性,后来这种学习变成了自监督学习。这种学习是从可用的任意信息去预测过去、现在或未来的情况,同时还顺便讽刺了一下 RL。这也是连接主义的学者经常会做出的嘲笑 RL 的习惯性动作。

DeepMind 的研究人员受到了刺激,他们曾经回敬了他一张蛋糕图,那蛋糕图上缀满了樱桃。
不过,这个讽刺意味的meme,反而成了当下情形的正面预言。
OpenAI Deep Research 的研究员 Josh Tobin 对这个趋势进行了很好的描述。在 2015 年和 2016 年进行 RL 研究时,进展受到了限制,那时候是在没有“蛋糕”的情况下添加“樱桃”。然而现在,我们拥有了在大量数据上预训练的强大语言模型,RL 终于迎来了合适的发展时机,AGI Agent 和复杂决策也变得更加高效和可行。
奥特曼称未来发布的 GPT - 5 会是两条线合并而成的“神奇的统一智能”,它会依据任务来决定是快速给出答案,还是进行深入的分析思考。
Ilya Sutskever 曾提出一个比喻,大多数哺乳动物的大脑体重比有其特定规律。然而,人类进化出了新的路径,使得大脑比重更大。AI 也将会找到突破预训练模式的新方向。
DeepSeek 预告表明,RL 提升大模型智能的潜力还远未被完全挖掘。下一波 AI 突破已然拉开序幕。
《我们最终能用上Manus吗》
《当店播成为新常态,下一步会是什么?》
《你可能用了假的DeepSeek》
本文采摘于网络,不代表本站立场,转载联系作者并注明出处:http://mjgaz.cn/fenxiang/274966.html
